Ogni compito ha bisogno del suo modello
Lo stesso workflow Jira può sembrare preciso o stranamente approssimativo a seconda del modello che opera dietro ogni fase. Quello che conta qui non è chi vince i benchmark, ma perché certi provider continuano a guadagnarsi gli stessi ruoli all'interno di un prodotto reale.

Perché questo non è un articolo sui benchmark
Questo non è una classifica. All'interno di Just, la domanda utile non è quale modello sembri più intelligente in astratto. È quale rende ogni fase del workflow più pulita, più stabile e più affidabile.
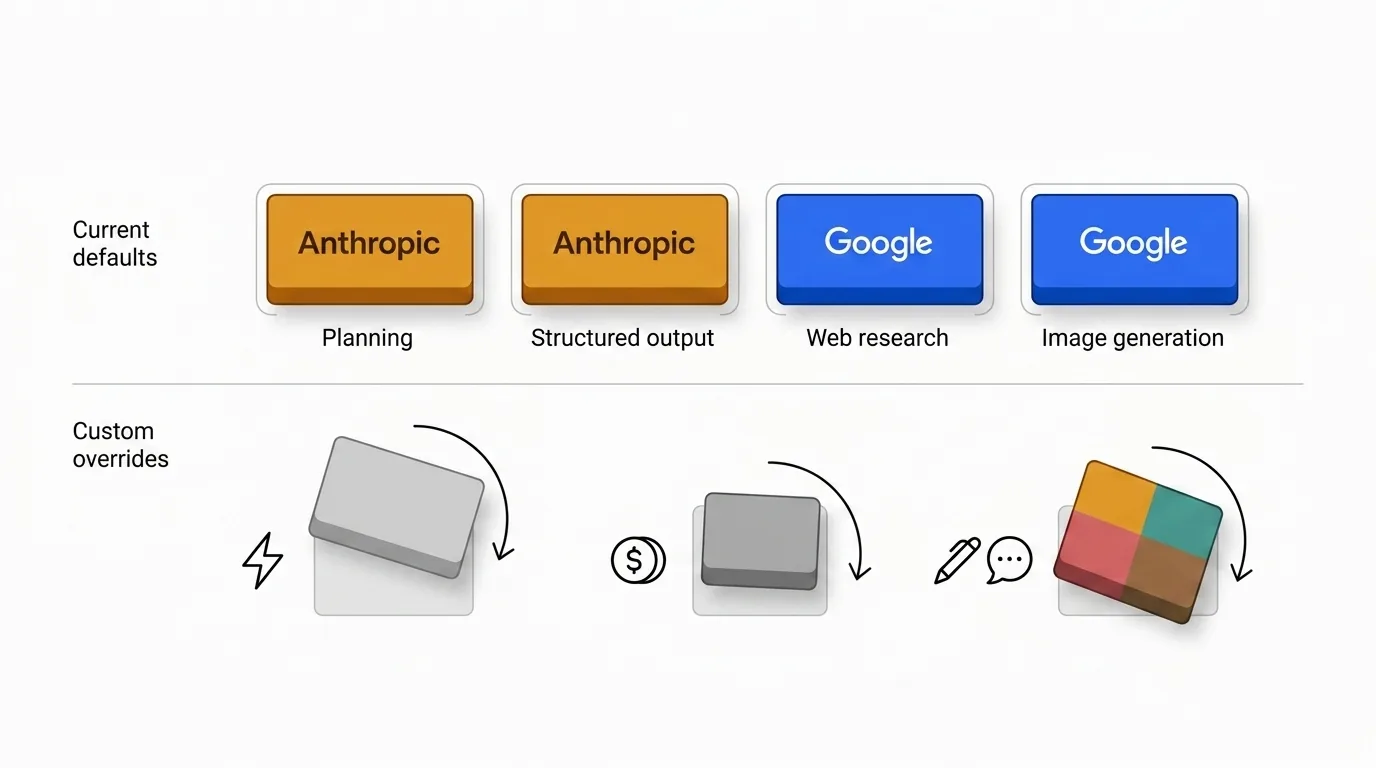
Per questo i valori predefiniti sono deliberatamente disomogenei. Alcuni provider continuano a guadagnarsi il nucleo di pianificazione, mentre altri hanno più senso quando contano di più la freschezza, la qualità della ricerca o l'output multimodale.
