हर काम के लिए अलग मॉडल
वही Jira वर्कफ़्लो तेज़ और सटीक भी लग सकता है, और अजीब तरह से अटपटा भी — यह निर्भर करता है कि हर कदम के पीछे कौन सा मॉडल है। यहाँ असली सवाल यह नहीं है कि बेंचमार्क कौन जीतता है, बल्कि यह है कि किसी असली प्रोडक्ट में कुछ प्रोवाइडर बार-बार वही भूमिकाएँ क्यों पाते हैं।

यह बेंचमार्क आर्टिकल क्यों नहीं है
यह कोई रैंकिंग नहीं है। Just के अंदर सही सवाल यह नहीं है कि कौन सा मॉडल अमूर्त रूप से सबसे स्मार्ट दिखता है। सवाल यह है कि कौन सा मॉडल हर वर्कफ़्लो स्टेप को ज़्यादा साफ़, स्थिर, और भरोसेमंद बनाता है।
इसीलिए डिफ़ॉल्ट सेटिंग्स जानबूझकर असमान हैं। कुछ प्रोवाइडर बार-बार प्लानिंग कोर जीत लेते हैं, जबकि जब फ्रेशनेस, सर्च क्वालिटी या मल्टीमोडल आउटपुट ज़्यादा मायने रखती है, तो दूसरे प्रोवाइडर ज़्यादा समझदारी भरे विकल्प बन जाते हैं।
अगर आप देखना चाहते हैं कि यह लॉजिक प्रोडक्ट में कैसे दिखता है, तो Just 2.0: Insights, वेब सर्च, इमेजेज़, शेयर्ड कॉन्टेक्स्ट मौजूदा वर्कफ़्लो को व्यावहारिक रूप से समझाता है।
पूरी क्षमता का नक्शा देखने के लिए लैंडिंग पेज पर AI मैट्रिक्स है, जो हर फीचर में हर प्रोवाइडर का समर्थन दिखाता है। नीचे का संस्करण छोटा, आर्टिकल-साइज़ व्यू है।
| कार्य | |||||
|---|---|---|---|---|---|
| टेक्स्ट उत्तर | |||||
| तर्क सहित उत्तर | |||||
| संरचित आउटपुट | |||||
| चित्र निर्माण | |||||
| वेब खोज |
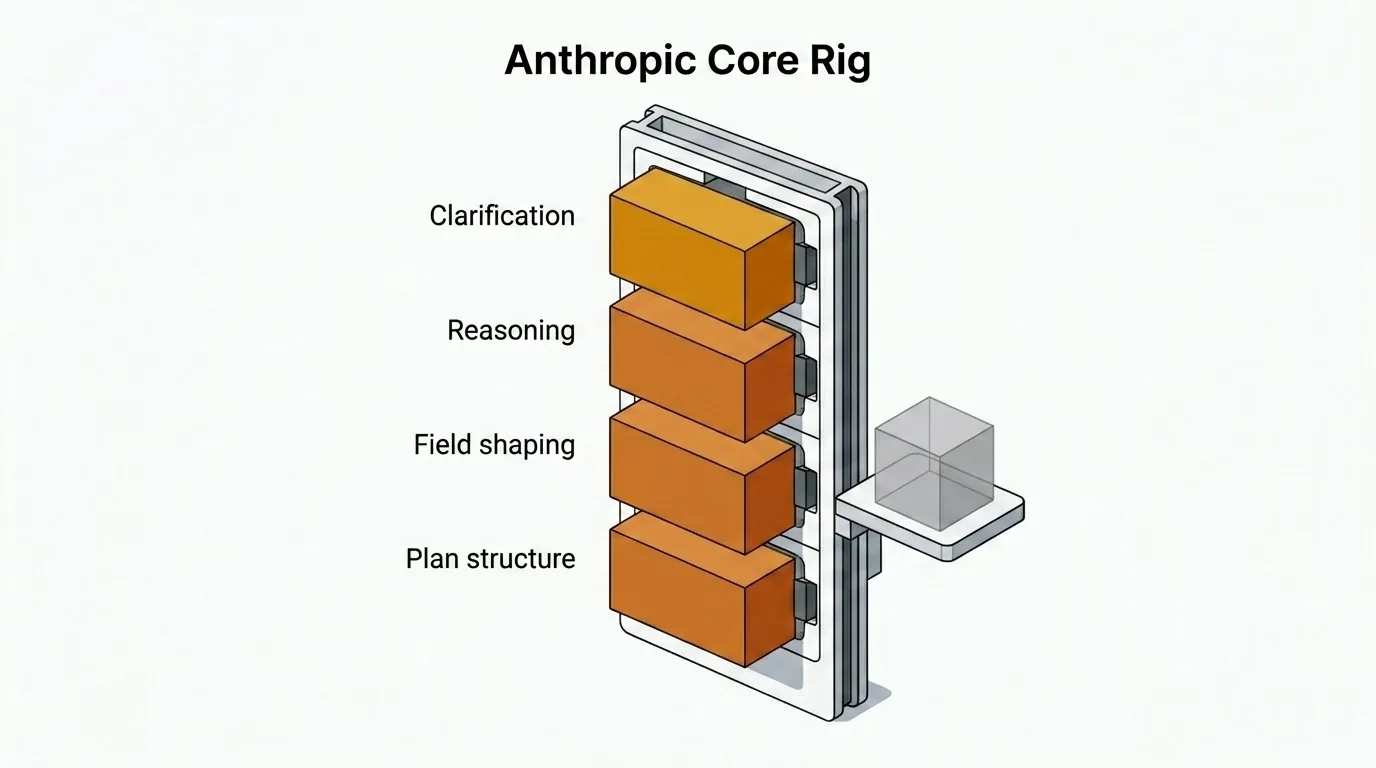
Anthropic कोर क्यों संभालता है
