Chaque tâche mérite son propre modèle
Le même workflow Jira peut sembler précis ou étrangement approximatif selon le modèle qui se trouve derrière chaque étape. Ce qui compte ici n'est pas qui remporte les benchmarks, mais pourquoi certains fournisseurs continuent à décrocher les mêmes rôles dans un vrai produit.

Pourquoi ce n'est pas un article de benchmarks
Ce n'est pas un classement. Dans Just, la question pertinente n'est pas quel modèle semble le plus intelligent dans l'absolu. C'est lequel rend chaque étape du workflow plus propre, plus stable et plus fiable.
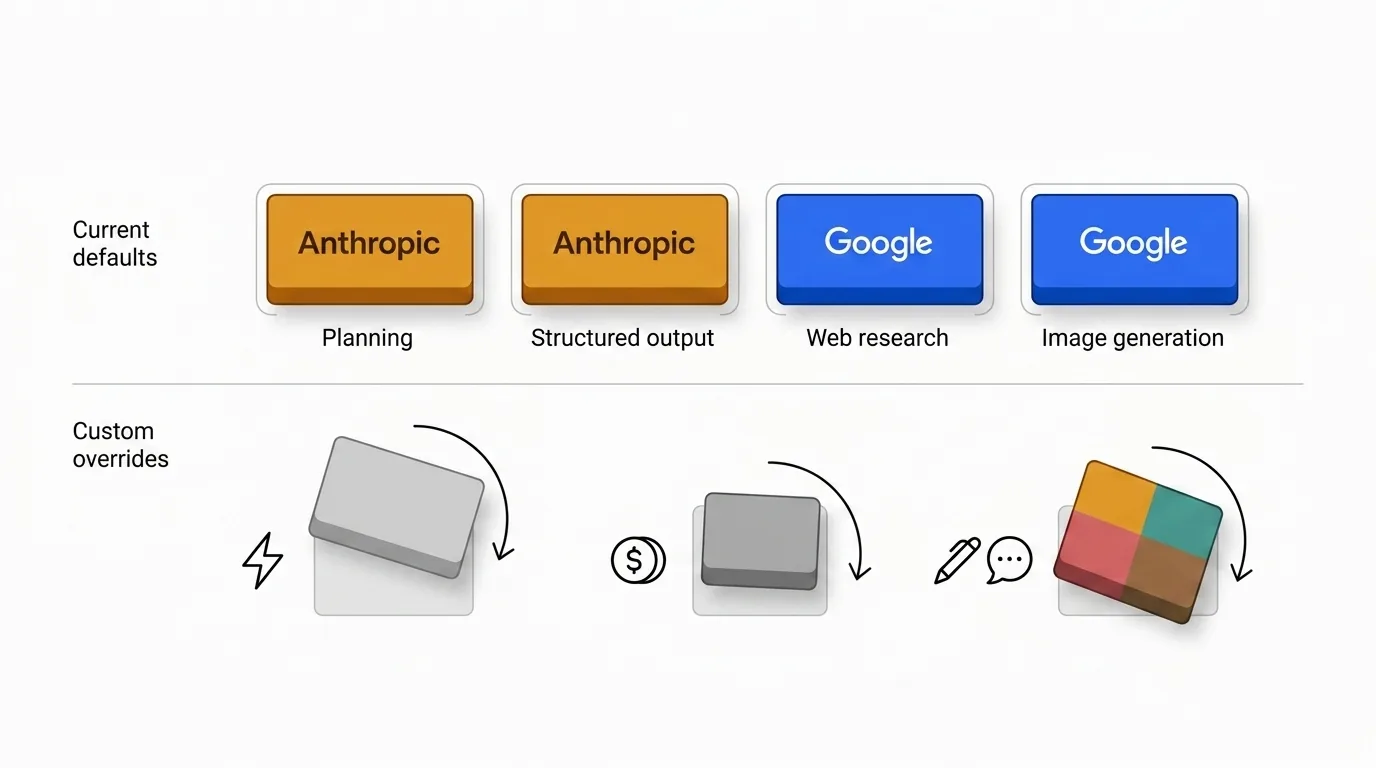
C'est pourquoi les valeurs par défaut sont délibérément inégales. Certains fournisseurs continuent à décrocher le cœur de planification, tandis que d'autres ont plus de sens quand la fraîcheur, la qualité de recherche ou la sortie multimodale comptent davantage.
Si tu veux voir à quoi ressemble cette logique une fois intégrée dans le produit, Just 2.0 : Insights, recherche web, images et contexte partagé parcourt le workflow actuel en pratique.
Pour la carte complète des capacités, la matrice IA sur la page d'accueil montre ce que chaque fournisseur supporte pour chaque fonctionnalité. La version ci-dessous est la vue plus courte, adaptée à la taille d'un article.
| Fonction | |||||
|---|---|---|---|---|---|
| Réponse texte | |||||
| Réponse avec raisonnement | |||||
| Sortie structurée | |||||
| Génération d'images | |||||
| Recherche web |
Pourquoi Anthropic tient le cœur
Le cœur de Just — questions de clarification, plans structurés, mise en forme des champs d'issues et réponses à fort raisonnement — fonctionne sur Anthropic par défaut. Ce choix est délibéré et comporte un compromis que j'ai accepté.
| Étape | Modèle | Qualité | Vitesse | Prix |
|---|---|---|---|---|
| Réponses textuelles | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Mises à jour de champs et mise en forme d'issues | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Réponses raisonnées | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Plans structurés et spécifications | Claude Opus 4.6 | 💡💡💡💡 | ⚡⚡ | 💲💲💲💲 |
| Génération initiale d'insights | Claude Sonnet 4.5 | 💡💡💡 | ⚡⚡⚡ | 💲💲💲 |
| Mise en forme compacte finale | Claude Haiku 4.5 | 💡💡 | ⚡⚡⚡⚡ | 💲 |
D'après mon expérience, les modèles Anthropic sont environ 2× plus chers et 1,5× plus lents que les alternatives les plus proches pour un travail similaire. Je les utilise quand même par défaut parce que la sortie est meilleure dans les aspects qui comptent pour la planification.