Se vuoi vedere come appare quella logica una volta cablata nel prodotto, Just 2.0: Insights, ricerca web, immagini e contesto condiviso percorre il workflow attuale in pratica.
Per la mappa completa delle capacità, la matrice AI nella home page mostra cosa supporta ogni provider per ogni funzionalità. La versione sotto è la vista più breve, delle dimensioni di un articolo.
| Funzione | |||||
|---|---|---|---|---|---|
| Risposta testuale | |||||
| Risposta con ragionamento | |||||
| Output strutturato | |||||
| Generazione di immagini | |||||
| Ricerca web |
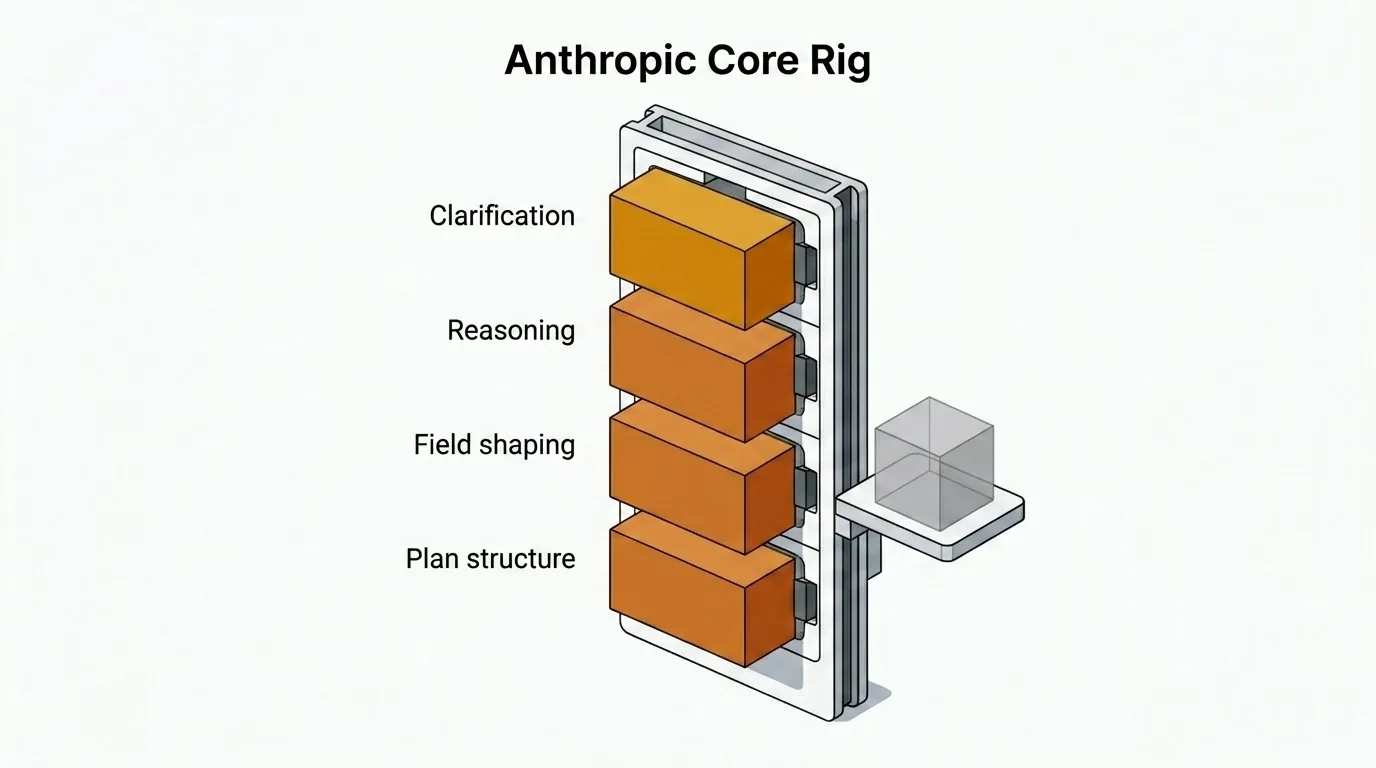
Perché Anthropic domina il nucleo
Il nucleo di Just — domande di chiarimento, piani strutturati, configurazione dei campi delle issue e risposte ad alto contenuto di ragionamento — gira su Anthropic per impostazione predefinita. Quella scelta è deliberata e comporta un compromesso che ho accettato.