Just का कोर — क्लैरिफिकेशन सवाल, स्ट्रक्चर्ड प्लान, इश्यू फील्ड शेपिंग, और हेवी रीज़निंग वाले जवाब — डिफ़ॉल्ट रूप से Anthropic पर चलता है। यह चुनाव जानबूझकर किया गया है, और इसके साथ एक ट्रेडऑफ़ भी है जिसे मैंने स्वीकार किया है।
| चरण | मॉडल | गुणवत्ता | गति | मूल्य |
|---|---|---|---|---|
| टेक्स्ट जवाब | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| फील्ड अपडेट और इश्यू शेपिंग | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| रीज़न्ड जवाब | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| स्ट्रक्चर्ड प्लान और स्पेक्स | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| शुरुआती इनसाइट जनरेशन | Claude Sonnet 4.5 | 💡💡💡 | ⚡⚡⚡ | 💲💲💲 |
| फाइनल कॉम्पैक्ट शेपिंग | Claude Haiku 4.5 | 💡💡 | ⚡⚡⚡⚡ | 💲 |
मेरे अनुभव में, Anthropic मॉडल्स समान काम के लिए सबसे नज़दीकी विकल्पों से लगभग 2× महँगे और 1.5× धीमे हैं। फिर भी मैं इन्हें डिफ़ॉल्ट रखता हूँ क्योंकि प्लानिंग के लिए जो चीज़ें मायने रखती हैं, उनमें आउटपुट बेहतर होता है।
फर्क क्रिएटिविटी में नहीं है। फर्क है संक्षिप्तता, निर्देशों का पालन, रीज़निंग की स्थिरता, और ज़्यादा साफ़ स्ट्रक्चर्ड आउटपुट में। Claude Opus 4.6 विस्तृत कॉन्स्ट्रेंट्स को ज़्यादा भरोसेमंद तरीके से फॉलो करता है, कम ग़ैर-ज़रूरी क्लैरिफिकेशन सवाल पूछता है, और जब वर्कफ़्लो को स्ट्रक्चर्ड प्लान चाहिए तो कम रिकवरी पास की ज़रूरत पड़ती है।
