Twoje AI po prostu zgaduje twój produkt
Ten sam prompt, ten sam model, zupełnie inny wynik. Różnica nie tkwi w magii sformułowania. Tkwi w tym, czy model zna twój produkt, twoich użytkowników, twój język designu i twój stack przed rozpoczęciem generowania.

Dlaczego wyniki tak bardzo się różnią
Ten sam prompt, wysłany do tego samego modelu, w odstępie sześćdziesięciu sekund.
Prompt: „Napisz kryteria akceptacji dla ticketu: użytkownik może konfigurować ustawienia dostawcy AI."
Pierwsza próba — bez kontekstu: wynik to ogólna lista punktów. „Użytkownik może wybrać dostawcę AI z listy rozwijanej. Użytkownik może zapisać ustawienia. Użytkownik widzi komunikat potwierdzający." Mogłoby to być dowolny produkt, dowolna platforma, dowolna dekada. Nie ma w tym nic złego. Nie ma też nic użytecznego.
Druga próba — z kontekstem produktu: wynik odwołuje się do stron administratora Jira Cloud, uprawnień Forge resolvera, walidacji kluczy API dla każdego dostawcy (OpenAI, Anthropic, Google, Mistral, xAI), zachowania zakresu danych na poziomie organizacji vs. projektu oraz akcji zapisu warunkowanych licencją. Precyzuje, że ustawienia są przechowywane przez @forge/sql i że interfejs używa komponentów Atlaskit z tokenami xcss. Brzmi jak napisane przez kogoś, kto faktycznie pracował w tej bazie kodu.
Model się nie zmienił. Temperatura się nie zmieniła. Zmienił się wejściowy kontekst. Ta przepaść — między ogólnym a zakorzenionym — to cały temat tego artykułu.
Kiedy wyniki AI wydają się niespójne, instynkt podpowiada, żeby winić model: zmienić dostawcę, podnieść tier, dostroić temperaturę. Prawie zawsze to zła dźwignia.
Każdy prompt zaczyna od zera. Model nie ma żadnej pamięci o twoim produkcie, twoich użytkownikach, ograniczeniach ani ostatniej rozmowie — chyba że jawnie przekażesz te informacje. „Napisz kryteria akceptacji" oznacza coś zupełnie innego dla natywnej aplikacji Jira opartej na Forge, obsługującej zespoły inżynierów liczące od dziesięciu do stu osób, a czym innym dla konsumenckiej mobilnej aplikacji fitness.
Model odpowiada na świat, który mu opisujesz. Jeśli nic nie opisujesz, wymyśla własny — i rzadko kiedy jest to twój.
Dlatego dwie osoby w tym samym zespole mogą używać tego samego modelu i uzyskiwać zupełnie różne wyniki. To nie jest kwestia umiejętności. Nie chodzi o strukturę promptu. Chodzi o to, czy model dostał wystarczająco dużo produktowej rzeczywistości, z którą może pracować.
Żeby zrozumieć szerszy kontekst tego, dlaczego powoduje to tak drogie błędy w Jira, zacznij od: AI nie naprawia źle ustawionych zespołów. Ukrywa je.
Rozwiązaniem nie jest lepsza technika promptowania. Jest nią zbudowanie wielokrotnie używalnej warstwy kontekstu — zwięzłego, rzetelnego opisu świata twojego produktu — i dołączanie go przed każdym promptem. Piszesz raz. Używasz wszędzie. Model przestaje zgadywać i zaczyna pracować z tymi samymi ograniczeniami, z którymi pracuje twój zespół.
