タスクごとに最適なモデルがある
同じJiraワークフローでも、各ステップの背後にあるモデルによって、精度が高く感じられたり不思議とちぐはぐに感じられたりする。ここで重要なのはベンチマークの勝者ではなく、なぜ特定のプロバイダーが実際のプロダクト内で同じ役割を繰り返し担い続けるのかという点だ。

なぜこれはベンチマーク記事ではないのか
これはランキングではない。Justの中で意味のある問いは、どのモデルが抽象的に最も賢く見えるかではない。どのモデルがワークフローの各ステップをよりクリーンに、より安定して、より信頼できるものにするかだ。
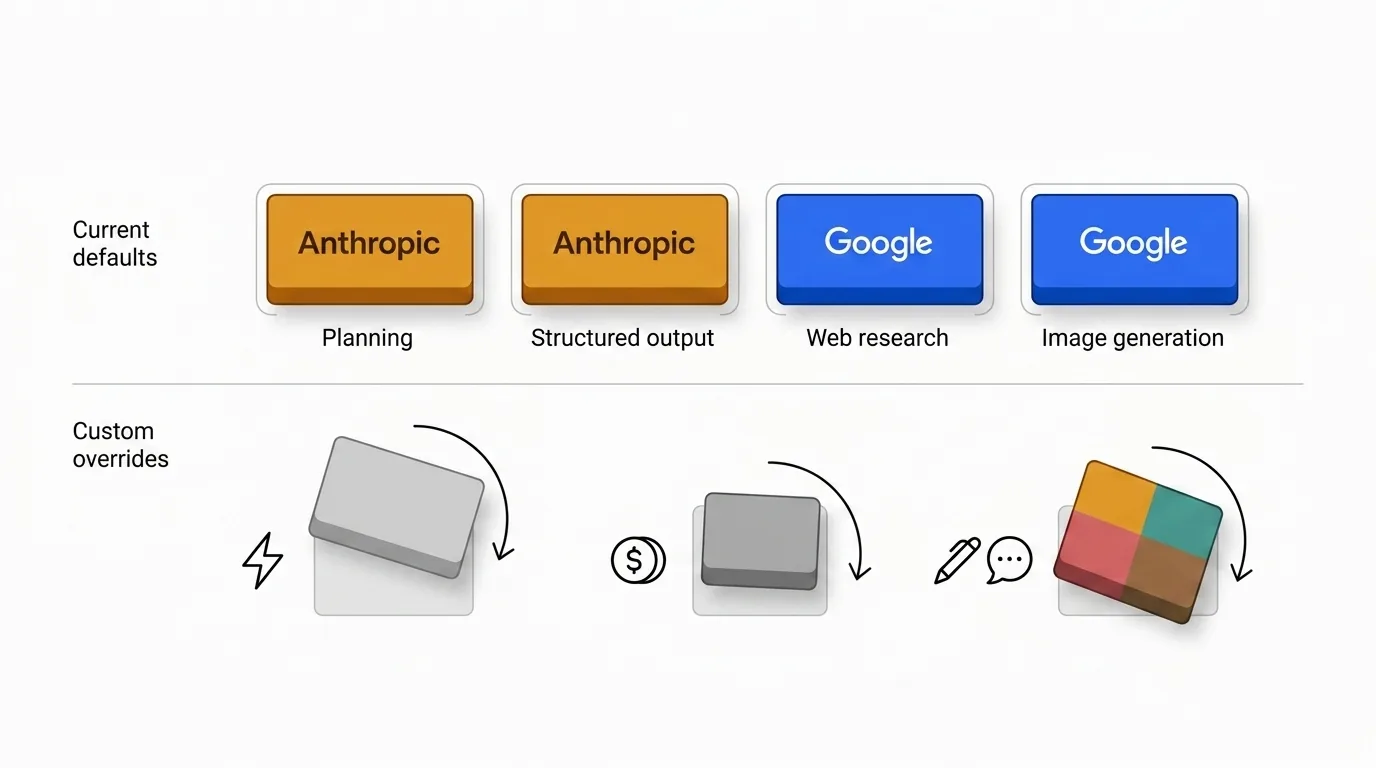
だからこそデフォルト設定は意図的に不均一になっている。あるプロバイダーはプランニングのコアを繰り返し担い、別のプロバイダーは情報の鮮度、検索品質、またはマルチモーダル出力がより重要なときに力を発揮する。
この論理がプロダクトに組み込まれた際の見た目を知りたければ、Just 2.0:Insights、ウェブ検索、画像、共有コンテキストが実際のワークフローを詳しく説明している。
全機能マップはランディングページのAIマトリックスで確認できる。各プロバイダーがどの機能をサポートしているかを一覧で見られる。以下の版はそれを記事サイズにまとめたものだ。
| 機能 | |||||
|---|---|---|---|---|---|
| テキスト応答 | |||||
| 推論付き応答 | |||||
| 構造化出力 | |||||
| 画像生成 | |||||
| Web検索 |
なぜAnthropicがコアを担うのか
Justのコア — 確認質問、構造化プラン、issueフィールドの整形、推論が必要な回答 — はデフォルトでAnthropicで動いている。これは意図的な選択であり、受け入れているトレードオフを伴う。
| ステップ | モデル | 品質 | 速度 | 価格 |
|---|---|---|---|---|
| テキスト回答 | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| フィールド更新とissue整形 | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| 推論付き回答 | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| 構造化プランと仕様 | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| 初期インサイト生成 | Claude Sonnet 4.5 | 💡💡💡 | ⚡⚡⚡ | 💲💲💲 |
| 最終コンパクト整形 | Claude Haiku 4.5 | 💡💡 | ⚡⚡⚡⚡ | 💲 |
私の経験では、Anthropicのモデルは同等の作業に対して最も近い代替手段より約2倍高価で1.5倍遅い。それでもデフォルトにしているのは、計画において重要な点で出力が優れているからだ。
違いは創造性にあるのではない。簡潔さ、指示への忠実さ、推論の安定性、そしてよりクリーンな構造化出力にある。Claude Opus 4.6は詳細な制約をより確実に守り、不要な確認質問をする頻度が低く、ワークフローが構造化プランを求める場面でやり直しが少ない。
トレードオフは本物だ。しかしプランニングのワークフローにおいては、後で修正が必要な出力に節約するよりも、最初のパスをクリーンに仕上げることに余分に支払うほうを選ぶ。
なぜGoogleが検索と画像生成を担うのか
ワークフローが新鮮なウェブコンテキスト — 競合分析、技術ドキュメントの検索、市場データ — を必要とするとき、デフォルトの選択はGoogleにシフトする。具体的にはウェブリサーチにGemini 3.0 Proを使用する。