ट्रेडऑफ़ असली है, लेकिन एक प्लानिंग वर्कफ़्लो में मैं पहले साफ़ पास के लिए ज़्यादा भुगतान करना पसंद करूँगा, बजाय उन आउटपुट पर पैसे बचाने के जिन्हें बाद में ठीक करना पड़े।
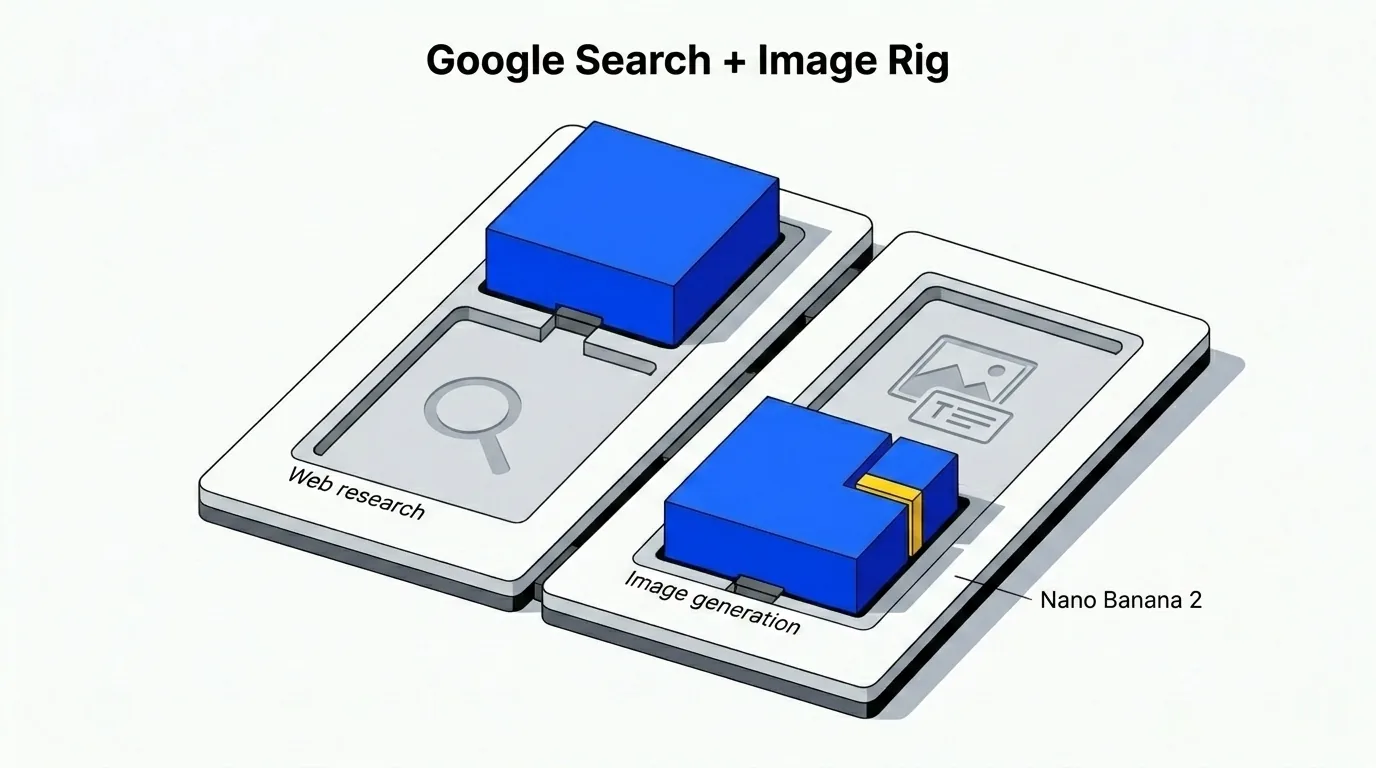
Google सर्च और इमेज जनरेशन क्यों संभालता है
जब वर्कफ़्लो को फ्रेश वेब कॉन्टेक्स्ट चाहिए — कॉम्पिटिटिव एनालिसिस, टेक्निकल डॉक्युमेंटेशन लुकअप, और मार्केट डेटा — तो डिफ़ॉल्ट Google की तरफ शिफ्ट हो जाता है। खासकर वेब रिसर्च के लिए Gemini 3.0 Pro।
यह सिर्फ किसी कैपेबिलिटी चेकबॉक्स की बात नहीं है। Google ने इंटरनेट स्केल पर रैंकिंग, रिलेवेंस, फ्रेशनेस और सोर्स क्वालिटी को दशकों तक सुलझाया है। जब वेब-ग्राउंडेड नतीजे सीधे डाउनस्ट्रीम प्लानिंग में जाते हैं, तो यह बहुत मायने रखता है। अगर सर्च स्टेप पुराने सोर्स या हैलूसिनेटेड सिटेशन लाता है, तो उसके ऊपर बना प्लान उन्हीं समस्याओं को विरासत में पाता है।
इमेज की बात भी इसी लॉजिक से होती है। मौजूदा डिफ़ॉल्ट है Gemini 3.1 Flash Image Preview — जिसे पब्लिकली Nano Banana 2 कहा जाता है। यह एम्बेडेड टेक्स्ट वाली इमेजेज़ को मेरे द्वारा टेस्ट किए गए ज़्यादातर विकल्पों से ज़्यादा कंसिस्टेंट तरीके से हैंडल करता है: लेबल पढ़ने लायक रहते हैं, लेआउट टिका रहता है, और टेक्स्ट प्लेसमेंट प्रॉम्प्ट को फॉलो करता है, भटकता नहीं।
OpenAI, xAI और Mistral कहाँ फिट होते हैं