| Fase | Modello | Qualità | Velocità | Prezzo |
|---|---|---|---|---|
| Risposte testuali | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Aggiornamenti dei campi e configurazione delle issue | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Risposte ragionate | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Piani strutturati e specifiche | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Generazione iniziale di insight | Claude Sonnet 4.5 | 💡💡💡 | ⚡⚡⚡ | 💲💲💲 |
| Compattazione finale | Claude Haiku 4.5 | 💡💡 | ⚡⚡⚡⚡ | 💲 |
Dalla mia esperienza, i modelli Anthropic sono circa 2× più costosi e 1,5× più lenti rispetto alle alternative più vicine per lavori simili. Li uso comunque come predefiniti perché l'output è migliore negli aspetti che contano per la pianificazione.
La differenza non è nella creatività. È nella concisione, nell'aderenza alle istruzioni, nella stabilità del ragionamento e in un output strutturato più pulito. Claude Opus 4.6 segue vincoli dettagliati in modo più affidabile, pone meno domande di chiarimento inutili e necessita di meno passaggi di correzione quando il workflow si aspetta piani strutturati.
Il compromesso è reale, ma in un workflow di pianificazione preferisco pagare di più per un primo passaggio pulito piuttosto che risparmiare su output che richiedono poi correzioni.
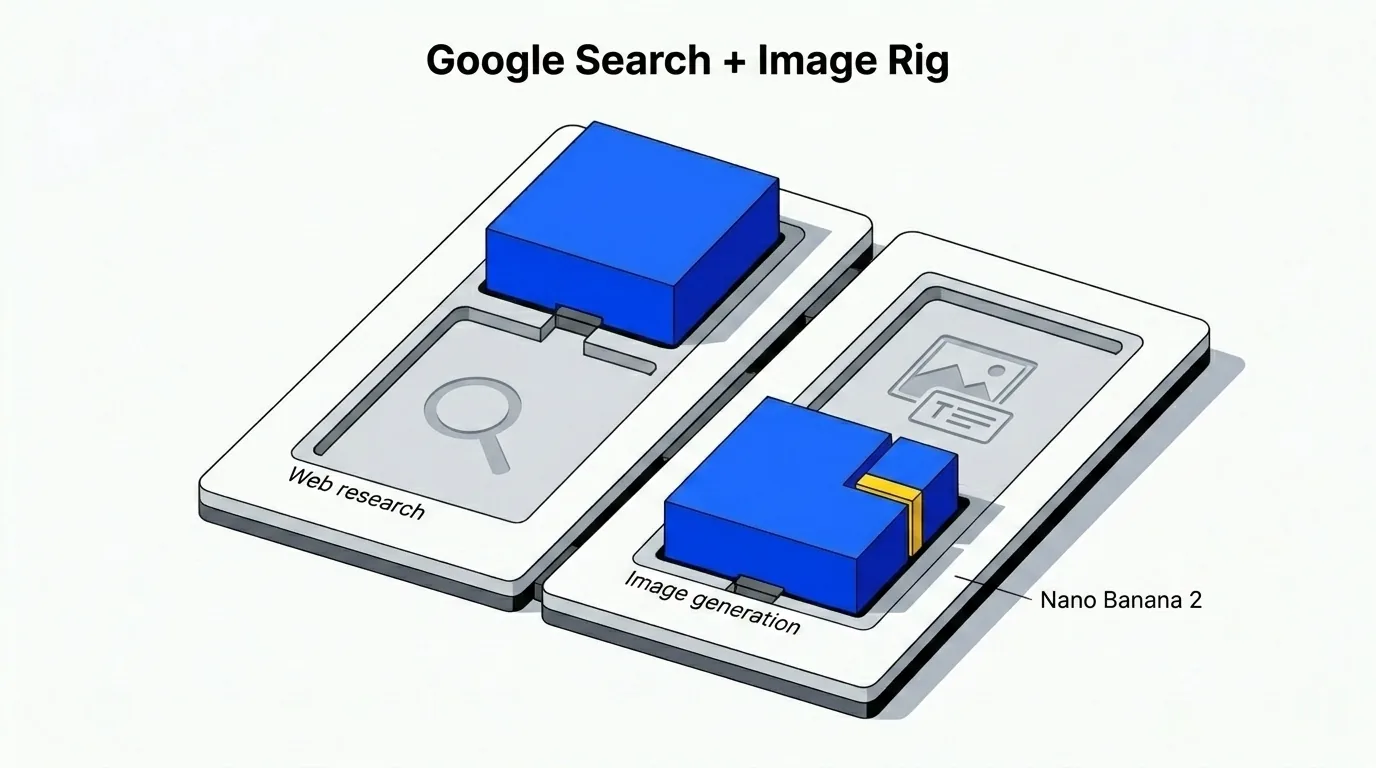
Perché Google domina ricerca e generazione di immagini
Quando il workflow ha bisogno di contesto web aggiornato — analisi competitiva, ricerche di documentazione tecnica e dati di mercato — la scelta predefinita si sposta su Google. Nello specifico, Gemini 3.0 Pro per la ricerca web.
