AI 并不会修复团队失调,它只会把问题遮住。
这些工具看起来像是在解决 Jira 里一个老问题:把模糊工单变成可执行内容。可一份打磨过的结果,往往会让团队误以为已经达成共识,而真正的清晰其实还没有出现。

神灯精灵问题
每次想到 AI,我总会回到一个画面:AI 很像神灯精灵。你说什么,它就做什么;但你真正想表达的东西,它未必知道。而大量产品交付出问题,恰恰就出在这两者之间的那段距离里。
这种场景你一定见过。产品经理手上同时挂着四件事,于是花两分钟写了一个 Jira 工单。这个工单不是故意写得差,它只是模糊、仓促、不完整,里面塞满了许多从来没有被明确说出口的默认前提。
工程团队接手后,会根据现有文字做出一个看上去挺合理的东西。可两周后到了评审,所有人都会说出某种版本的同一句话:我本来不是这个意思。
没有人撒谎,也没有人偷懒。只是团队真正想做的事,在开工前从来没有被说清楚。到了 AI 这里,这个问题还会更严重,因为模型没有那种“团队里大家都懂”的背景来帮它补空白。如果工单本身几乎不带上下文,那这个“精灵”其实是在近乎空白的条件下工作。
信息最弱的那个载体
想一想,产品真正的知识到底藏在哪里。代码仓库知道你的架构、命名方式、依赖关系和实现边界。设计文件知道你的视觉语言、交互习惯,以及那些重复到足以变成系统的设计决定。历史工单和文档知道团队内部的词汇体系,也知道你们通常怎样表达取舍。
可 Jira 工单几乎什么都不知道。很多时候,它恰恰是整套工作栈里上下文最贫瘠的那个载体。所以当团队把一张工单丢进 AI 工具里,却期待高质量输出,本质上就是在要求它用最少的信息,给出最好的答案。
这就是为什么结果常常听起来很像那么回事,却又总是贴不住实际。验收标准默认了错误的用户。设计建议飘向了你根本不会上线的视觉风格。技术方案忽略了你的技术栈、部署方式,或者忽略了团队明明有意不走的那些捷径。AI 不是“失灵”了,它只是拿着很差的交代,尽力给出一个看起来说得过去的东西。