- OpenAI सबसे स्पष्ट ऑल-राउंडर है: टेक्स्ट, रीज़निंग, स्ट्रक्चर्ड आउटपुट, वेब सर्च, और इमेज जनरेशन में काबिल। विरोधाभासी रूप से, यही चौड़ाई एक कारण है जो इसे प्लानिंग कोर के लिए डिफ़ॉल्ट नहीं बनाती। जब कोई प्रोवाइडर हर चीज़ में मज़बूत होता है, तो आप अक्सर हर जगह "ठीक-ठाक" आउटपुट से काम चला लेते हैं, बजाय जहाँ सबसे ज़्यादा ज़रूरी हो वहाँ बेस्ट पाने के। सिंगल-प्रोवाइडर फॉलबैक के रूप में यह अभी भी मुश्किल से पीछे छूटता है, और उन टीमों के लिए सबसे व्यावहारिक विकल्प बना रहता है जो मिक्स्ड स्टैक की बजाय एक API की मैनेज करना पसंद करते हैं।
- xAI जितनी तेज़ी से मेरी उम्मीद थी, उससे ज़्यादा तेज़ी से परिपक्व हुआ है। Grok अब गारंटीड स्कीमा एडहेरेंस के साथ पूरी तरह स्ट्रक्चर्ड आउटपुट सपोर्ट करता है, और इसका वेब सर्च इंटीग्रेशन मज़बूत है। यह सबसे स्वाभाविक रूप से स्पीड-सेंसिटिव काम में फिट होता है — शुरुआती आइडियेशन, जल्दी लुकअप, और एक्सप्लोरेटरी ड्राफ्ट जहाँ टर्नअराउंड टाइम पॉलिश से ज़्यादा मायने रखता है।
- Mistral हल्के, हाई-वॉल्यूम टेक्स्ट टास्क के लिए सही है जहाँ कॉस्ट एफिशिएंसी प्राथमिक बाधा है। यह EU डेटा रेसिडेंसी आवश्यकताओं वाली टीमों या यूरोपीय प्रोवाइडर स्टैक की प्राथमिकता रखने वालों के लिए भी सबसे स्वाभाविक विकल्प है।
दूसरे मॉडल कब चुनें
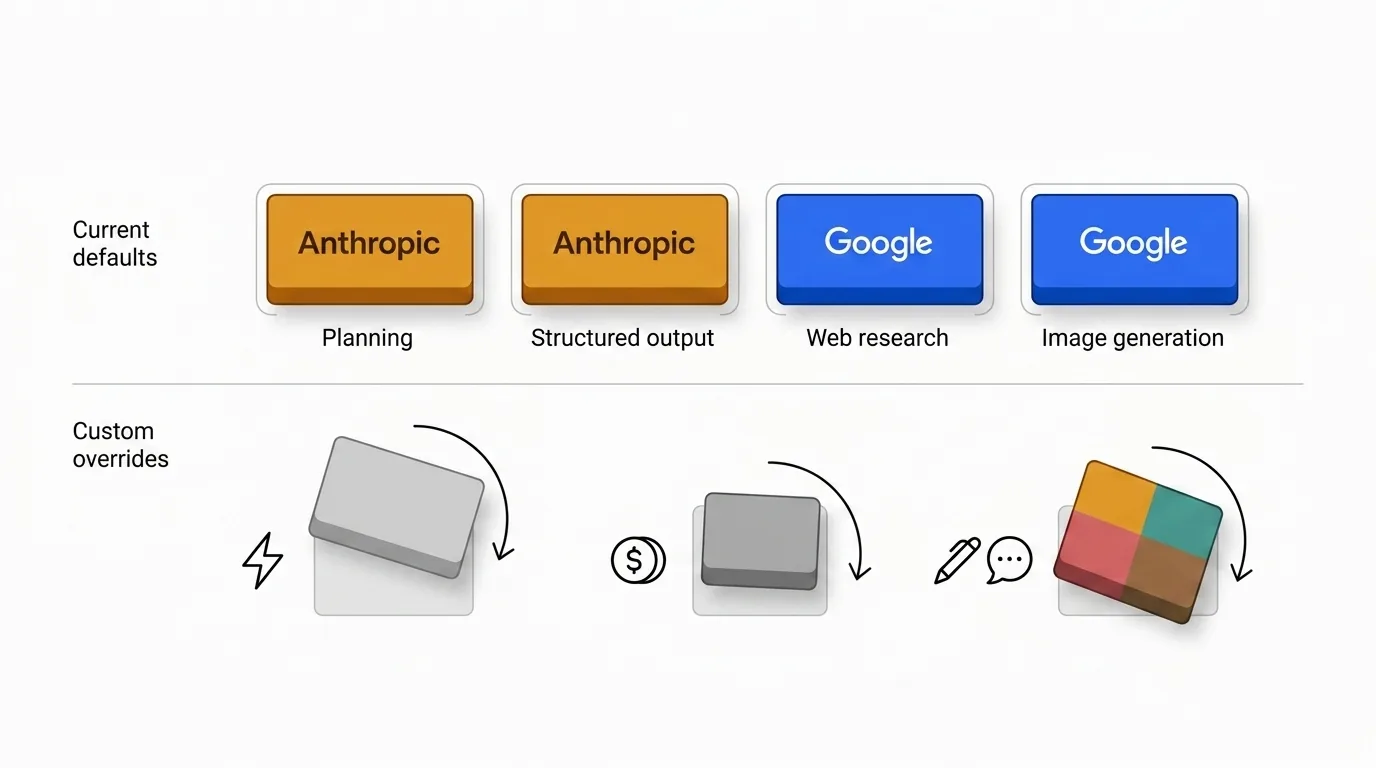
डिफ़ॉल्ट सेटिंग्स मेरे निर्णय को दर्शाती हैं, कोई सार्वभौमिक नियम नहीं। इन्हें ओवरराइड करने के अच्छे कारण हैं।
- कॉस्ट-सेंसिटिव टीमें तय कर सकती हैं कि Anthropic का मल्टीप्लायर उनके वॉल्यूम के हिसाब से नहीं चलता।
- स्पीड-सेंसिटिव टीमें ट्राइज या आइडियेशन के लिए हल्के मॉडल पसंद कर सकती हैं।
