你的AI在猜你的产品
同样的提示词,同样的模型,截然不同的结果。差别不在于措辞的魔法,而在于模型在开始生成之前是否了解你的产品、你的用户、你的设计语言和你的技术栈。

为什么输出差距这么大
同一个提示词,发给同一个模型,相隔六十秒。
提示词:"为一个票单写验收标准:用户可以配置AI提供商设置。"
第一次尝试——没有上下文:输出是一份通用清单。"用户可以从下拉菜单中选择AI提供商。用户可以保存设置。用户看到确认消息。"可以是任何产品、任何平台、任何年代。没有什么错的地方,也没有什么有用的地方。
第二次尝试——带产品上下文:输出引用了Jira Cloud管理页面、Forge resolver权限、各提供商的API key验证(OpenAI、Anthropic、Google、Mistral、xAI)、组织级别vs项目级别的数据范围行为,以及许可证控制的写入操作。它明确指出设置通过@forge/sql持久化,界面使用带有xcss token的Atlaskit组件。读起来像是真正在这个代码库工作过的人写的。
模型没有变。温度没有变。变的是输入。这个差距——从通用到有据可查——就是本文的全部主题。
当AI输出看起来不一致时,本能反应是怪模型:换提供商、升级套餐、调整温度。几乎每次,这都是错误的杠杆。
每个提示词都从零开始。模型对你的产品、用户、限制或上次对话没有任何记忆,除非你明确提供这些信息。"写验收标准"对一个服务十到一百人工程团队的Jira原生Forge应用意味着完全不同的东西,和一个消费类移动健身应用完全不同。
模型响应你描述的世界。如果你什么都不描述,它会自己发明一个——而那几乎不是你的。
这就是为什么同一团队中两个人可以使用同一模型却得到截然不同的结果。不是技能问题,不是提示词结构问题。是模型是否获得了足够多的产品真实情况来工作。
关于为什么这在Jira中会导致如此昂贵的错误,可以从这里开始了解更大的框架:AI无法修复失调的团队,它只会掩盖问题。
解决方法不是更好的提示词技巧。而是建立一个可重用的上下文层——对你产品世界的简洁、诚实的描述——并在每次提示前附加它。写一次,到处复用。模型停止猜测,开始以与你团队相同的约束工作。
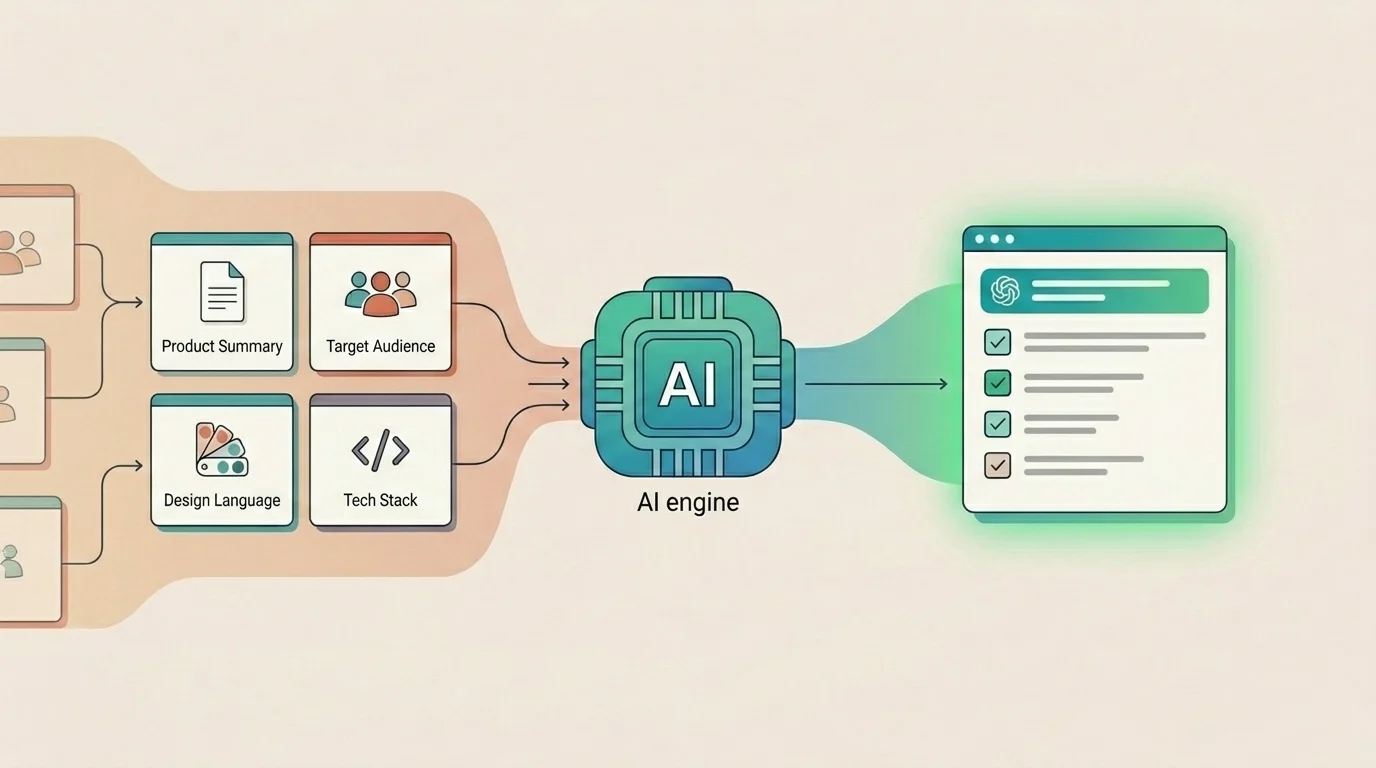
四个层次
产品上下文不是一段文字。它清晰地分解为四个层次,每个层次承担不同的工作。
- 产品摘要涵盖产品做什么、为谁做、什么结果重要——是运营真相,不是营销文案。差别很重要。"面向团队的项目管理工具"可以描述任何东西。"Just是为Jira Cloud上的产品和工程团队打造的Jira原生AI副驾驶。核心任务:将模糊的Jira issue转化为结构化执行计划——澄清问题、逐步计划以及回写到Jira字段——无需离开issue面板。不是聊天机器人,不是独立工具,基于Atlassian Forge构建。"描述的是唯一一个产品。
- 受众涵盖用户是谁、他们需要什么、他们期望什么以及他们不知道什么。
- 设计语言涵盖视觉模式、组件库、交互习惯以及从不做的事情。
- 技术栈和限制涵盖真实的框架、运行时限制、集成以及明确禁止的选择。