自信满满的胡话
大多数 Jira AI 工具都遵循同一种套路:打开 issue,点一下按钮,然后得到描述、验收标准,也许还有子任务拆分。这个过程之所以让人觉得“效率很高”,是因为结果来得快,而且看起来整齐、像样、有结构。
通常就是这样:
- 打开 issue;
- 点一下按钮;
- 拿到一段排版干净的文字、一些标准,也许再加几个子任务。
但“有结构”并不等于“已经对齐”。如果输入本身就是模糊、缺乏上下文的,那输出不过是同样的含糊,被包装得更像正确答案而已。很多时候,这类工具甚至会把问题弄得更糟,因为一旦排版看起来完整了,大家反而更不愿意在真正开始交付前去质疑那些默认前提。
真正危险的地方就在这里:输入是垃圾,输出还是垃圾,只不过现在这堆垃圾带着标题、小点和一种“我很确定”的口气。团队会在更有信心的同时,带着更少的清晰度走进实现阶段。

AI 真正需要的东西
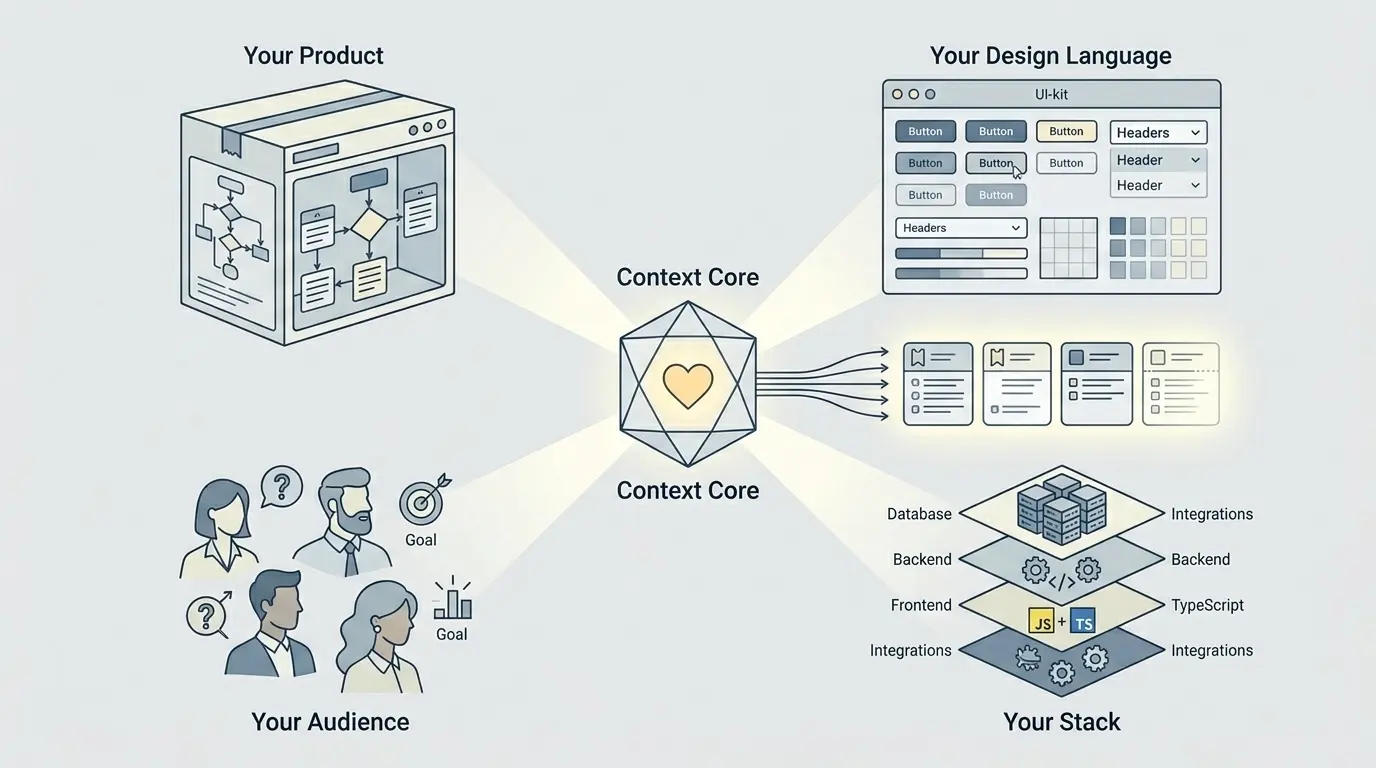
AI 想要针对一张 Jira issue 产出真正有用的内容,首先必须理解它所在世界里的四件事:
- 你的产品:它到底做什么,哪些结果最重要,这个功能究竟要为用户和业务改善什么。
- 你的设计语言:视觉模式、界面组件体系、交互习惯,这些东西决定了输出看起来像你的产品,而不是像某个通用演示。
- 你的受众:他们是谁,他们需要什么,他们期待什么,又不知道什么。几乎每个功能里的措辞、交互和边界情况都会因此发生变化。
- 你的技术栈:真实使用的框架、运行边界、集成方式、数据限制和技术约束,这些都应该决定什么样的建议才算站得住脚。
有意思的是,大多数团队其实早就拥有这些东西了。它们存在于代码、文档、原型和团队记忆里。只是它们没有以 AI 看得见的形式存在于 Jira 里而已。所以只盯着 Jira 的工具,天然就看不到项目最关键的上下文。
如果你想看这层上下文更落地的做法,可以读这篇 你的 AI 其实在猜你的产品,里面拆开讲了该存什么、又该怎么复用。
