आपकी AI आपके प्रोडक्ट का अंदाज़ा लगा रही है
एक ही प्रॉम्प्ट, एक ही मॉडल, पूरी तरह अलग आउटपुट। फर्क शब्दों के जादू में नहीं है। फर्क इसमें है कि मॉडल जनरेट करना शुरू करने से पहले आपका प्रोडक्ट, आपके यूज़र, आपकी डिज़ाइन भाषा और आपका स्टैक जानता है या नहीं।

आउटपुट इतना अलग क्यों होता है
यहाँ एक ही प्रॉम्प्ट है, एक ही मॉडल को, साठ सेकंड के अंतर से भेजा गया।
प्रॉम्प्ट: "एक टिकट के लिए acceptance criteria लिखें: यूज़र AI provider settings configure कर सकता है।"
पहला प्रयास — बिना संदर्भ के: आउटपुट एक सामान्य checklist है। "यूज़र dropdown से AI provider select कर सकता है। यूज़र settings save कर सकता है। यूज़र confirmation message देखता है।" यह किसी भी प्रोडक्ट, किसी भी प्लेटफ़ॉर्म, किसी भी दशक का हो सकता है। इसमें कुछ गलत नहीं है। इसमें कुछ उपयोगी भी नहीं है।
दूसरा प्रयास — प्रोडक्ट संदर्भ के साथ: आउटपुट Jira Cloud admin pages, Forge resolver permissions, प्रति provider API key validation (OpenAI, Anthropic, Google, Mistral, xAI), org vs project level पर data-scope behavior, और license-gated write actions का संदर्भ देता है। यह specify करता है कि settings @forge/sql के ज़रिए persist होती हैं और UI xcss tokens के साथ Atlaskit components इस्तेमाल करता है। यह ऐसा लगता है जैसे किसी ने इस codebase में वाकई काम किया हो।
मॉडल नहीं बदला। temperature नहीं बदला। इनपुट बदला। वह अंतर — सामान्य और ठोस के बीच — इस लेख का पूरा विषय है।
जब AI आउटपुट inconsistent लगता है, तो सहज प्रतिक्रिया मॉडल को दोष देना है: provider बदलें, tier upgrade करें, temperature ठीक करें। लगभग हमेशा, यह गलत lever है।
हर प्रॉम्प्ट शून्य से शुरू होता है। मॉडल को आपके प्रोडक्ट, यूज़र, limitations या पिछली बातचीत की कोई याद नहीं होती — जब तक आप यह जानकारी explicitly न दें। "Acceptance criteria लिखें" का मतलब दस से सौ लोगों की engineering teams के लिए Jira-native Forge app के लिए कुछ और होता है, और consumer mobile fitness tracker के लिए कुछ और।
मॉडल उस दुनिया पर respond करता है जो आप describe करते हैं। अगर आप कुछ describe नहीं करते, तो यह अपनी दुनिया बना लेता है — और वह शायद ही कभी आपकी होती है।
इसीलिए एक ही टीम के दो लोग एक ही मॉडल का उपयोग करके बिल्कुल अलग परिणाम पा सकते हैं। यह skill की बात नहीं है। यह prompt structure की बात नहीं है। यह इसकी बात है कि मॉडल को काम करने के लिए पर्याप्त product reality मिली या नहीं।
यह Jira में इतनी महंगी गलतियाँ क्यों करता है, इसकी बड़ी तस्वीर के लिए यहाँ से शुरू करें: AI misaligned teams को ठीक नहीं करती। वह उन्हें छुपाती है।
समाधान बेहतर prompting technique नहीं है। यह एक reusable context layer बनाना है — आपके प्रोडक्ट की दुनिया का एक संक्षिप्त, ईमानदार description — और इसे हर प्रॉम्प्ट से पहले संलग्न करना। एक बार लिखें। हर जगह reuse करें। मॉडल अंदाज़ा लगाना बंद कर देता है और उन्हीं constraints के साथ काम करना शुरू करता है जो आपकी टीम के पास हैं।