- कुछ संगठन टोन कंसिस्टेंसी, गवर्नेंस, या प्रोक्योरमेंट कारणों से एक ही प्रोवाइडर चाहते हैं।
अगर आप कई API की और प्रोवाइडर मैनेज नहीं करना चाहते, तो सब कुछ के लिए सिर्फ OpenAI इस्तेमाल करना पूरी तरह समझदारी भरा विकल्प है। हाल ही में मुझे Google Gemini भी एक जनरल फॉलबैक के तौर पर तेज़ी से प्रतिस्पर्धी लगने लगा है — स्टैक पर कमिट करने से पहले दोनों को अपने टास्क पर टेस्ट करना फायदेमंद है।
मौजूदा डिफ़ॉल्ट, कोई शाश्वत सत्य नहीं
यहाँ की मैपिंग दर्शाती है कि आज मैं प्रोवाइडर की ताकत के बारे में कैसे सोचता हूँ। Anthropic कोर संभालता है क्योंकि उसके मॉडल फिलहाल उन ट्रेडऑफ्स के लिए सबसे अच्छी प्लानिंग-क्वालिटी आउटपुट देते हैं जिन्हें मैं स्वीकार करने को तैयार हूँ। Google सर्च और इमेज काम संभालता है क्योंकि उसकी इंफ्रास्ट्रक्चर ताकत उन कामों के साथ स्वाभाविक रूप से मेल खाती है।
जैसे-जैसे मॉडल, प्राइसिंग और ट्रेडऑफ्स बदलेंगे, ये डिफ़ॉल्ट भी विकसित होंगे। जो स्थिर रहना चाहिए वह है अंदर की लॉजिक: प्रोवाइडर को टास्क प्रोफाइल से मैच करें, किसी एक रैंकिंग से नहीं।
अगर आप पहली बार अपना प्रोवाइडर स्टैक सेट कर रहे हैं, तो डिफ़ॉल्ट से शुरू करें, कुछ असली इश्यूज़ को पूरे वर्कफ़्लो से गुज़ारें, फिर वहाँ ओवरराइड करें जहाँ आपकी टीम की प्राथमिकताएँ किसी अलग दिशा में इशारा करें। लक्ष्य सैद्धांतिक रूप से सबसे अच्छा मॉडल नहीं है — यह वह स्टैक है जो आपके Jira इश्यूज़ को बेहतर, तेज़, और कम घर्षण के साथ बनाता है।