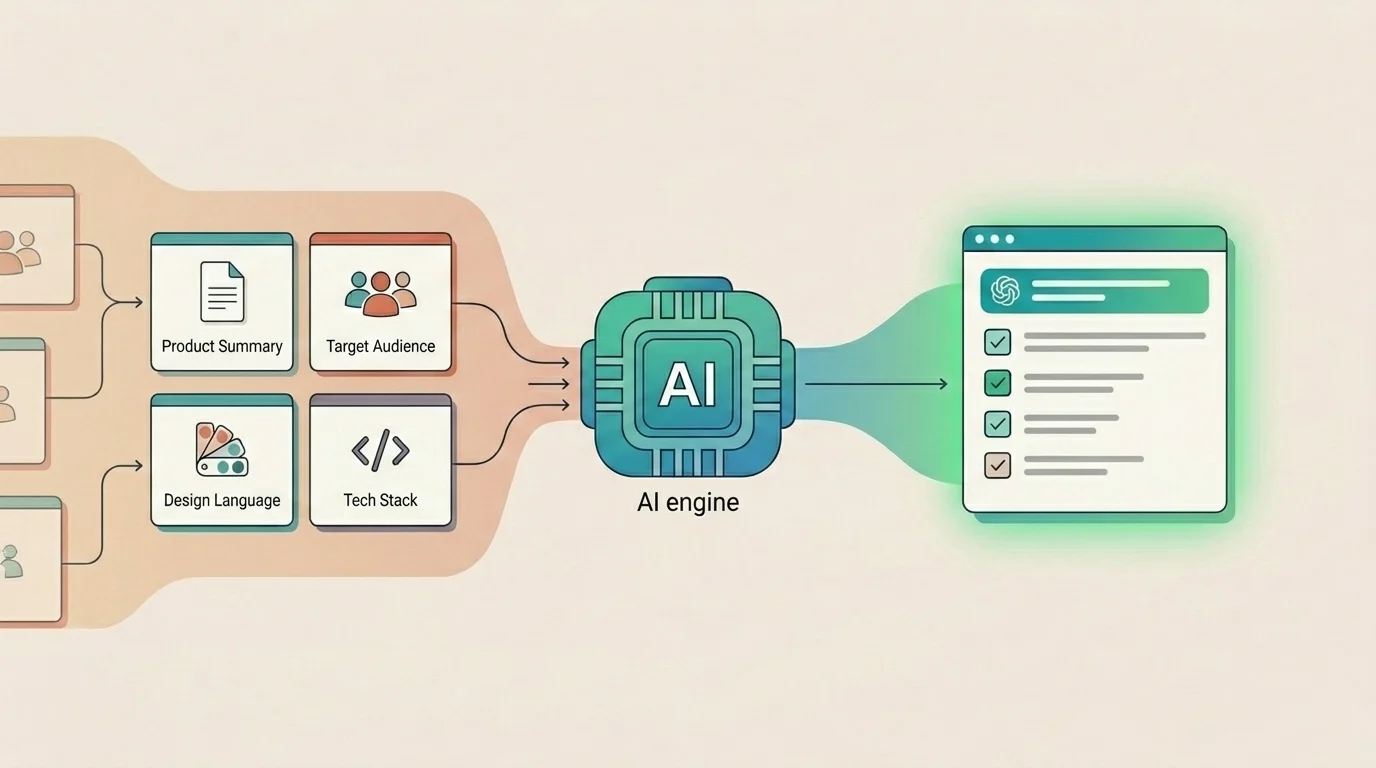
Cztery warstwy
Kontekst produktu to nie jeden duży blok tekstu. Naturalnie rozpada się na cztery warstwy, z których każda wykonuje inne zadanie.
- Opis produktu wyjaśnia, co produkt robi, dla kogo i jakie rezultaty są ważne — operacyjna prawda, nie tekst marketingowy. Różnica ma znaczenie. „Narzędzie do zarządzania projektami dla zespołów" mogłoby opisywać cokolwiek. „Just to natywny dla Jira copilot AI dla zespołów produktowych i inżynieryjnych w Jira Cloud. Główne zadanie: zamieniać niejednoznaczne Jira issues w ustrukturyzowane plany realizacji — pytania wyjaśniające, plany krok po kroku i zapis z powrotem do pól Jira — nie wychodząc z panelu issue. Nie chatbot. Nie osobne narzędzie. Zbudowane na Atlassian Forge." opisuje dokładnie jeden produkt.
- Odbiorcy opisuje, kim są użytkownicy, czego potrzebują, czego oczekują i czego nie wiedzą.
- Język designu opisuje wzorce wizualne, bibliotekę komponentów, nawyki interakcji i rzeczy, których się nigdy nie robi.
- Stack i ograniczenia opisuje realne frameworki, limity środowiska uruchomieniowego, integracje oraz jawnie wykluczone wybory.
Zła wersja każdego pola pasuje do tysięcy produktów. Dobra pasuje dokładnie do jednego. To jest test.
Odbiorcy — miejsce, gdzie ogólny kontekst się sypie
Pole odbiorców jest zazwyczaj pierwszym, które zespoły nadmiernie upraszczają. „Product managerowie i deweloperzy" brzmi rozsądnie. Jest też zbyt mgliste, żeby pomóc modelowi podejmować lepsze decyzje.
