Jede Aufgabe braucht ihr eigenes Modell
Derselbe Jira-Workflow kann sich scharf oder seltsam unrund anfühlen, je nachdem welches Modell hinter jedem Schritt steckt. Entscheidend ist nicht, wer Benchmarks gewinnt, sondern warum bestimmte Anbieter in einem echten Produkt immer wieder dieselben Aufgaben erhalten.

Warum dies kein Benchmark-Artikel ist
Dies ist keine Rangliste. In Just lautet die sinnvolle Frage nicht, welches Modell abstrakt am klügsten wirkt. Sondern welches jeden Workflow-Schritt sauberer, gleichmäßiger und verlässlicher macht.
Deshalb sind die Standardwerte hier bewusst ungleichmäßig. Einige Anbieter erhalten immer wieder den Planungskern, während andere mehr Sinn ergeben, wenn Aktualität, Suchqualität oder multimodale Ausgabe wichtiger sind.
Wenn du sehen möchtest, wie diese Logik im Produkt aussieht, erklärt Just 2.0: Insights, Websuche, Bilder und gemeinsamer Kontext den aktuellen Workflow in der Praxis.
Für die vollständige Fähigkeitskarte zeigt die KI-Matrix auf der Startseite, was jeder Anbieter über alle Funktionen hinweg unterstützt. Die Version unten ist die kürzere, artikelgerechte Ansicht.
| Funktion | |||||
|---|---|---|---|---|---|
| Textantwort | |||||
| Antwort mit Begründung | |||||
| Strukturierte Ausgabe | |||||
| Bildgenerierung | |||||
| Websuche |
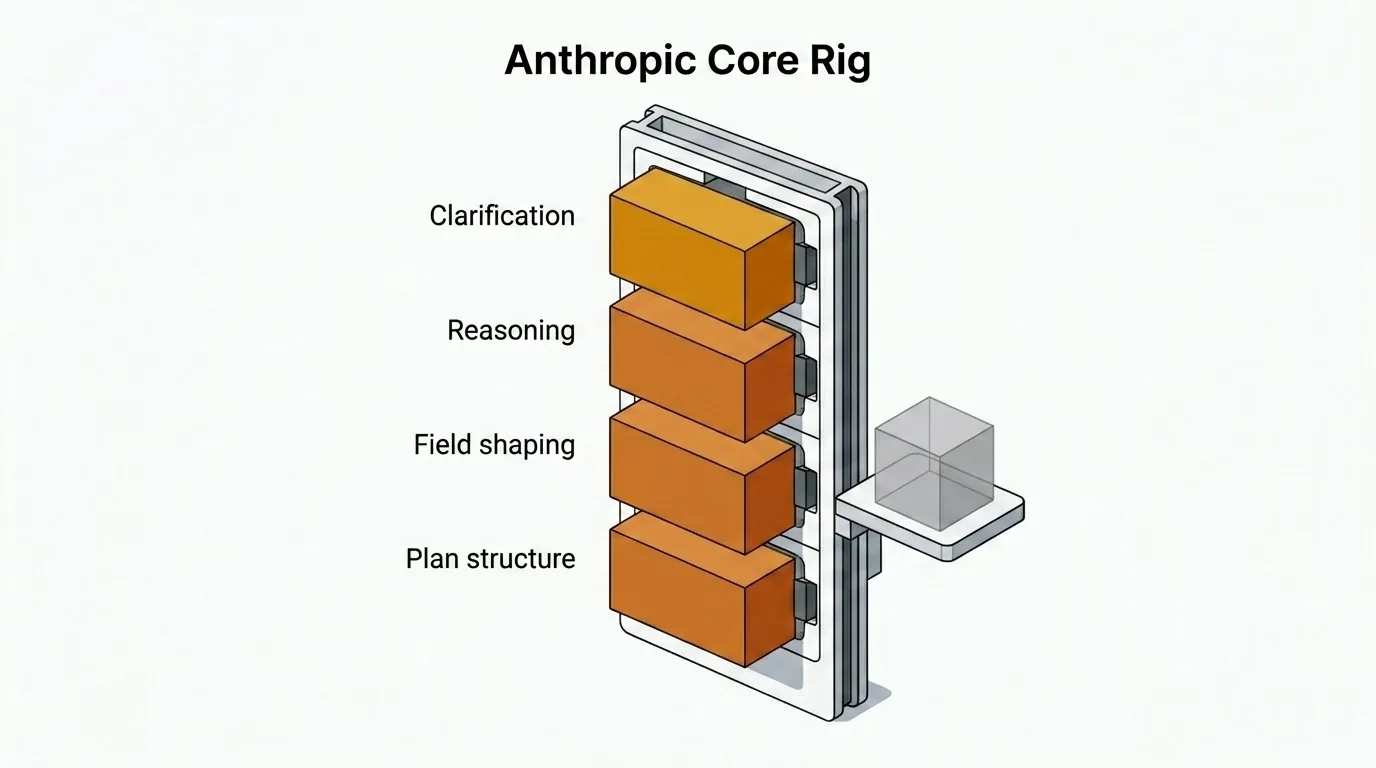
Warum Anthropic den Kern hält
Der Kern von Just — Klärungsfragen, strukturierte Pläne, Issue-Feld-Gestaltung und begründungsintensive Antworten — läuft standardmäßig auf Anthropic. Diese Entscheidung ist bewusst, und sie hat einen Kompromiss, den ich akzeptiert habe.
