Cada tarea necesita su propio modelo
El mismo flujo de trabajo en Jira puede sentirse preciso o extrañamente irregular según el modelo que haya detrás de cada paso. Lo que importa aquí no es quién gana los benchmarks, sino por qué ciertos proveedores siguen ganándose los mismos roles dentro de un producto real.

Por qué esto no es un artículo de benchmarks
Esto no es una clasificación. Dentro de Just, la pregunta útil no es qué modelo parece más inteligente en abstracto. Es cuál hace cada paso del flujo de trabajo más limpio, más estable y más confiable.
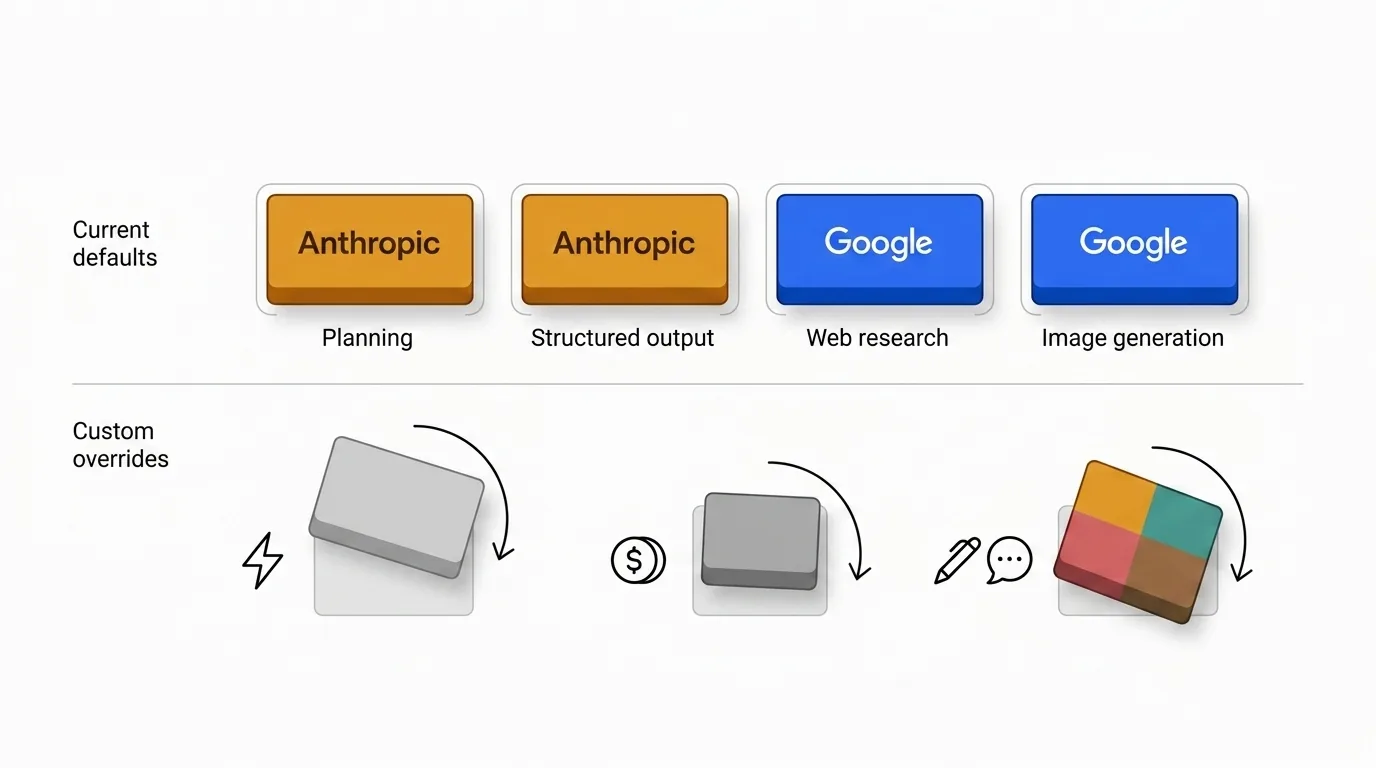
Por eso los valores predeterminados son deliberadamente desiguales. Algunos proveedores se ganan el núcleo de planificación repetidamente, mientras que otros tienen más sentido cuando la actualidad, la calidad de búsqueda o la salida multimodal importan más.
Si quieres ver cómo luce esa lógica ya integrada en el producto, Just 2.0: Insights, búsqueda web, imágenes y contexto compartido recorre el flujo de trabajo actual en la práctica.
Si quieres el mapa completo de capacidades, la matriz de IA en la página de inicio muestra qué soporta cada proveedor en cada función. La versión de abajo es la vista más corta, del tamaño de un artículo.
| Función | |||||
|---|---|---|---|---|---|
| Respuesta de texto | |||||
| Respuesta con razonamiento | |||||
| Salida estructurada | |||||
| Generación de imágenes | |||||
| Búsqueda web |
Por qué Anthropic domina el núcleo
El núcleo de Just — preguntas de aclaración, planes estructurados, configuración de campos de issues y respuestas con razonamiento intenso — corre sobre Anthropic de forma predeterminada. Esa elección es deliberada y tiene un coste que he aceptado.
| Paso | Modelo | Calidad | Velocidad | Precio |
|---|---|---|---|---|
| Respuestas de texto | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Actualizaciones de campos y configuración de issues | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Respuestas razonadas | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Planes estructurados y especificaciones | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Generación inicial de insights | Claude Sonnet 4.5 | 💡💡💡 | ⚡⚡⚡ | 💲💲💲 |
| Compactación final | Claude Haiku 4.5 | 💡💡 | ⚡⚡⚡⚡ | 💲 |
En mi experiencia, los modelos de Anthropic son aproximadamente 2× más caros y 1,5× más lentos que las alternativas más cercanas para trabajo similar. Aun así los uso como predeterminados porque la salida es mejor en los aspectos que importan para la planificación.
