Elke taak heeft zijn eigen model nodig
Dezelfde Jira-workflow kan scherp of vreemd oneven aanvoelen, afhankelijk van welk model achter elke stap zit. Wat hier telt is niet wie benchmarks wint, maar waarom bepaalde providers steeds dezelfde taken binnenhalen in een echt product.

Waarom dit geen benchmark-artikel is
Dit is geen ranglijst. In Just is de nuttige vraag niet welk model er in de abstractie het slimst uitziet. Het is welk model elke workflowstap schoner, stabieler en betrouwbaarder maakt.
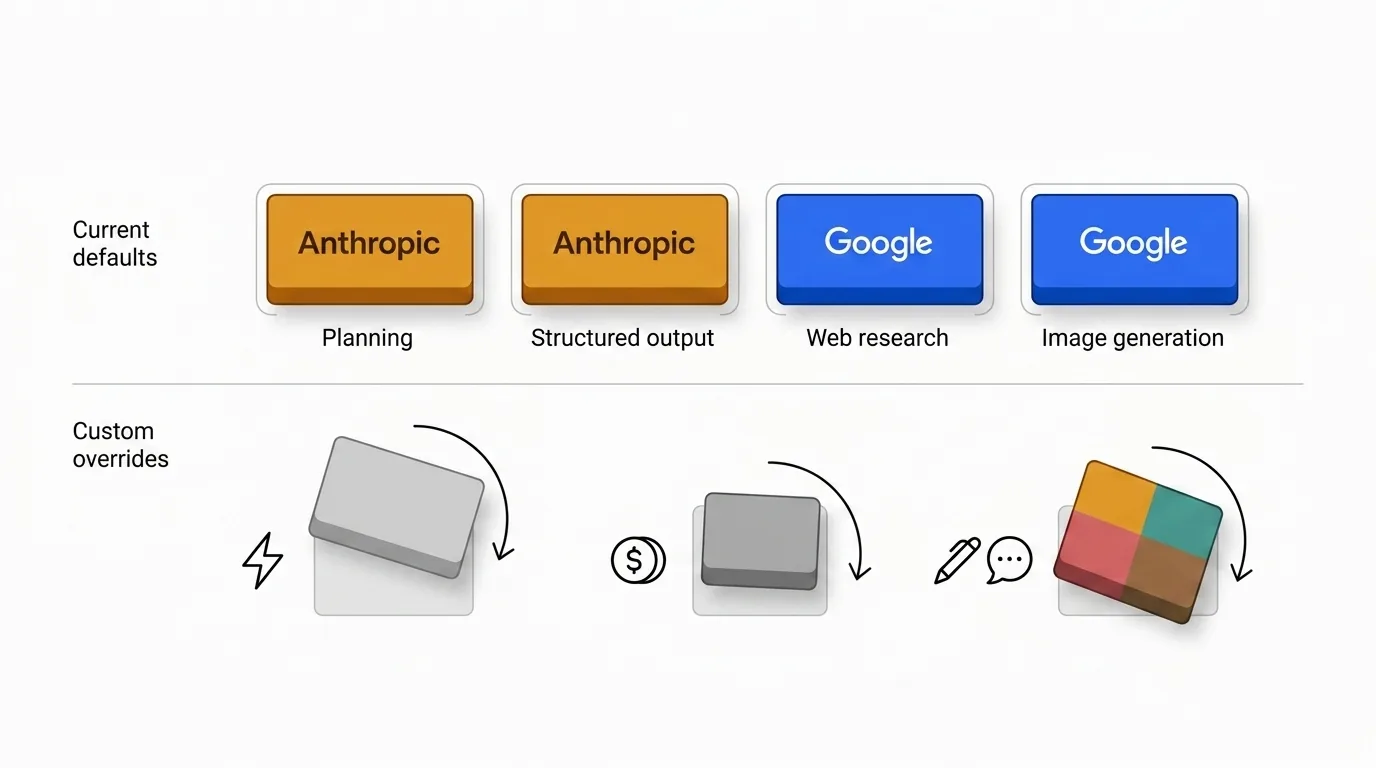
Daarom zijn de standaardinstellingen hier bewust ongelijk. Sommige providers winnen steeds de planningskern, terwijl andere meer zinvol zijn wanneer versheid, zoekkwaliteit of multimodale output belangrijker zijn.
Als je wilt zien hoe die logica eruitziet eenmaal ingebouwd in het product, loopt Just 2.0: Insights, webzoeken, afbeeldingen en gedeelde context het huidige workflow in de praktijk door.
Voor de volledige capaciteitskaart toont de AI-matrix op de startpagina wat elke provider ondersteunt voor elke functie. De versie hieronder is de kortere, artikelgrootte weergave.
| Functie | |||||
|---|---|---|---|---|---|
| Tekstantwoord | |||||
| Antwoord met redenering | |||||
| Gestructureerde output | |||||
| Beeldgeneratie | |||||
| Webzoekopdracht |
Waarom Anthropic de kern houdt
De kern van Just — verduidelijkingsvragen, gestructureerde plannen, vormgeving van issue-velden en redeneerware antwoorden — draait standaard op Anthropic. Die keuze is bewust en heeft een afweging die ik heb geaccepteerd.
| Stap | Model | Kwaliteit | Snelheid | Prijs |
|---|---|---|---|---|
| Tekstantwoorden | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Veldupdates en issue-vormgeving | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Beredeneerde antwoorden | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Gestructureerde plannen en specificaties | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Eerste insight-generatie | Claude Sonnet 4.5 | 💡💡💡 | ⚡⚡⚡ | 💲💲💲 |
| Finale compacte vormgeving | Claude Haiku 4.5 | 💡💡 | ⚡⚡⚡⚡ | 💲 |
Naar mijn ervaring zijn Anthropic-modellen ongeveer 2× duurder en 1,5× langzamer dan de dichtstbijzijnde alternatieven voor vergelijkbaar werk. Toch gebruik ik ze standaard omdat de output beter is op de manieren die tellen voor planning.