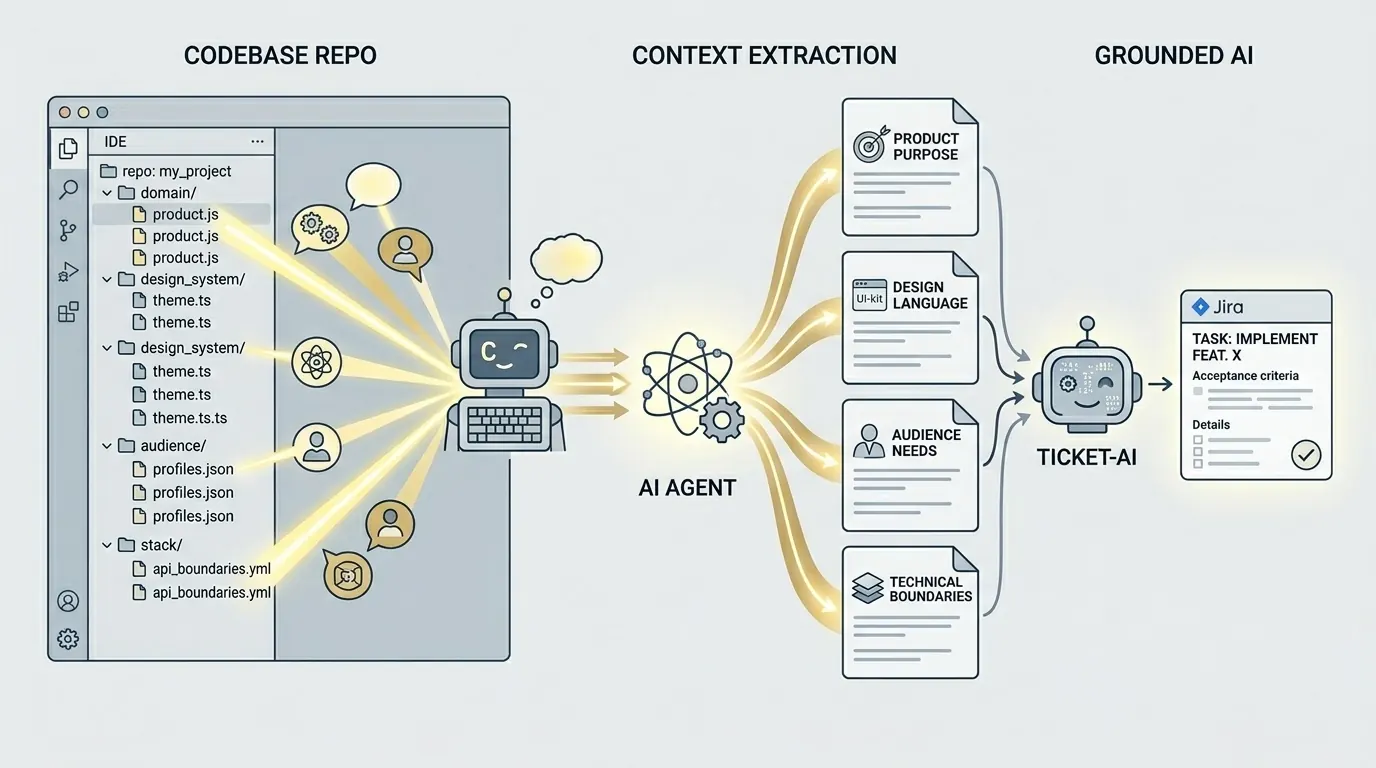
你的代码知道得更多
当下那些优秀的编程代理,真正让人兴奋的一点,就是它们很擅长读仓库,并把仓库里的东西转成清晰可读的上下文。你可以把 Claude Code、Codex 或其他靠谱的编程代理指向仓库,让它生成一份 markdown 摘要,说明产品目标、技术栈、实现边界、已知空缺,以及已经显露出来的业务信号。整个过程花的是几分钟,不是一整周的文档工程。
这会直接改变局面。你不再是拿着两句工单描述,让 AI 在真空里硬猜,而是先给它一份落在地上的产品、设计体系、受众和技术栈摘要。模型这时候就不再是在黑暗里即兴发挥,而是在一个真正接近你项目现实的世界里推理。
你的代码仓库一直都握着这些答案。组件名称会暴露设计语言,领域模型会透露产品的思考方式,集成和依赖库会说明技术边界。你并不需要从零发明上下文,你需要的是把仓库里本来就有的东西提炼成另一套 AI 能稳定利用的形式。
被藏起来的决定
就算项目上下文已经很好,仍然还有第二个问题,是 AI 靠猜永远猜不出来的:那些还没有人真正做出的决定。每一张 Jira issue 里,其实都藏着关于权限、上线规则、边界情况、向后兼容、交互细节,以及“这个功能上线后到底怎样才算成功”的大量默认假设。
这些决定不会因为工作开始了就自动消失。它们只会在 sprint 进行到一半时重新冒出来,而那恰好是发现问题最贵的时候。设计师会问:应该参考哪一个现有页面?工程师会问:这个流程是不是已经有现成 API?有人突然意识到,验收标准默认用户已经登录,可实际上有一半体验是匿名的。事后看,这些都不算意外,它们从一开始就一直在那里。
所以,光有上下文还不够。你还需要问题,而且是那种既扎根于工单本身、又扎根于真实产品上下文的问题。这个功能是给老用户还是只给新用户?浏览器在流程中途被关掉会怎样?它只面向管理员吗?这是一次性动作,还是会反复发生的行为?几轮坦诚而具体的回答,往往比再来一份排版精美的规格说明更能带来真正的对齐。