La diferencia no es creatividad. Es concisión, adherencia a las instrucciones, estabilidad del razonamiento y salida estructurada más limpia. Claude Opus 4.6 sigue restricciones detalladas de forma más fiable, hace menos preguntas de aclaración innecesarias y necesita menos rondas de corrección cuando el flujo de trabajo espera planes estructurados.
El compromiso es real, pero dentro de un flujo de planificación prefiero pagar más por un primer borrador limpio que ahorrar dinero en salidas que luego necesitan corrección.
Por qué Google domina la búsqueda y la generación de imágenes
Cuando el flujo de trabajo necesita contexto web fresco — análisis competitivo, búsquedas de documentación técnica y datos de mercado — la opción predeterminada cambia a Google. Concretamente, Gemini 3.0 Pro para investigación web.
Esto no es simplemente marcar una casilla de capacidades. Google lleva décadas resolviendo el ranking, la relevancia, la actualidad y la calidad de las fuentes a escala de internet. Eso importa cuando los resultados basados en la web alimentan directamente la planificación posterior. Si el paso de búsqueda extrae fuentes obsoletas o citas alucinadas, el plan construido sobre ellas hereda esos problemas.
El lado de las imágenes sigue la misma lógica. El predeterminado actual es Gemini 3.1 Flash Image Preview — conocido públicamente como Nano Banana 2. Maneja imágenes con texto incrustado con más consistencia que la mayoría de alternativas que he probado: las etiquetas permanecen legibles, el diseño se mantiene y la colocación del texto sigue el prompt en lugar de desviarse.
Dónde encajan OpenAI, xAI y Mistral
- OpenAI es el comodín evidente: capaz en texto, razonamiento, salida estructurada, búsqueda web y generación de imágenes. Paradójicamente, esa amplitud es en parte por qué no es el predeterminado para el núcleo de planificación. Cuando un proveedor es fuerte en todo, a menudo acabas aceptando un resultado suficientemente bueno en todas partes en lugar del mejor donde más importa. Como solución de respaldo única sigue siendo difícil de superar, y es la opción más práctica para equipos que prefieren gestionar una sola clave de API en lugar de un stack mixto.
- xAI ha madurado más rápido de lo que esperaba. Grok ahora soporta salida estructurada completa con adherencia garantizada al esquema, y su integración de búsqueda web es sólida. Donde encaja de forma más natural es en trabajo sensible a la velocidad — ideación temprana, búsquedas rápidas y borradores exploratorios donde el tiempo de respuesta importa más que el pulido.
- Mistral encaja en tareas de texto ligeras y de alto volumen donde la eficiencia de costes es la restricción principal. También es la elección más natural para equipos con requisitos de residencia de datos en la UE o preferencia por un stack de proveedor europeo.
Cuándo elegir otros modelos
Los valores predeterminados reflejan mi criterio, no una ley universal. Hay buenas razones para sobrescribirlos.
- Los equipos sensibles al coste pueden decidir que el multiplicador de Anthropic no vale la pena en su volumen.
- Los equipos sensibles a la velocidad pueden preferir modelos más ligeros para triaje o ideación.
- Algunas organizaciones quieren un solo proveedor por coherencia de tono, gobernanza o motivos de aprovisionamiento.
Si no quieres gestionar múltiples claves de API y proveedores, usar solo OpenAI para todo es una opción perfectamente razonable. Últimamente también encuentro Google Gemini cada vez más competitivo como solución general de respaldo — ambas opciones merecen probarse contra tus propias tareas antes de comprometerte con un stack.
Configuración actual, no verdad eterna
El mapeo aquí refleja cómo pienso sobre las fortalezas de los proveedores hoy. Anthropic domina el núcleo porque sus modelos producen actualmente la mejor salida de calidad de planificación para los compromisos que estoy dispuesto a aceptar. Google domina la búsqueda y el trabajo con imágenes porque sus fortalezas de infraestructura se alinean naturalmente con esas tareas.
Estos valores predeterminados evolucionarán a medida que los modelos, los precios y los compromisos cambien. Lo que debería permanecer estable es la lógica subyacente: hacer coincidir al proveedor con el perfil de la tarea, no con una clasificación única.
Si estás configurando tu stack de proveedores por primera vez, empieza con los predeterminados, haz pasar algunos issues reales por el flujo de trabajo completo y luego sobrescribe donde las prioridades de tu equipo te señalen en una dirección diferente. El objetivo no es el modelo teóricamente mejor — es el stack que hace que tus issues de Jira sean mejores, más rápidos y con menos fricción.