Przydatne pole odbiorców jest konkretne co do składu zespołu, znajomości AI, oczekiwań dotyczących zaufania oraz tego, czego użytkownicy nie chcą. Dla Just oznacza to PM-ów i starszych inżynierów w zespołach Jira Cloud liczących 10–100 osób, z umiarkowaną znajomością AI, którzy sami zarządzają kluczami API i bardziej zależy im na wiarygodnym rezultacie niż efektownym.
Linia „Nie dla" jest równie ważna. Stwierdzenie, że produkt nie jest dla zespołów poza Jira Cloud ani dla użytkowników, którzy oczekują w pełni autonomicznych agentów, z góry eliminuje całe kategorie błędnych założeń.
Właśnie to sprawia, że kontekst jest zakorzeniony, a nie dekoracyjny. Model nie tylko dowiaduje się, kim jest użytkownik. Jednocześnie wyjaśnia mu się, w jakim świecie ten użytkownik działa i jakie rodzaje workflow byłyby dla niego nieodpowiednie.
Wyciągnij to, co już istnieje
Większość zespołów ma już wszystkie cztery warstwy kontekstu — są po prostu rozrzucone po bazie kodu, plikach projektowych, dokumentacji i pamięci zespołu, zamiast być w formie, z której AI może korzystać.
Z repozytorium: skieruj agenta do kodowania — Claude Code, Codex lub podobny — na swoją bazę kodu i poproś o podsumowanie w markdown obejmujące cel produktu, stack, granice implementacji i znane ograniczenia. Dobrze zorganizowane repo produkuje użyteczny pierwszy szkic w ciągu kilku minut.
Z plików projektowych: zidentyfikuj nazwę biblioteki komponentów, trzy do pięciu kluczowych wzorców interakcji, na których opiera się twój produkt, oraz trzy rzeczy, których interfejs nigdy nie robi. Anty-wzorce są równie ważne jak wzorce.
Z istniejącej dokumentacji: notatki onboardingowe, pliki README, wewnętrzne briefy lub kontekst marketingowy mogą dostarczyć fragmenty opisu produktu i definicji odbiorców. Nie muszą być doskonałe, żeby być przydatne.
Z własnej głowy: jeśli nic z powyższego jeszcze nie istnieje, otwórz pusty dokument i napisz teraz jeden akapit dla każdego pola. Będzie niedoskonały. Niedoskonały kontekst bije brak kontekstu zdecydowanie.
Nie potrzebujesz perfekcyjnej dokumentacji. Potrzebujesz zwięzłego, rzetelnego opisu świata, w którym żyje twój produkt.
Zapisz raz, używaj wszędzie
Kontekst przynosi efekty tylko wtedy, gdy jest wielokrotnego użytku. Napisać go raz i wkleić do jednej sesji pomaga tej sesji. Uczynienie go trwałym pomaga każdej sesji.
- W Just panel administracyjny ma dedykowaną sekcję dla każdego z czterech pól kontekstu — Opis produktu, Odbiorcy, Język designu i Stack. Wklejasz treść do każdego pola raz na projekt. Każdy przyszły insight, każde wyjaśnienie, każdy plan i każdy krok realizacji w tym projekcie jest automatycznie zakorzeniony w tym kontekście.
- Jeśli nie używasz Just, stwórz jeden plik
context.mdw katalogu głównym repozytorium lub w dokumentacji współdzielonej. Zorganizuj go według tych samych czterech sekcji. Wklejaj go na początku każdej sesji AI — asystenci do kodowania, narzędzia czatu, generatory dokumentów. Format ma mniejsze znaczenie niż nawyk: najpierw kontekst, potem prompt.
Traktuj warstwę kontekstu jak żywy dokument, nie jak artefakt z dnia premiery. Przeglądaj go, gdy produkt zmienia się znacząco — nowa integracja, istotna zmiana odbiorców, migracja systemu designu. Nie rób tego co sprint. Jeśli twój opis produktu zmienia się co dwa tygodnie, to nie jest opis produktu — to notatki ze spotkań.

Kontekst to nie inżynieria promptów
Kontekst produktu to nie inżynieria promptów. To nie trick, nie szablon ani sprytny hack. To danie modelowi tego samego briefingu, który dałbyś nowemu kontrahentowi pierwszego dnia: tu jest to, co budujemy, dla kogo, jak to powinno wyglądać i na czym działa.
Zespoły, które robią to raz — i konsekwentnie to wielokrotnie używają — otrzymują wyniki, które brzmią, jakby pochodziły od kogoś, kto naprawdę rozumie produkt. Bo w każdym funkcjonalnym sensie tak właśnie jest. Model nie stał się mądrzejszy. Po prostu przestałeś kazać mu zgadywać.