これは単に機能チェックリストにチェックを入れるためではない。Googleはインターネットスケールでランキング、関連性、鮮度、ソース品質を解決するために数十年を費やしてきた。ウェブに基づいた結果が下流のプランニングに直接流れ込む場合、それは重要だ。検索ステップが古いソースや幻覚した引用を持ち込めば、その上に構築されたプランはその問題を引き継ぐ。
画像については同じ論理が適用される。現在のデフォルトはGemini 3.1 Flash Image Preview — 公開名はNano Banana 2 — だ。テキストが埋め込まれた画像を私がテストした代替手段の多くよりも一貫して処理する:ラベルは読みやすいまま、レイアウトが崩れず、テキストの配置がプロンプトに従ってずれない。
OpenAI、xAI、Mistralはどこに当てはまるのか
- OpenAIは明らかなオールラウンダーだ:テキスト、推論、構造化出力、ウェブ検索、画像生成においてすべて有能だ。逆説的だが、この幅広さがプランニングコアのデフォルトにならない理由の一つでもある。あらゆる面で強いプロバイダーは、最も重要なところで最高の結果を出すのではなく、どこでも「そこそこ良い」結果を受け入れることになりがちだ。単一プロバイダーのフォールバックとしては依然として非常に使いやすく、複数のAPIキーではなく一つを管理したいチームにとって最も実用的な選択肢でもある。
- xAIは私の予想よりも速く成熟した。Grokはスキーマ準拠が保証された完全な構造化出力をサポートするようになり、ウェブ検索統合も安定している。最も自然に活躍するのは速度が重要な作業 — 初期アイデア出し、素早い調査、仕上げより回転速度が重要な探索的ドラフト — だ。
- Mistralはコスト効率が主要な制約となる軽量・大量のテキストタスクに適している。EUデータ居住要件を持つチームや欧州プロバイダースタックを好むチームにとっても最も自然な選択肢だ。
他のモデルを選ぶべき場合
デフォルト設定は私の判断を反映したものであり、普遍的な法則ではない。上書きする合理的な理由は存在する。
- コストに敏感なチームは、そのボリュームではAnthropicの倍率が割に合わないと判断するかもしれない。
- スピードに敏感なチームは、トリアージやアイデア出しに軽量モデルを好むかもしれない。
- トーンの一貫性、ガバナンス、または調達上の理由から、一つのプロバイダーに統一したい組織もある。
複数のAPIキーとプロバイダーを管理したくない場合、すべてにOpenAIだけを使うのは十分に合理的な選択だ。最近はGoogle Geminiも汎用フォールバックとして競争力が増していると感じている — スタックを決める前に自分のタスクで両方をテストする価値がある。
現在のデフォルト設定、永遠の真理ではない
ここでのマッピングは、今日のプロバイダーの強みについての私の考えを反映している。Anthropicがコアを担うのは、現在そのモデルが私が受け入れるトレードオフのなかで最高のプランニング品質の出力を生み出すからだ。Googleが検索と画像作業を担うのは、Googleのインフラの強みがそれらのタスクに自然に合致するからだ。
これらのデフォルトはモデル、価格、トレードオフの変化とともに進化する。安定すべきなのはその下にある論理だ:プロバイダーをタスクプロファイルに合わせること、単一のランキングではなく。
プロバイダースタックを初めて設定するなら、デフォルトから始め、実際のissueをいくつかフルワークフローに通し、そしてチームの優先事項が別の方向を示している場所を上書きしていこう。目標は理論上最良のモデルではない。JiraのissueをよりよくÌ、より速く、よりスムーズにするスタックだ。