| Schritt | Modell | Qualität | Geschwindigkeit | Preis |
|---|---|---|---|---|
| Textantworten | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Feldaktualisierungen und Issue-Gestaltung | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Begründete Antworten | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Strukturierte Pläne und Spezifikationen | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Erste Insight-Generierung | Claude Sonnet 4.5 | 💡💡💡 | ⚡⚡⚡ | 💲💲💲 |
| Finale kompakte Formgebung | Claude Haiku 4.5 | 💡💡 | ⚡⚡⚡⚡ | 💲 |
Nach meiner Erfahrung sind Anthropic-Modelle für ähnliche Arbeit etwa 2× teurer und 1,5× langsamer als die nächstbesten Alternativen. Ich setze sie trotzdem als Standard, weil die Ausgabe in den für Planung entscheidenden Bereichen besser ist.
Der Unterschied liegt nicht in der Kreativität. Es geht um Prägnanz, Instruktionstreue, Begründungsstabilität und sauberere strukturierte Ausgabe. Claude Opus 4.6 hält detaillierte Einschränkungen zuverlässiger ein, stellt weniger unnötige Rückfragen und braucht weniger Korrekturdurchläufe, wenn der Workflow strukturierte Pläne erwartet.
Der Kompromiss ist real, aber in einem Planungsworkflow zahle ich lieber mehr für einen sauberen ersten Entwurf, als bei Ausgaben zu sparen, die danach Korrekturen brauchen.
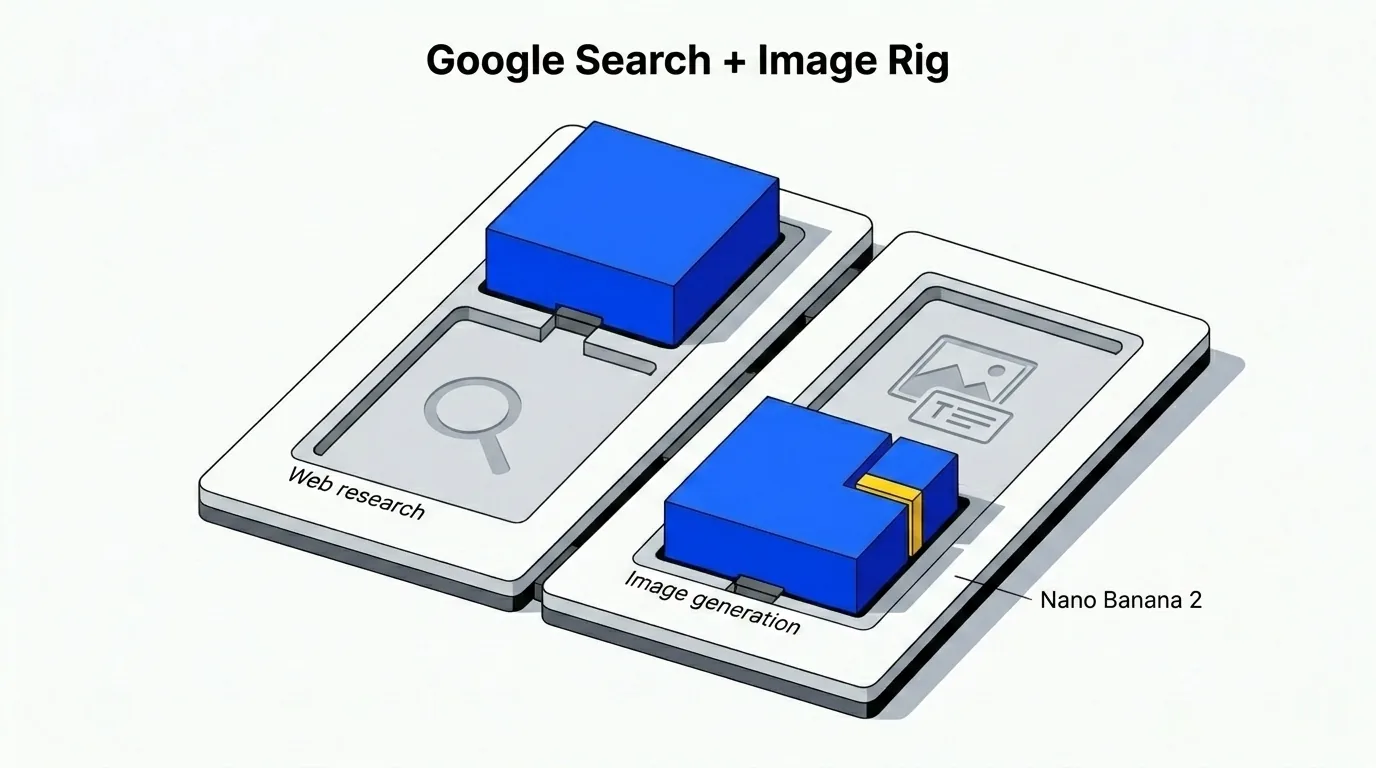
Warum Google Suche und Bildgenerierung hält
Wenn der Workflow frischen Web-Kontext braucht — Wettbewerbsanalyse, technische Dokumentationssuche, Marktdaten — verschiebt sich die Standardwahl zu Google. Konkret zu Gemini 3.0 Pro für Webrecherche.
Das ist nicht nur ein Fähigkeits-Häkchen. Google hat jahrzehntelang Ranking, Relevanz, Aktualität und Quellqualität im Internetmaßstab gelöst. Das spielt eine Rolle, wenn webbasierte Ergebnisse direkt in die nachgelagerte Planung einfließen. Wenn der Suchschritt veraltete Quellen oder halluzinierte Zitate liefert, erbt der darauf aufgebaute Plan diese Probleme.
Die Bildseite folgt derselben Logik. Der aktuelle Standard ist Gemini 3.1 Flash Image Preview — öffentlich bekannt als Nano Banana 2. Er verarbeitet Bilder mit eingebettetem Text konsistenter als die meisten Alternativen, die ich getestet habe: Beschriftungen bleiben lesbar, das Layout hält, und die Textplatzierung folgt dem Prompt statt abzudriften.
