Each Job Needs Its Own Model
The same Jira workflow can feel sharp or strangely off depending on which model sits behind each step. What matters here is not who wins benchmarks, but why certain providers keep earning the same jobs inside a real product.

Why this is not a benchmark article
This is not a leaderboard. Inside Just, the useful question is not which model looks smartest in the abstract. It is which one makes each workflow step cleaner, steadier, and easier to trust.
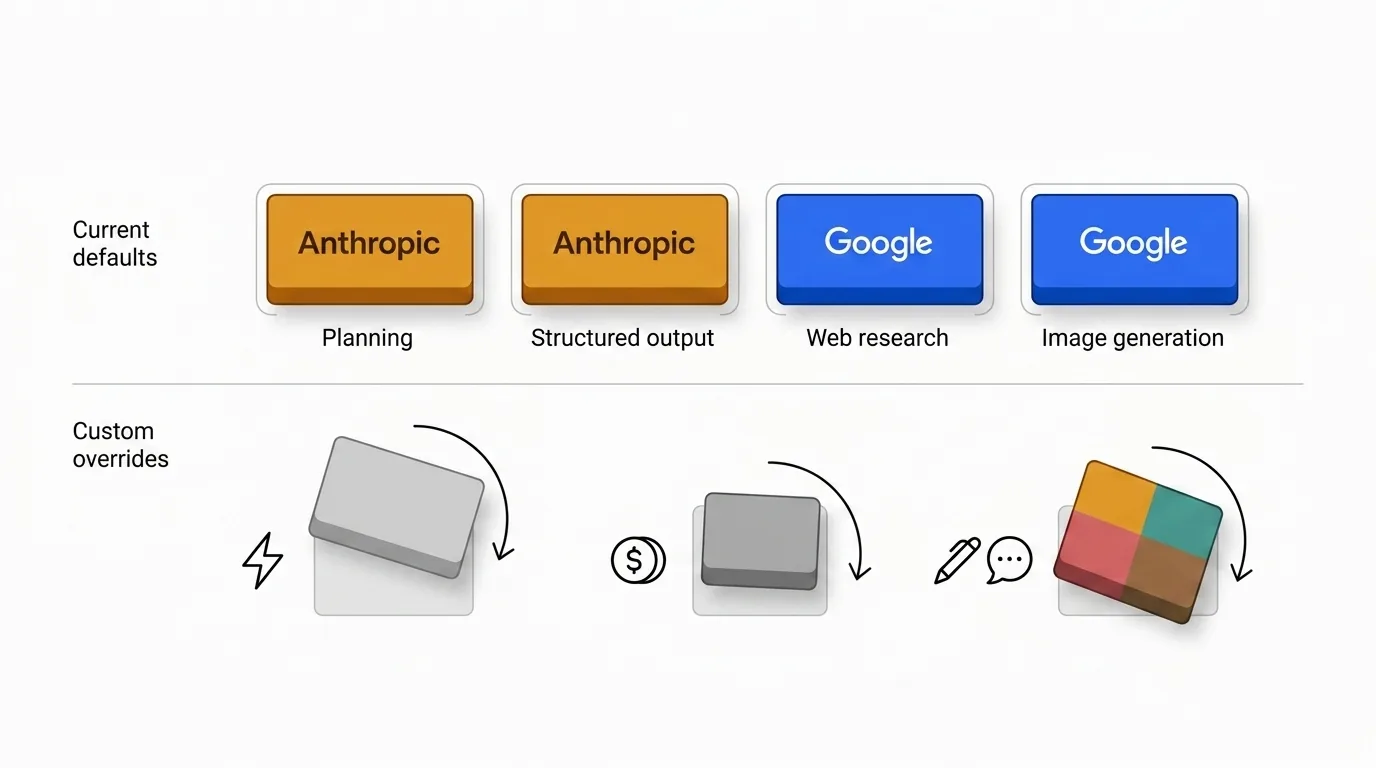
That is why the defaults are intentionally uneven. Some providers keep earning the planning core, while others make more sense when freshness, search quality, or multimodal output matter more.
If you want to see what those defaults look like once they are wired into the product, Just 2.0: Insights, Web Search, Images, Shared Context walks through the current workflow in practice.
