每项任务都需要专属模型
同样的 Jira 工作流,背后的模型不同,感受可能天差地别——精准流畅或奇怪别扭。重要的不是谁在基准测试中获胜,而是为什么某些服务商在真实产品中能持续赢得相同的岗位。

为什么这不是一篇基准测试文章
这里没有排行榜。在 Just 中,真正有意义的问题不是哪个模型在抽象层面看起来最聪明,而是哪个模型能让工作流的每一步更干净、更稳定、更值得信赖。
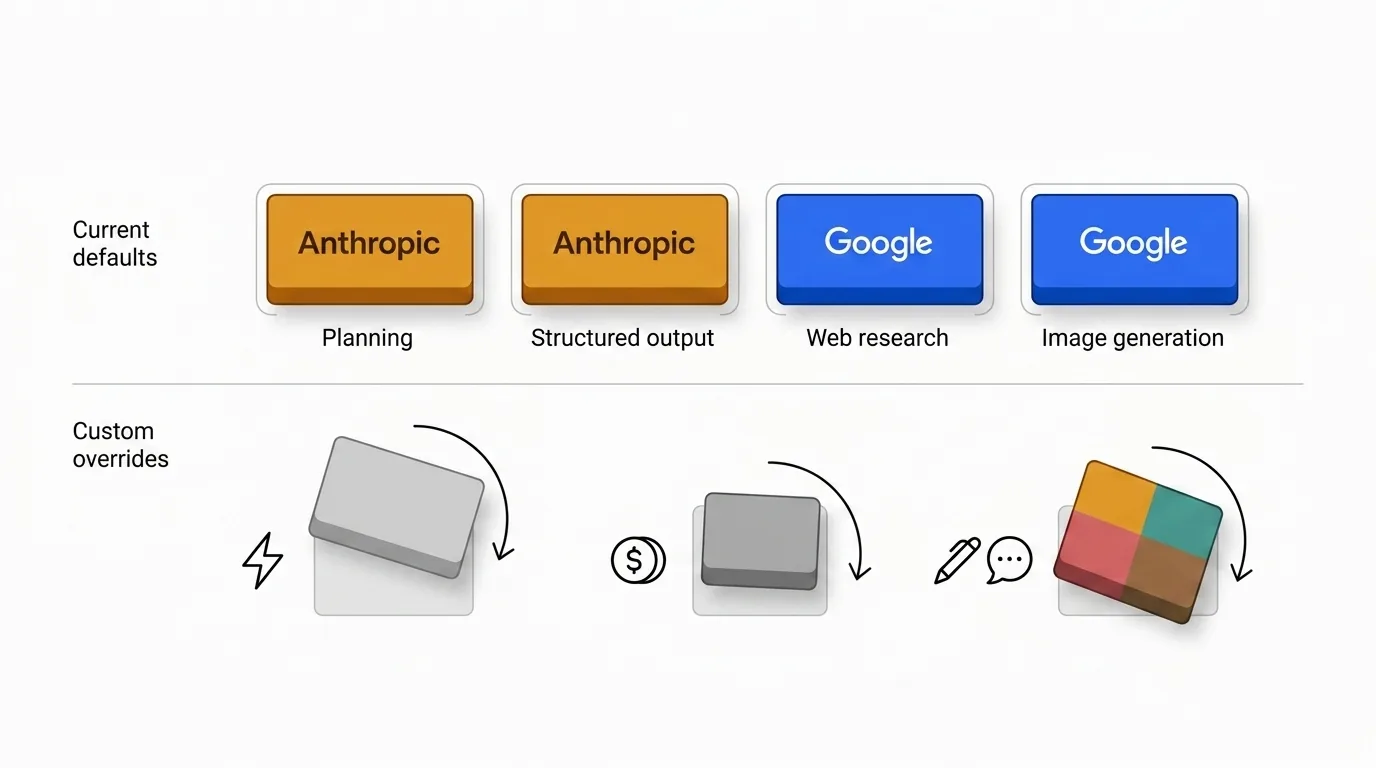
这就是为什么默认配置是有意不均衡的。有些服务商不断赢得规划核心,而另一些在信息时效性、搜索质量或多模态输出更重要时更能发挥作用。
如果你想看这套逻辑在产品中的实际呈现,Just 2.0:洞察、网络搜索、图像与共享上下文 详细介绍了当前的工作流实践。
完整的能力地图可以在落地页的 AI 矩阵查看,展示了每个服务商在每项功能上的支持情况。以下版本是文章篇幅内的精简视图。
| 能力 | |||||
|---|---|---|---|---|---|
| 文本回复 | |||||
| 带推理的回答 | |||||
| 结构化输出 | |||||
| 图片生成 | |||||
| 网页搜索 |
为什么 Anthropic 主导核心
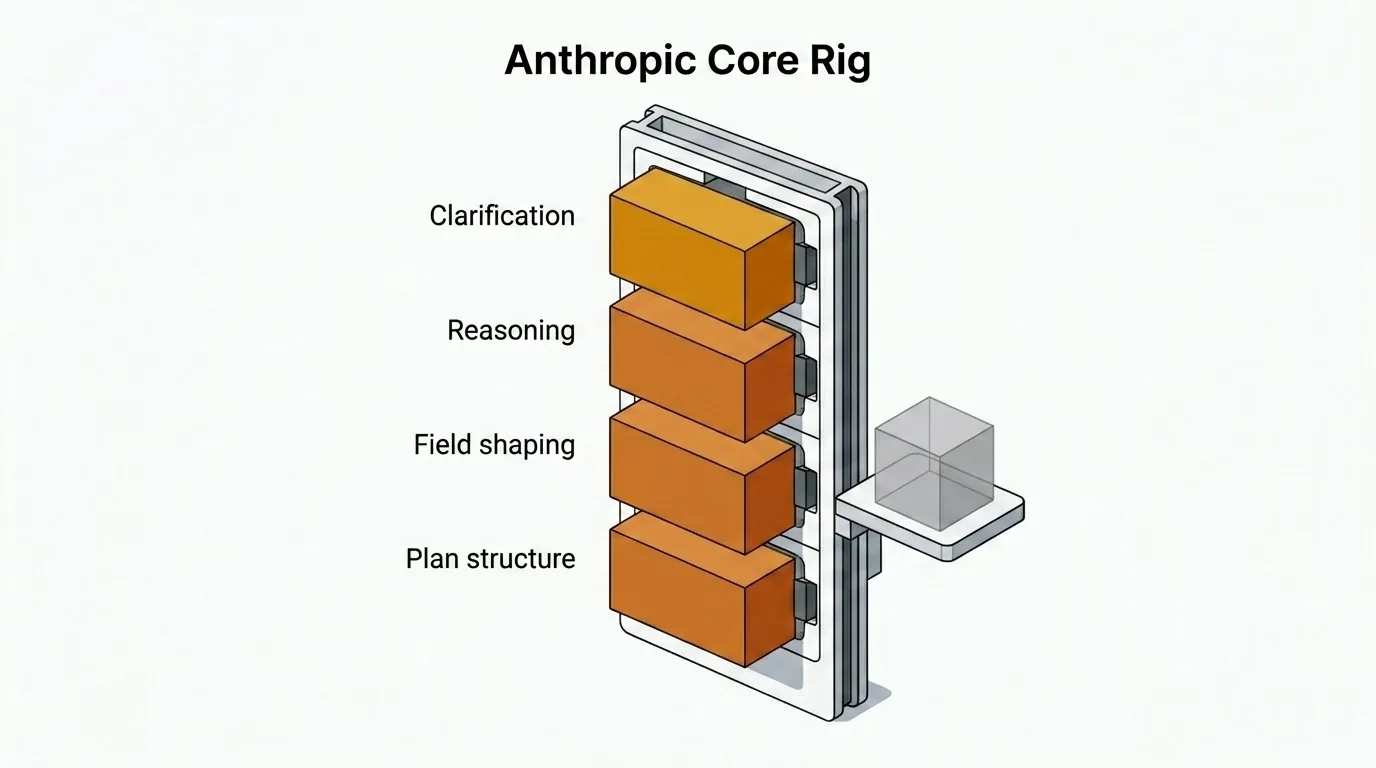
Just 的核心——澄清问题、结构化计划、issue 字段整形,以及需要复杂推理的回答——默认运行在 Anthropic 上。这是一个经过深思熟虑的选择,伴随着我已接受的权衡。