Wo OpenAI, xAI und Mistral passen
- OpenAI ist der offensichtliche Allrounder: leistungsfähig bei Text, Reasoning, strukturierter Ausgabe, Websuche und Bildgenerierung. Paradoxerweise ist genau diese Breite ein Grund, warum es nicht der Standard für den Planungskern ist. Wenn ein Anbieter in allem stark ist, akzeptiert man oft überall ein „gut genug" statt an den entscheidenden Stellen das Beste. Als einzelner Fallback ist er trotzdem schwer zu schlagen und bleibt die praktischste Wahl für Teams, die lieber einen API-Schlüssel verwalten als einen gemischten Stack.
- xAI hat sich schneller weiterentwickelt als ich erwartet hatte. Grok unterstützt jetzt vollständige strukturierte Ausgabe mit garantierter Schema-Einhaltung, und seine Websuch-Integration ist solide. Am natürlichsten passt es zu geschwindigkeitssensiblen Arbeiten — frühe Ideenfindung, schnelle Nachschlagevorgänge und explorative Entwürfe, bei denen Durchlaufzeit wichtiger ist als Politur.
- Mistral eignet sich für leichte, hochvolumige Textaufgaben, bei denen Kosteneffizienz die primäre Einschränkung ist. Es ist auch die naheliegendste Wahl für Teams mit EU-Datenspeicherungsanforderungen oder einer Präferenz für einen europäischen Anbieter-Stack.
Wann andere Modelle die bessere Wahl sind
Die Standardwerte spiegeln mein Urteil wider, kein universelles Gesetz. Es gibt gute Gründe, sie zu überschreiben.
- Kostensensible Teams entscheiden möglicherweise, dass der Anthropic-Multiplikator bei ihrem Volumen nicht lohnt.
- Geschwindigkeitssensible Teams bevorzugen möglicherweise leichtere Modelle für Triage oder Ideenfindung.
- Manche Organisationen möchten einen einzigen Anbieter aus Gründen der Tonkonsistenz, Governance oder Beschaffung.
Wenn du mehrere API-Schlüssel und Anbieter nicht verwalten möchtest, ist es völlig vernünftig, alles über OpenAI abzuwickeln. In letzter Zeit finde ich auch Google Gemini als allgemeinen Fallback zunehmend wettbewerbsfähig — beide sind es wert, an deinen eigenen Aufgaben getestet zu werden, bevor du dich festlegst.