If you want the full capability map, the AI matrix on the landing page shows what each provider supports across every feature. The version below is the shorter, article-sized view.
| Function | |||||
|---|---|---|---|---|---|
| Text reply | |||||
| Reply with reasoning | |||||
| Structured output | |||||
| Image generation | |||||
| Web search |
Why Anthropic owns the core
The core of Just — clarification questions, structured plans, issue-field shaping, and reasoning-heavy replies — runs on Anthropic by default. That choice is deliberate, and it comes with a trade-off I have accepted.
| Step | Model | Quality | Speed | Price |
|---|---|---|---|---|
| Text replies | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Field updates and issue shaping | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Reasoned replies | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Structured plans and specs | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Initial insight generation | Claude Sonnet 4.5 | 💡💡💡 | ⚡⚡⚡ | 💲💲💲 |
| Final compact shaping | Claude Haiku 4.5 | 💡💡 | ⚡⚡⚡⚡ | 💲 |
In my experience, Anthropic models are roughly 2× more expensive and 1.5× slower than the closest alternatives for similar work. I still default to them because the output is better in the ways that matter for planning.
The difference is not creativity. It is conciseness, instruction adherence, reasoning stability, and cleaner structured output. Claude Opus 4.6 follows detailed constraints more reliably, asks fewer unnecessary clarification questions, and needs fewer recovery passes when the workflow expects structured plans.
The trade-off is real, but inside a planning workflow I would rather pay more for a clean first pass than save money on outputs that need correction.
Why Google owns search and image generation
When the workflow needs fresh web context — competitive analysis, technical documentation lookups, and market data — the default shifts to Google. Specifically, Gemini 3.0 Pro for web research.
This is not just a capability checkbox. Google has spent decades solving ranking, relevance, freshness, and source quality at internet scale. That matters when web-grounded results feed directly into downstream planning. If the search step pulls stale sources or hallucinated citations, the plan built on top of it inherits those problems.
The image side follows the same logic. The current default is Gemini 3.1 Flash Image Preview — known publicly as Nano Banana 2. It handles images with embedded text more consistently than most alternatives I have tested: labels stay legible, layout holds, and text placement follows the prompt rather than drifting.
Where OpenAI, xAI, and Mistral fit
- OpenAI is the obvious all-rounder: capable across text, reasoning, structured output, web search, and image generation. Paradoxically, that breadth is part of why it is not the default for the planning core. When a provider is strong at everything, you often end up accepting good-enough everywhere rather than best-in-class where it matters most. As a single-provider fallback it is still hard to beat, and it remains the most practical choice for teams that would rather manage one API key than a mixed stack.
- xAI has matured faster than I expected. Grok now supports full structured output with guaranteed schema adherence, and its web search integration is solid. Where it earns its place most naturally is speed-sensitive work — early ideation, quick lookups, and exploratory drafts where turnaround matters more than polish.
- Mistral fits lighter, high-volume text tasks where cost efficiency is the primary constraint. It is also the most natural choice for teams with EU data residency requirements or a preference for a European provider stack.
When to choose other models
The defaults reflect my judgment, not a universal law. There are good reasons to override them.
- Cost-sensitive teams may decide the Anthropic multiplier is not worth it at their volume.
- Speed-sensitive teams may prefer lighter models for triage or ideation.
- Some organizations want one provider for tone consistency, governance, or procurement reasons.
If you do not want to manage multiple API keys and providers, using only OpenAI for everything is a perfectly sane option. Lately I have also found Google Gemini increasingly competitive as a general fallback — both are worth testing against your own tasks before committing to a stack.
Current defaults, not eternal truth
The mapping here reflects how I think about provider strengths today. Anthropic owns the core because its models currently produce the best planning-quality output for the trade-offs I am willing to accept. Google owns search and image work because its infrastructure strengths align naturally with those jobs.
These defaults will evolve as models, pricing, and trade-offs shift. What should stay stable is the logic underneath: match the provider to the job profile, not to a single ranking.
If you are setting up your provider stack for the first time, start with the defaults, run a few real issues through the full workflow, and then override where your team's priorities point you somewhere different. The goal is not the theoretically best model — it is the stack that makes your Jira issues better, faster, with less friction.