Každý úkol potřebuje svůj model
Stejný workflow v Jira může působit přesně nebo zvláštně nerovně podle toho, který model stojí za každým krokem. Důležité není, kdo vyhrává benchmarky, ale proč si určití poskytovatelé uvnitř skutečného produktu opakovaně získávají tytéž role.

Proč toto není článek o benchmarcích
Tohle není žebříček. V Just není užitečná otázka ta, který model vypadá abstraktně nejchytřeji. Jde o to, který dělá každý krok workflowu čistší, stabilnější a spolehlivější.
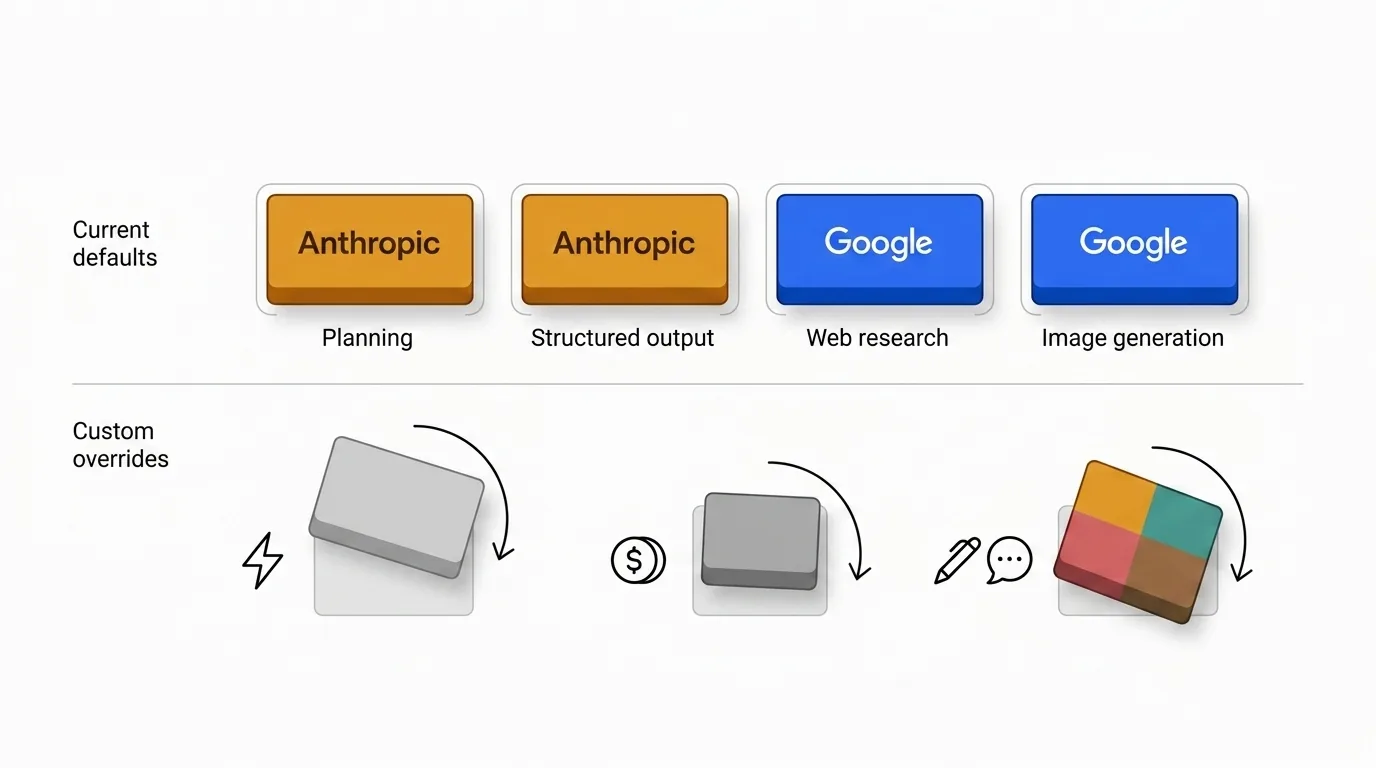
Proto jsou výchozí nastavení záměrně nerovnoměrná. Někteří poskytovatelé si opakovaně získávají plánovací jádro, zatímco jiní dávají větší smysl tam, kde záleží více na čerstvosti, kvalitě vyhledávání nebo multimodálním výstupu.
Pokud chceš vidět, jak tato logika vypadá po zavedení do produktu, Just 2.0: Insights, webové vyhledávání, obrázky a sdílený kontext prochází aktuální workflow v praxi.
Pro úplnou mapu schopností ukazuje AI matice na hlavní stránce, co každý poskytovatel podporuje napříč všemi funkcemi. Níže je kratší pohled ve velikosti článku.
| Funkce | |||||
|---|---|---|---|---|---|
| Textová odpověď | |||||
| Odpověď s odůvodněním | |||||
| Strukturovaný výstup | |||||
| Generování obrázků | |||||
| Vyhledávání na webu |
Proč jádro drží Anthropic
Jádro Just — upřesňující otázky, strukturované plány, tvarování polí issues a odpovědi náročné na uvažování — běží standardně na Anthropic. Tato volba je záměrná a přináší kompromis, který jsem přijal.
| Krok | Model | Kvalita | Rychlost | Cena |
|---|---|---|---|---|
| Textové odpovědi | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Aktualizace polí a tvarování issues | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Odpovědi s uvažováním | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Strukturované plány a specifikace | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Počáteční generování insightů | Claude Sonnet 4.5 | 💡💡💡 | ⚡⚡⚡ | 💲💲💲 |
| Finální kompaktní tvarování | Claude Haiku 4.5 | 💡💡 | ⚡⚡⚡⚡ | 💲 |
Podle mé zkušenosti jsou modely Anthropic přibližně 2× dražší a 1,5× pomalejší než nejbližší alternativy pro podobnou práci. Přesto je standardně volím, protože výstup je lepší v aspektech, na kterých záleží při plánování.