Just 里是怎么做的
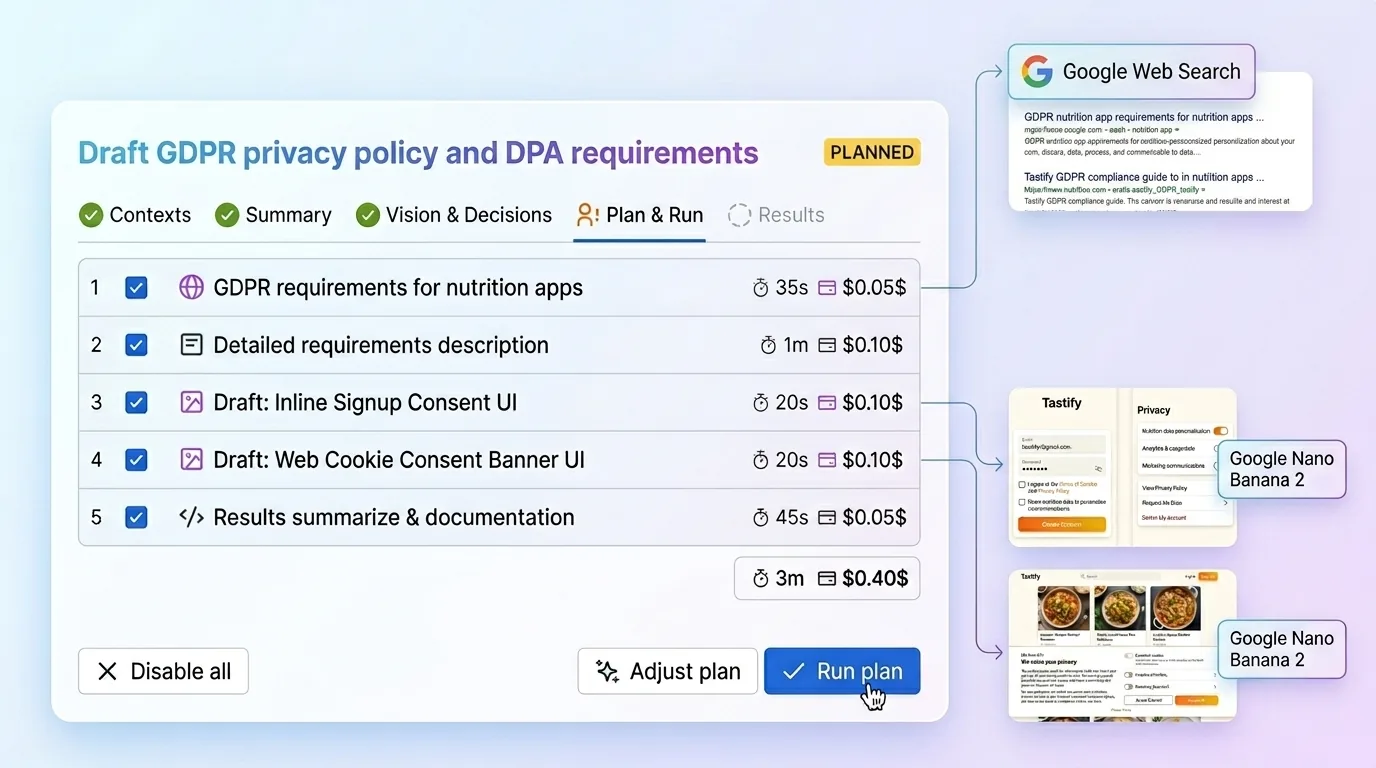
这正是我在 Just: AI Assistant for Jira 里搭建的流程:
- 先把项目上下文一次性设好,用四个结构化字段来保存:产品摘要、设计系统、受众和技术栈。Just 甚至会给出一组提示,你可以把它们交给 Claude Code 或任何编程代理,让它直接从仓库里生成这些摘要。贴进去一次,后面的工单就都可以重复利用。
- 打开一张 Jira issue。不需要专门折腾提示词,也不需要每个任务都重新配置。Just 会把 issue 和你保存好的上下文一起读进去,给出真正被项目现实塑造过的洞察。然后它会追问澄清问题,这些问题不是空泛通用的,而是建立在你的产品、技术现实和团队设计语言之上的。
- 再来生成计划。Just 会把这些答案整理成需求、设计方向、边界情况、预期结果,以及团队真正可以照着执行的结构化路径。它也能在需要时补充最新的网页上下文,并且支持五家主流 AI 提供方,这样每个步骤都能选最合适的模型。重点不是“看起来像魔法”,而是帮助团队产出正确的东西,而不只是很快地产出点什么。完整流程可以在 aiapps.me 看到。
这会改变什么
所以,为什么大多数 Jira AI 工具不是缓解团队对齐问题,反而是在放大它?因为它们通常是在工单里已经塞进模糊性之后才介入,然后只是把这种模糊性包装得更完整、更像一份成品。
真正有杠杆的位置,其实更早。团队需要先把自己到底想要什么说清楚,把那些隐藏的决定在实现开始前暴露出来,再把足够的上下文交给 AI,让它在产品真实的形状里工作,而不是对着一份信息贫乏的说明瞎猜。
核心就是这一点。如果团队在开工前就清楚自己要什么,AI 就会变得真正有用。反过来,如果这一点没做到,输出依然可能看上去很惊艳,但你多半会在后面的返工里为这种混乱买单。