Het verschil zit niet in creativiteit. Het zit in beknoptheid, instructienaleving, redeneersstabiliteit en schonere gestructureerde output. Claude Opus 4.6 volgt gedetailleerde beperkingen betrouwbaarder, stelt minder onnodige verduidelijkingsvragen en heeft minder herstelstappen nodig wanneer de workflow gestructureerde plannen verwacht.
De afweging is reëel, maar in een planningsworkflow betaal ik liever meer voor een schone eerste ronde dan geld te besparen op outputs die daarna correctie nodig hebben.
Waarom Google zoeken en afbeeldingsgeneratie houdt
Wanneer de workflow verse webcontext nodig heeft — concurrentieanalyse, technische documentatiezoekacties en marktgegevens — verschuift de standaardkeuze naar Google. Specifiek Gemini 3.0 Pro voor webonderzoek.
Dit is niet zomaar een vinkje bij capaciteiten. Google heeft decennia besteed aan het oplossen van ranking, relevantie, versheid en bronkwaliteit op internetschaal. Dat telt wanneer webgebaseerde resultaten direct in downstream planning worden verwerkt. Als de zoekstap verouderde bronnen of gehallusineerde citaties oplevert, erft het plan dat erop gebouwd is die problemen.
De afbeeldingskant volgt dezelfde logica. De huidige standaard is Gemini 3.1 Flash Image Preview — publiekelijk bekend als Nano Banana 2. Het verwerkt afbeeldingen met ingebedde tekst consistenter dan de meeste alternatieven die ik heb getest: labels blijven leesbaar, de opmaak houdt stand en tekstplaatsing volgt de prompt in plaats van af te drijven.
Waar OpenAI, xAI en Mistral passen
- OpenAI is de voor de hand liggende alleskunner: bekwaam in tekst, redeneren, gestructureerde output, webzoeken en afbeeldingsgeneratie. Paradoxaal genoeg is die breedte deels waarom het niet de standaard is voor de planningskern. Wanneer een provider in alles sterk is, accepteer je vaak goed genoeg overal in plaats van het beste waar het het meest telt. Als enkel fallback is het nog steeds moeilijk te verslaan en blijft het de meest praktische keuze voor teams die liever één API-sleutel beheren dan een gemengde stack.
- xAI is sneller volwassen geworden dan ik verwachtte. Grok ondersteunt nu volledige gestructureerde output met gegarandeerde schema-naleving, en de webzoekintegratie is solide. Waar het het meest natuurlijk past is snelheidsgevoelig werk — vroege ideevorming, snelle opzoekacties en verkennende concepten waarbij doorlooptijd meer telt dan afwerking.
- Mistral past bij lichte, hoogvolume teksttaken waarbij kostenefficiëntie de primaire beperking is. Het is ook de meest voor de hand liggende keuze voor teams met EU-gegevensresidentievereisten of een voorkeur voor een Europese providerstack.
Wanneer andere modellen kiezen
De standaardinstellingen weerspiegelen mijn oordeel, geen universele wet. Er zijn goede redenen om ze te overschrijven.
- Kostengevoelige teams kunnen beslissen dat de Anthropic-vermenigvuldiger het niet waard is bij hun volume.
- Snelheidsgevoelige teams geven misschien de voorkeur aan lichtere modellen voor triage of ideevorming.
- Sommige organisaties willen één provider voor toonconsistenitie, governance of inkoopredenen.
Als je geen meerdere API-sleutels en providers wilt beheren, is alleen OpenAI gebruiken voor alles een volkomen zinnige optie. De laatste tijd vind ik Google Gemini ook steeds competitiever als algemene fallback — beide zijn het waard om te testen op je eigen taken voordat je je vastlegt op een stack.
Huidige standaardinstellingen, geen eeuwige waarheid
De mapping hier weerspiegelt hoe ik vandaag denk over de sterkten van providers. Anthropic houdt de kern omdat zijn modellen momenteel de beste planningskwaliteitsoutput produceren voor de afwegingen die ik bereid ben te accepteren. Google houdt zoeken en afbeeldingswerk omdat de infrastructuursterkten van Google van nature aansluiten bij die taken.
Deze standaardinstellingen zullen evolueren naarmate modellen, prijzen en afwegingen verschuiven. Wat stabiel moet blijven is de onderliggende logica: de provider afstemmen op het taakprofiel, niet op één ranglijst.
Als je je providerstack voor de eerste keer instelt, begin dan met de standaardinstellingen, laat een paar echte issues door de volledige workflow lopen en overschrijf dan daar waar de prioriteiten van jouw team je in een andere richting wijzen. Het doel is niet het theoretisch beste model — het is de stack die jouw Jira-issues beter, sneller en met minder wrijving maakt.