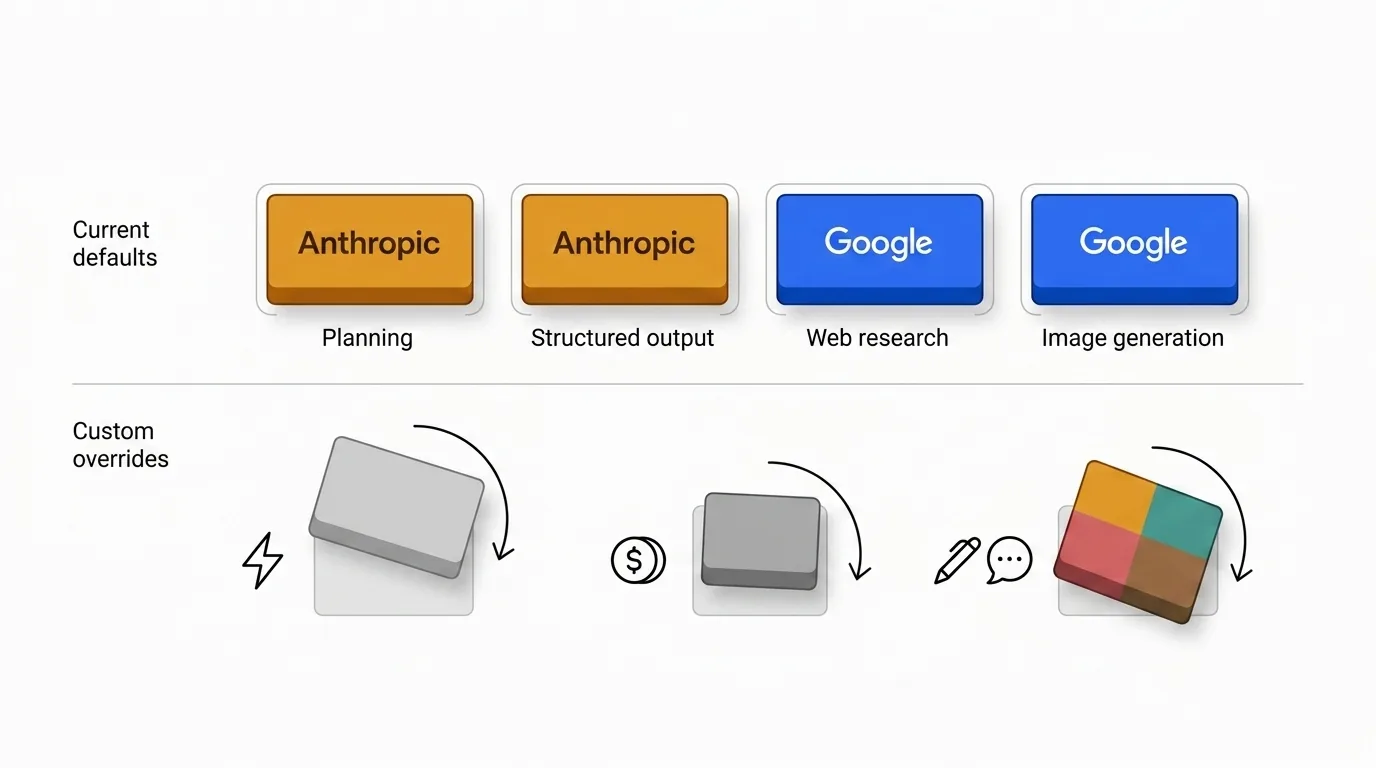
Aktuelle Standards, keine ewige Wahrheit
Die Zuordnung hier spiegelt wider, wie ich heute über Anbieterstärken denke. Anthropic hält den Kern, weil seine Modelle derzeit die beste Planungsqualität für die Kompromisse liefern, die ich bereit bin einzugehen. Google hält Suche und Bildarbeit, weil seine Infrastrukturstärken natürlich zu diesen Aufgaben passen.
Diese Standards werden sich verändern, wenn Modelle, Preise und Kompromisse sich verschieben. Was stabil bleiben sollte, ist die zugrunde liegende Logik: den Anbieter auf das Aufgabenprofil abstimmen, nicht auf eine einzelne Rangliste.
Wenn du deinen Anbieter-Stack zum ersten Mal einrichtest, beginne mit den Standards, lass einige echte Issues durch den vollständigen Workflow laufen und überschreibe dann dort, wo die Prioritäten deines Teams dich in eine andere Richtung weisen. Das Ziel ist nicht das theoretisch beste Modell — es ist der Stack, der deine Jira-Issues besser, schneller und mit weniger Reibung macht.