每个字段的差版本适用于数千个产品。好的版本恰好适用于一个。这是检验标准。
受众是通用上下文失效的地方
受众通常是团队首先过度简化的字段。"产品经理和开发人员"听起来合理,但也太模糊,无法帮助模型做出更好的判断。
有用的受众字段对团队规模、AI熟悉度、信任期望以及用户不想要什么都有明确说明。对Just而言,这意味着Jira Cloud团队中拥有10到100人的PM和高级工程师,具有中等AI熟悉度,自己管理API密钥,更关心可靠的输出而不是华丽的输出。
"不适用于"这一行同样重要。说明这不适合Jira Cloud以外的团队,也不适合想要完全自主代理的用户,会在错误假设出现之前排除整类错误假设。
这就是让上下文显得有根基而非装饰性的原因。模型不只是被告知用户是谁,同时还被解释了该用户在哪个世界中运作,以及哪些类型的工作流会感觉不对。
提取已有的内容
大多数团队已经拥有所有四个层次的上下文——只是分散在代码库、设计文件、文档和团队记忆中,而不是以AI能使用的形式存在。
**从代码库:**将编码代理——Claude Code、Codex或类似工具——指向你的代码库,请它生成一份markdown摘要,涵盖产品目的、技术栈、实现边界和已知限制。结构良好的代码库在几分钟内就能产出可用的初稿。
**从设计文件:**确定组件库的名称,找出产品依赖的三到五个关键交互模式,以及UI从不做的三件事。反模式和模式同样重要。
**从现有文档:**入职笔记、README文件、内部简报或营销上下文都可以提供产品摘要和受众定义的片段。它们不需要完美就能有用。
**从自己的脑子里:**如果以上内容都还不存在,现在打开一个空文档,为每个字段写一段话。会有缺陷。不完美的上下文远远胜过没有上下文。
你不需要完美的文档。你需要的是对产品所在世界的简洁、诚实的描述。
存储一次,到处复用
上下文只有在可复用时才能产生价值。写一次并粘贴到单个会话中对那次会话有帮助。让它持久化对每次会话都有帮助。
- **在Just中,**管理面板为这四个上下文字段各有一个专属区域——产品摘要、受众、设计语言和技术栈。每个项目将内容粘贴到每个字段一次。该项目中所有未来的洞察、澄清、计划和执行步骤都会自动以此上下文为基础。
- **如果你不使用Just,**在代码库根目录或共享文档中创建一个
context.md文件。按照同样的四个部分来组织它。在任何AI会话开始时粘贴它——编码助手、聊天工具、文档生成器。格式没有习惯重要:上下文先行,然后才是提示词。
将你的上下文层视为活文档,而不是上线那天的产物。当产品发生重大变化时再修订它——新集成、重大受众转变、设计系统迁移。不要每个sprint都修订。如果你的产品摘要每两周就变一次,那它就不是产品摘要——而是会议记录。

上下文不是提示词工程
产品上下文不是提示词工程。不是技巧,不是模板,也不是聪明的hack。它是给模型提供同样的简报——就像你第一天给新外包人员的那种:这是我们在做什么、为谁做、应该是什么样子、运行在什么上面。
做过这件事一次——并持续复用——的团队,得到的输出感觉像是来自真正理解产品的人。因为在所有功能意义上,确实如此。模型没有变聪明。你只是停止让它猜了。