La différence n'est pas dans la créativité. Elle est dans la concision, le respect des instructions, la stabilité du raisonnement et une sortie structurée plus propre. Claude Opus 4.6 suit des contraintes détaillées de façon plus fiable, pose moins de questions de clarification inutiles et a besoin de moins de passes de correction quand le workflow attend des plans structurés.
Le compromis est réel, mais dans un workflow de planification je préfère payer plus pour un premier passage propre que d'économiser sur des sorties qui demandent ensuite des corrections.
Pourquoi Google tient la recherche et la génération d'images
Quand le workflow a besoin d'un contexte web frais — analyse concurrentielle, recherches de documentation technique et données de marché — le choix par défaut bascule vers Google. Plus précisément, Gemini 3.0 Pro pour la recherche web.
Ce n'est pas qu'une case à cocher dans une matrice de capacités. Google a passé des décennies à résoudre le classement, la pertinence, la fraîcheur et la qualité des sources à l'échelle d'internet. Ça compte quand des résultats ancrés dans le web alimentent directement la planification en aval. Si l'étape de recherche remonte des sources obsolètes ou des citations hallucinées, le plan construit dessus hérite de ces problèmes.
Le côté images suit la même logique. Le défaut actuel est Gemini 3.1 Flash Image Preview — connu publiquement sous le nom Nano Banana 2. Il gère les images avec du texte intégré plus régulièrement que la plupart des alternatives que j'ai testées : les étiquettes restent lisibles, la mise en page tient, et le placement du texte suit le prompt plutôt que de dériver.
Où s'insèrent OpenAI, xAI et Mistral
- OpenAI est l'évident couteau suisse : capable en texte, raisonnement, sortie structurée, recherche web et génération d'images. Paradoxalement, cette polyvalence est en partie pourquoi ce n'est pas le défaut pour le cœur de planification. Quand un fournisseur est fort partout, on finit souvent par accepter un résultat suffisamment bon partout plutôt que le meilleur là où ça compte vraiment. En tant que solution de secours unique, il reste difficile à battre, et c'est le choix le plus pratique pour les équipes qui préfèrent gérer une seule clé API plutôt qu'un stack mixte.
- xAI a évolué plus vite que je ne l'attendais. Grok supporte maintenant une sortie structurée complète avec une adhérence garantie au schéma, et son intégration de recherche web est solide. Là où il s'intègre le plus naturellement, c'est dans le travail sensible à la vitesse — idéation précoce, recherches rapides et brouillons exploratoires où le délai d'exécution importe plus que le polish.
- Mistral convient aux tâches de texte légères et à fort volume où l'efficacité des coûts est la contrainte principale. C'est aussi le choix le plus naturel pour les équipes ayant des exigences de résidence des données dans l'UE ou une préférence pour un stack de fournisseur européen.
Quand choisir d'autres modèles
Les valeurs par défaut reflètent mon jugement, pas une loi universelle. Il y a de bonnes raisons de les surcharger.
- Les équipes sensibles aux coûts peuvent décider que le multiplicateur Anthropic ne vaut pas leur volume.
- Les équipes sensibles à la vitesse peuvent préférer des modèles plus légers pour le triage ou l'idéation.
- Certaines organisations veulent un seul fournisseur pour des raisons de cohérence de ton, de gouvernance ou d'approvisionnement.
Si tu ne veux pas gérer plusieurs clés API et fournisseurs, utiliser seulement OpenAI pour tout est une option parfaitement sensée. Dernièrement, je trouve aussi Google Gemini de plus en plus compétitif comme solution de repli générale — les deux méritent d'être testés sur tes propres tâches avant de t'engager dans un stack.
Valeurs par défaut actuelles, pas une vérité éternelle
Le mapping ici reflète comment je vois les forces des fournisseurs aujourd'hui. Anthropic tient le cœur parce que ses modèles produisent actuellement la meilleure sortie de qualité de planification pour les compromis que je suis prêt à accepter. Google tient la recherche et le travail sur les images parce que ses forces d'infrastructure s'alignent naturellement avec ces tâches.
Ces valeurs par défaut évolueront à mesure que les modèles, les prix et les compromis changent. Ce qui devrait rester stable, c'est la logique sous-jacente : faire correspondre le fournisseur au profil de la tâche, pas à un seul classement.
Si tu configures ton stack de fournisseurs pour la première fois, commence par les valeurs par défaut, fais passer quelques vraies issues dans le workflow complet, puis surcharge là où les priorités de ton équipe te pointent vers quelque chose de différent. L'objectif n'est pas le modèle théoriquement meilleur — c'est le stack qui rend tes issues Jira meilleures, plus rapides et avec moins de friction.