Rozdíl není v kreativitě. Jde o stručnost, dodržování pokynů, stabilitu uvažování a čistší strukturovaný výstup. Claude Opus 4.6 spolehlivěji dodržuje detailní omezení, klade méně zbytečných upřesňujících otázek a potřebuje méně opravných průchodů, když workflow očekává strukturované plány.
Kompromis je reálný, ale v plánovacím workflowu raději zaplatím více za čistý první průchod, než abych ušetřil na výstupech, které pak potřebují korekci.
Proč vyhledávání a generování obrázků drží Google
Když workflow potřebuje čerstvý webový kontext — konkurenční analýzu, vyhledávání technické dokumentace a tržní data — výchozí volba se přesouvá ke Googlu. Konkrétně Gemini 3.0 Pro pro webový výzkum.
To není jen zaškrtnutí políčka ve schopnostech. Google strávil desetiletí řešením rankingu, relevance, čerstvosti a kvality zdrojů v internetovém měřítku. To záleží, když výsledky ukotvené ve webu přímo ovlivňují navazující plánování. Pokud krok vyhledávání přináší zastaralé zdroje nebo halucinované citace, plán nad nimi postavený tyto problémy zdědí.
Obrazová stránka sleduje stejnou logiku. Aktuální výchozí nastavení je Gemini 3.1 Flash Image Preview — veřejně známý jako Nano Banana 2. Zpracovává obrázky s vloženým textem konzistentněji než většina alternativ, které jsem testoval: popisky zůstávají čitelné, rozvržení drží a umístění textu se řídí promptem namísto toho, aby se odchýlilo.
Kde zapadají OpenAI, xAI a Mistral
- OpenAI je zjevný všestranný hráč: schopný v textu, uvažování, strukturovaném výstupu, webovém vyhledávání a generování obrázků. Paradoxně je právě tato šíře důvodem, proč není výchozím nastavením pro plánovací jádro. Když je poskytovatel silný ve všem, přijímáš často dostačující výsledek všude, místo toho nejlepšího tam, kde to nejvíce záleží. Jako záloha pro jednoho poskytovatele ho stále jen těžko předčíš a zůstává nejpraktičtější volbou pro týmy, které raději spravují jeden API klíč než smíšený stack.
- xAI se vyvíjel rychleji, než jsem očekával. Grok nyní podporuje plný strukturovaný výstup se zaručeným dodržováním schématu a jeho integrace webového vyhledávání je solidní. Nejpřirozeněji se hodí pro práci citlivou na rychlost — časnou ideaci, rychlá vyhledávání a průzkumné návrhy, kde rychlost obratu záleží více než lesk.
- Mistral se hodí pro lehké, velkoobjemové textové úkoly, kde je primárním omezením nákladová efektivita. Je také nejpřirozenější volbou pro týmy s požadavky na datovou rezidenci v EU nebo s preferencí pro evropský stack poskytovatelů.
Kdy volit jiné modely
Výchozí nastavení odrážejí mé rozhodnutí, ne univerzální zákon. Existují dobré důvody je přepsat.
- Nákladově citlivé týmy mohou rozhodnout, že multiplikátor Anthropic se jim při jejich objemu nevyplatí.
- Rychlostně citlivé týmy mohou preferovat lehčí modely pro třídění nebo ideaci.
- Některé organizace chtějí jednoho poskytovatele z důvodu konzistentního tónu, governance nebo nákupních důvodů.
Pokud nechceš spravovat více API klíčů a poskytovatelů, je používání pouze OpenAI pro vše naprosto rozumná volba. V poslední době také nacházím Google Gemini jako obecnou zálohu stále konkurenceschopnějším — obě možnosti stojí za otestování na vlastních úkolech před volbou stacku.
Aktuální výchozí nastavení, ne věčná pravda
Mapování zde odráží, jak dnes přemýšlím o silných stránkách poskytovatelů. Anthropic drží jádro, protože jeho modely aktuálně produkují nejlepší výstup kvality plánování pro kompromisy, které jsem ochoten přijmout. Google drží vyhledávání a práci s obrázky, protože jeho infrastrukturní silné stránky se přirozeně shodují s těmito úkoly.
Tato výchozí nastavení se budou vyvíjet, jak se budou měnit modely, ceny a kompromisy. Co by mělo zůstat stabilní, je logika pod tím: přiřadit poskytovatele k profilu úkolu, ne k jedinému žebříčku.
Pokud nastavuješ svůj stack poskytovatelů poprvé, začni s výchozím nastavením, pusť několik skutečných issues přes celý workflow a pak přepiš tam, kde priority tvého týmu tě nasměrují jinam. Cílem není teoreticky nejlepší model — je to stack, který dělá tvé Jira issues lepší, rychlejší a s menším třením.