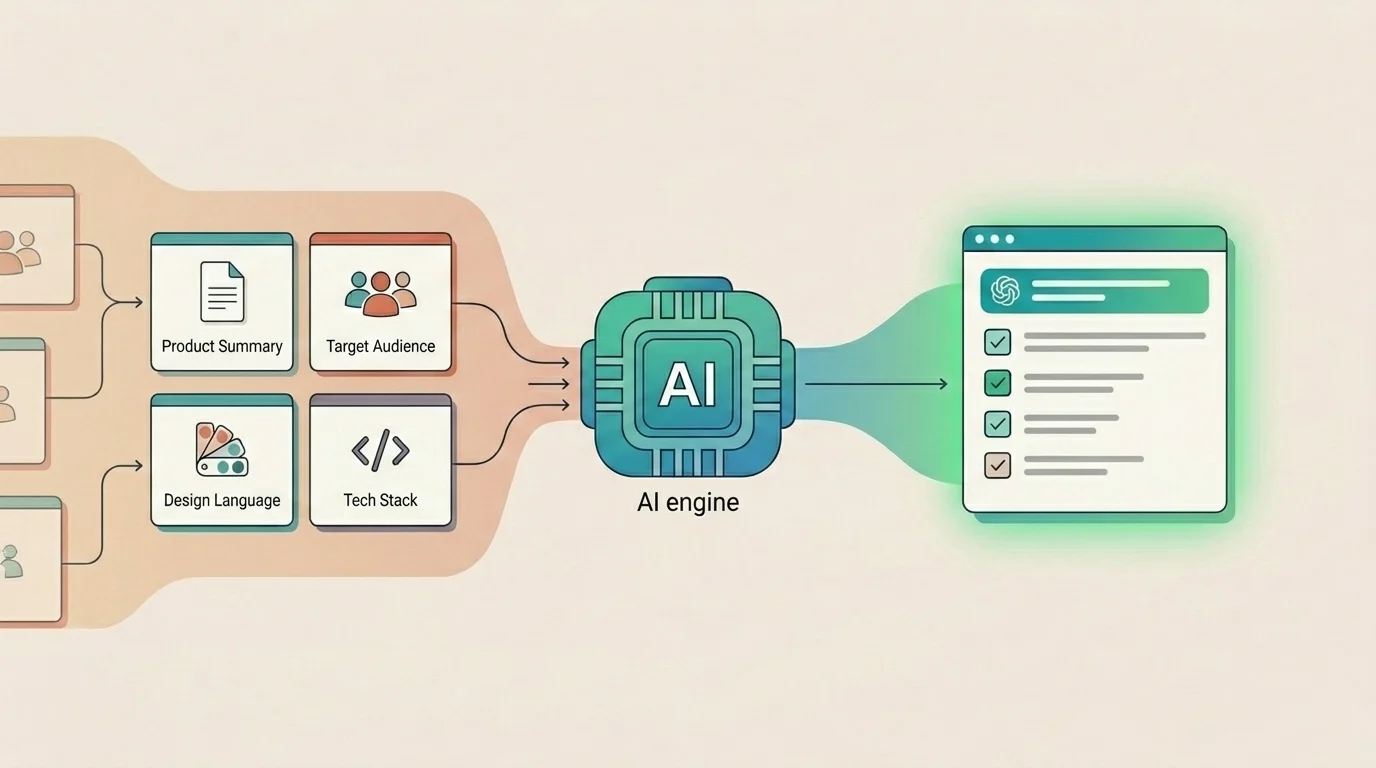
चार layers
प्रोडक्ट संदर्भ टेक्स्ट का एक blob नहीं है। यह साफ़ तरह से चार layers में टूटता है, जिनमें से प्रत्येक अलग काम करता है।
- Product Summary बताता है कि प्रोडक्ट क्या करता है, किसके लिए, और कौन से results मायने रखते हैं — operational truth, न कि marketing copy। फर्क मायने रखता है। "Teams के लिए project management tool" कुछ भी हो सकता है। "Just Jira Cloud पर product और engineering teams के लिए Jira-native AI copilot है। Core job: अस्पष्ट Jira issues को structured execution plans में बदलना — clarifications, step-by-step plans, और Jira fields में वापस apply — issue panel छोड़े बिना। Chatbot नहीं। Standalone tool नहीं। Atlassian Forge पर बना।" यह बिल्कुल एक प्रोडक्ट describe करता है।
- Audience बताता है कि यूज़र कौन हैं, उन्हें क्या चाहिए, वे क्या expect करते हैं, और वे क्या नहीं जानते।
- Design Language visual patterns, component library, interaction habits, और वे चीज़ें जो आप कभी नहीं करते, को cover करता है।
- Stack और Constraints असली frameworks, runtime limits, integrations, और explicitly off-limits choices को cover करता है।
हर field का बुरा version हज़ारों प्रोडक्ट पर fit होता है। अच्छा version ठीक एक पर fit होता है। यही test है।
Audience वह जगह है जहाँ generic context टूटता है
Audience आमतौर पर पहला field होता है जिसे teams बहुत ज़्यादा simplify करती हैं। "Product managers और developers" उचित लगता है। मॉडल को बेहतर judgments करने में मदद करने के लिए भी बहुत vague है।
एक useful audience field team shape, AI fluency, trust expectations, और यूज़र क्या नहीं चाहते, के बारे में specific होता है। Just के लिए, इसका मतलब है Jira Cloud teams of 10–100 में PMs और senior engineers, moderate AI fluency के साथ, जो अपने API keys खुद manage करते हैं और flashy output से ज़्यादा trustworthy output की परवाह करते हैं।
"Not for" line भी उतनी ही मायने रखती है। यह कहना कि यह Jira Cloud से बाहर की teams के लिए नहीं है या fully autonomous agents चाहने वाले यूज़र के लिए नहीं है, पूरे categories of wrong assumptions को पहले ही ख़त्म कर देता है।
यही context को decorative की बजाय grounded बनाता है। मॉडल को सिर्फ यह नहीं बताया जाता कि यूज़र कौन है। उसे यह भी explain किया जाता है कि वह यूज़र किस दुनिया में काम करता है और किस तरह के workflows गलत लगेंगे।
जो पहले से है उसे extract करें
ज़्यादातर teams के पास context के चारों layers पहले से होते हैं — वे बस codebases, design files, docs, और team memory में बिखरे हुए हैं, AI के उपयोग योग्य form में नहीं।
अपने repository से: एक coding agent — Claude Code, Codex, या similar — को अपनी codebase पर point करें और product purpose, stack, implementation boundaries, और known constraints को cover करने वाला markdown summary माँगें। एक well-structured repo मिनटों में उपयोग योग्य first draft दे देती है।