Non si tratta solo di spuntare una casella di capacità. Google ha trascorso decenni a risolvere ranking, rilevanza, freschezza e qualità delle fonti su scala internet. Questo conta quando i risultati ancorati al web alimentano direttamente la pianificazione a valle. Se la fase di ricerca produce fonti obsolete o citazioni allucinatorie, il piano costruito sopra di esse eredita quei problemi.
Il lato immagini segue la stessa logica. Il predefinito attuale è Gemini 3.1 Flash Image Preview — noto pubblicamente come Nano Banana 2. Gestisce immagini con testo incorporato in modo più consistente rispetto alla maggior parte delle alternative che ho testato: le etichette rimangono leggibili, il layout regge e il posizionamento del testo segue il prompt invece di deviare.
Dove si inseriscono OpenAI, xAI e Mistral
- OpenAI è l'ovvio tuttofare: capace in testo, ragionamento, output strutturato, ricerca web e generazione di immagini. Paradossalmente, è proprio questa ampiezza una delle ragioni per cui non è il predefinito per il nucleo di pianificazione. Quando un provider è forte in tutto, spesso finisci per accettare un risultato abbastanza buono ovunque invece del migliore là dove conta di più. Come fallback unico è comunque difficile da battere, e rimane la scelta più pratica per i team che preferiscono gestire una sola chiave API piuttosto che uno stack misto.
- xAI è maturato più rapidamente di quanto mi aspettassi. Grok ora supporta output strutturato completo con aderenza garantita agli schemi, e la sua integrazione di ricerca web è solida. Dove si inserisce più naturalmente è nel lavoro sensibile alla velocità — ideazione precoce, ricerche rapide e bozze esplorative dove il tempo di risposta conta più della rifinitura.
- Mistral si adatta a compiti testuali leggeri e ad alto volume dove l'efficienza dei costi è il vincolo primario. È anche la scelta più naturale per i team con requisiti di residenza dei dati nell'UE o una preferenza per uno stack di provider europeo.
Quando scegliere altri modelli
I valori predefiniti riflettono il mio giudizio, non una legge universale. Ci sono buone ragioni per sovrascriverli.
- I team sensibili ai costi potrebbero decidere che il moltiplicatore di Anthropic non vale il loro volume.
- I team sensibili alla velocità potrebbero preferire modelli più leggeri per il triage o l'ideazione.
- Alcune organizzazioni vogliono un unico provider per motivi di coerenza del tono, governance o procurement.
Se non vuoi gestire più chiavi API e provider, usare solo OpenAI per tutto è un'opzione perfettamente sensata. Ultimamente trovo anche Google Gemini sempre più competitivo come fallback generale — entrambi vale la pena testarli sulle proprie attività prima di impegnarsi in uno stack.
Predefiniti attuali, non verità eterna
Il mapping qui riflette come penso alle forze dei provider oggi. Anthropic domina il nucleo perché i suoi modelli producono attualmente il miglior output di qualità per la pianificazione per i compromessi che sono disposto ad accettare. Google domina ricerca e lavoro sulle immagini perché i suoi punti di forza infrastrutturali si allineano naturalmente con questi compiti.
Questi predefiniti evolveranno man mano che i modelli, i prezzi e i compromessi cambieranno. Quello che dovrebbe rimanere stabile è la logica sottostante: abbinare il provider al profilo del compito, non a un singolo ranking.
Se stai configurando il tuo stack di provider per la prima volta, inizia con i predefiniti, fai passare alcune issue reali attraverso il workflow completo e poi sovrascrivi dove le priorità del tuo team ti indicano una direzione diversa. L'obiettivo non è il modello teoricamente migliore — è lo stack che rende le tue issue Jira migliori, più veloci e con meno attrito.