| 步骤 | 模型 | 质量 | 速度 | 价格 |
|---|---|---|---|---|
| 文本回答 | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| 字段更新与 issue 整形 | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| 推理性回答 | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| 结构化计划与规格 | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| 初始洞察生成 | Claude Sonnet 4.5 | 💡💡💡 | ⚡⚡⚡ | 💲💲💲 |
| 最终紧凑整形 | Claude Haiku 4.5 | 💡💡 | ⚡⚡⚡⚡ | 💲 |
根据我的经验,Anthropic 模型完成类似工作的成本约是最接近替代方案的 2 倍,速度约慢 1.5 倍。但我仍然默认使用它们,因为在规划中真正重要的维度上,输出质量更好。
差异不在于创造力,而在于简洁性、指令遵循、推理稳定性,以及更干净的结构化输出。Claude Opus 4.6 更可靠地遵守详细约束,提出不必要澄清问题的频率更低,在工作流期待结构化计划时需要的修正次数也更少。
这个权衡是真实存在的,但在规划工作流中,我宁愿为干净的第一遍多付钱,也不愿为需要事后修正的输出省钱。
为什么 Google 主导搜索和图像生成
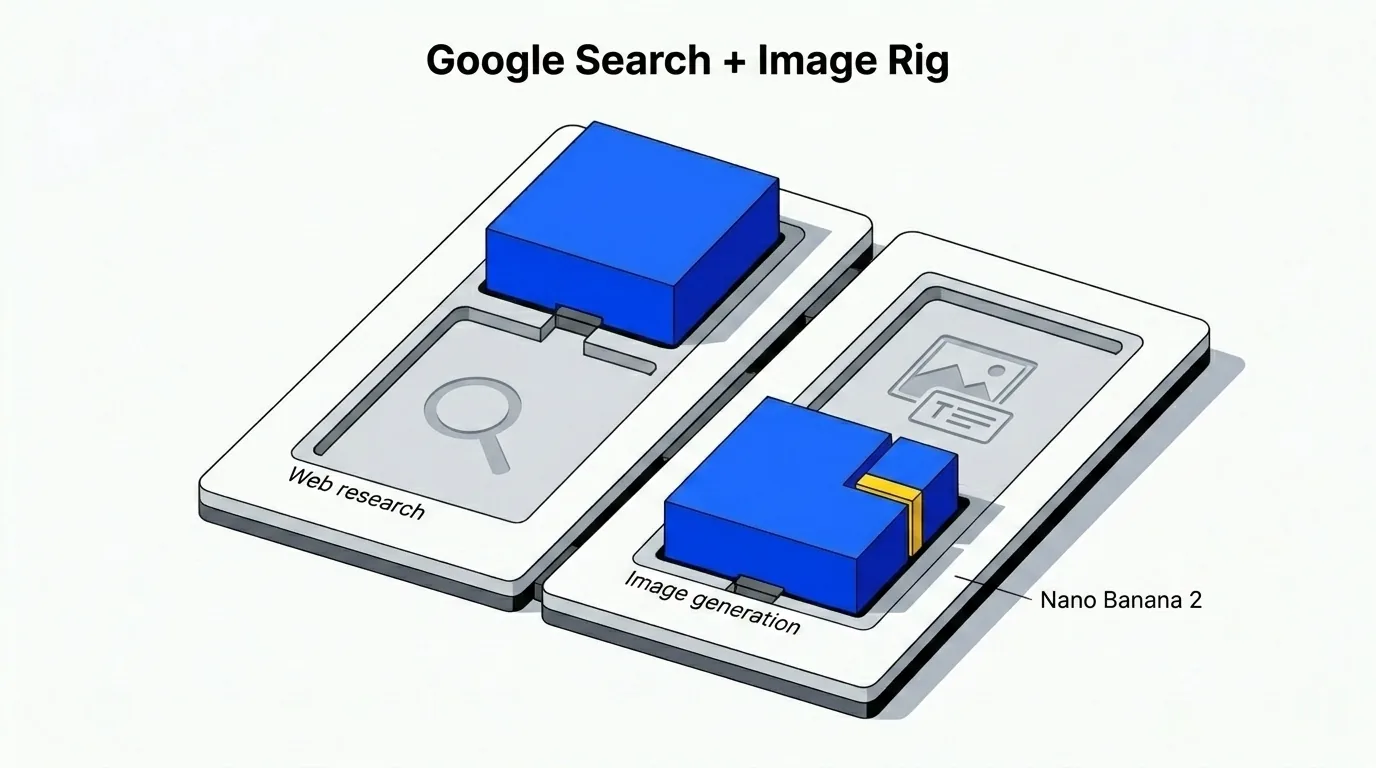
当工作流需要最新的网络上下文——竞品分析、技术文档查询和市场数据——默认选择会切换到 Google。具体来说,网络搜索使用 Gemini 3.0 Pro。
这不只是能力清单上的一个勾选项。Google 花了数十年在互联网规模上解决排名、相关性、时效性和来源质量的问题。当基于网络的结果直接进入下游规划时,这一点至关重要。如果搜索步骤拉取了过时的来源或幻觉引用,基于此构建的计划就会继承这些问题。
图像方面遵循同样的逻辑。当前默认是 Gemini 3.1 Flash Image Preview——公开名称为 Nano Banana 2。在处理包含嵌入文字的图像方面,它比我测试过的大多数替代方案更稳定:标签保持清晰可读,布局不会散乱,文字位置遵循提示词而不会漂移。
OpenAI、xAI 和 Mistral 各有何定位
- OpenAI 是最显而易见的全能选手:在文本、推理、结构化输出、网络搜索和图像生成方面都很出色。矛盾的是,正是这种广度让它不成为规划核心的默认选项。当一个服务商在所有方面都很强时,你往往会在每个地方接受"足够好",而不是在最重要的地方获得最佳结果。作为单一服务商的备用方案它仍然难以超越,对于不想管理多个 API 密钥的团队来说依然是最实用的选择。
- xAI 的成熟速度超出了我的预期。Grok 现在支持带有模式保证的完整结构化输出,网络搜索集成也相当稳固。它最自然地适合速度敏感型工作——早期创意发散、快速查找和探索性草稿,这些场景中周转时间比打磨质量更重要。