अपने design files से: component library का नाम, तीन से पाँच key interaction patterns जिन पर आपका प्रोडक्ट निर्भर है, और तीन चीज़ें जो UI कभी नहीं करता, identify करें। Anti-patterns उतने ही मायने रखते हैं जितने patterns।
Existing docs से: onboarding notes, README files, internal briefs, या marketing context सभी product summary और audience definition के fragments दे सकते हैं। वे useful होने के लिए perfect नहीं होने चाहिए।
अपने दिमाग से: अगर ऊपर से कुछ भी अभी exist नहीं करता, तो अभी एक blank document खोलें और हर field के लिए एक paragraph लिखें। यह imperfect होगा। Imperfect context no context से बहुत बेहतर है।
आपको perfect documentation की ज़रूरत नहीं है। आपको उस दुनिया का एक compact, honest description चाहिए जिसमें आपका प्रोडक्ट रहता है।
एक बार save करें, हर जगह reuse करें
Context तभी pay off करता है जब यह reusable हो। इसे एक बार लिखना और एक session में paste करना उस session की मदद करता है। इसे persistent बनाना हर session की मदद करता है।
- Just में, admin panel में इन चारों context fields — Product Summary, Audience, Design Language, और Stack — में से हर एक के लिए एक dedicated section है। अपना content हर field में एक बार per project paste करें। उस project का हर future insight, clarification, plan, और execution step automatically इस context से grounded होगा।
- अगर आप Just नहीं use करते, तो अपने repo के root में या shared docs में एक single
context.mdfile बनाएँ। इसे उन्हीं चार sections के साथ structure करें। इसे किसी भी AI session की शुरुआत में paste करें — coding assistants, chat tools, document generators। Format habit से कम मायने रखता है: पहले context, फिर prompt।
अपने context layer को living document की तरह treat करें, launch-day artifact की तरह नहीं। जब प्रोडक्ट significantly बदले — एक नया integration, एक major audience shift, एक design system migration — तब इसे review करें। हर sprint में review न करें। अगर आपका product summary हर दो हफ़्ते में बदलता है, तो वह product summary नहीं है — वह meeting notes हैं।

Context prompt engineering नहीं है
Product context prompt engineering नहीं है। यह कोई trick, template, या clever hack नहीं है। यह मॉडल को वही briefing देना है जो आप किसी नए contractor को पहले दिन देते: यहाँ बताएँ हम क्या बनाते हैं, किसके लिए, यह कैसा दिखना चाहिए, और यह किस पर चलता है।
जो teams यह एक बार करती हैं — और इसे consistently reuse करती हैं — उन्हें ऐसा output मिलता है जो ऐसा लगता है जैसे किसी ऐसे व्यक्ति ने लिखा जो प्रोडक्ट को सच में समझता है। क्योंकि हर functional sense में, वैसा ही है। मॉडल ज़्यादा smart नहीं हो गया। आपने बस इसे guess करना बंद कर दिया।