- Mistral 适合轻量级、高频次的文本任务,在这些场景中成本效率是首要约束。对于有欧盟数据本地化要求或偏好欧洲服务商技术栈的团队,它也是最自然的选择。
什么时候该选择其他模型
默认配置反映的是我的判断,不是普遍法则。有很好的理由去覆盖它们。
- 成本敏感的团队可能会认为 Anthropic 的价格倍数在其使用量下不值得。
- 速度敏感的团队可能更倾向于为分类或创意发散使用更轻量的模型。
- 一些组织因为语气一致性、合规治理或采购原因,希望只用一个服务商。
如果不想管理多个 API 密钥和服务商,只用 OpenAI 处理所有事情是完全合理的选择。最近我也发现 Google Gemini 作为通用备用方案的竞争力越来越强——在确定技术栈之前,两者都值得用自己的任务测试一番。
当前默认,不是永恒真理
这里的映射反映了我今天对服务商优势的理解。Anthropic 主导核心,因为它的模型目前在我愿意接受的权衡下产出最好的规划质量。Google 主导搜索和图像工作,因为 Google 的基础设施优势与这些任务天然契合。
随着模型、定价和权衡条件的变化,这些默认设置也会演进。应当保持稳定的是底层逻辑:按任务特性匹配服务商,而不是依据单一排名。
如果你是第一次配置服务商技术栈,就从默认设置开始,把几个真实的 issue 跑完整个工作流,然后在团队优先级指向不同方向的地方做覆盖。目标不是理论上最好的模型,而是让你的 Jira issue 更好、更快、摩擦更少的技术栈。