AI lost scheve afstemming in teams niet op. Het camoufleert die.
Deze hulpmiddelen lijken een bekend Jira-probleem op te lossen: vage tickets omzetten in iets waar je mee verder kunt. De valkuil is dat een verzorgd resultaat een team het gevoel kan geven dat het al op één lijn zit, terwijl dat nog niet zo is.

Het djinn-probleem
Er is één beeld waar ik steeds op terugkom als ik over AI nadenk. AI is een djinn. Die doet precies wat je zegt, niet wat je bedoelt. En juist in het gat tussen die twee dingen loopt verrassend veel productwerk vast.
Je kent de situatie. Iemand aan productkant houdt vier dingen tegelijk in de lucht en tikt in twee minuten een Jira-ticket uit. Dat ticket is niet expres slecht. Het is gewoon vaag, gehaast, onvolledig en vol aannames die nooit hardop zijn uitgesproken.
Engineering pakt het op, bouwt iets dat op basis van de tekst best logisch is, en twee weken later zit iedereen in een review een versie van hetzelfde te zeggen: dit bedoelde ik niet.
Niemand loog. Niemand werkte slordig. De bedoeling werd gewoon nooit expliciet genoeg voordat het werk begon. Met AI wordt dat probleem nog scherper, omdat het model niet over die impliciete teamcontext beschikt om de gaten op te vullen. Als er bijna geen context in het ticket zit, werkt de djinn bijna uit het luchtledige.
Het zwakste artefact
Sta eens stil bij waar de echte productkennis eigenlijk zit. Je codebasis kent je architectuur, je naamgeving, je afhankelijkheden en je technische grenzen. Je ontwerpbestanden kennen je beeldtaal, interactiepatronen en keuzes die zo vaak zijn herhaald dat ze een systeem zijn geworden. Eerdere tickets en documentatie kennen de woordenschat van het team en de manier waarop jullie afwegingen doorgaans verwoorden.
Een Jira-ticket weet van bijna niets daarvan. Heel vaak is het het minst contextrijke artefact in de hele stapel. Dus als een team een ticket in een AI-hulpmiddel plakt en hoogwaardige output verwacht, vraagt het in feite om een uitstekend antwoord op basis van de minst informatieve invoer die beschikbaar is.
Daarom klinkt de uitkomst zo vaak aannemelijk en past die toch slecht. Acceptatiecriteria gaan uit van de verkeerde gebruiker. Ontwerpideeën dwalen af naar een beeldtaal die je nooit zou opleveren. Technische aanbevelingen negeren je stack, je manier van uitrollen of de omwegen die je team bewust niet neemt. De AI “faalt” niet. Ze doet gewoon haar best met een beroerde briefing.
Overtuigend klinkende onzin
De meeste AI-hulpmiddelen voor Jira volgen hetzelfde patroon. Je opent een issue. Je klikt op een knop. Je krijgt een beschrijving, acceptatiecriteria en misschien een opsplitsing in subtaken. Dat voelt productief, omdat het resultaat snel, netjes en gestructureerd oogt.
Meestal gaat het zo:
- issue openen;
- op de knop klikken;
- een strakke tekst, criteria en misschien subtaken terugkrijgen.
Maar structuur is nog geen afstemming. Als de invoer vaag en contextloos was, dan is de uitvoer alleen maar een zelfverzekerder klinkende versie van dezelfde dubbelzinnigheid. In de praktijk kan het hulpmiddel het probleem zelfs groter maken, omdat die verzorgde vorm mensen ontmoedigt om aannames nog ter discussie te stellen voordat de uitvoering begint.
Daar zit het stille gevaar: rommel erin, rommel eruit, behalve dat die rommel nu kopjes, opsommingen en een toon van zekerheid heeft. Een team kan tegelijk met meer vertrouwen en minder duidelijkheid de uitvoering ingaan.

Wat AI werkelijk nodig heeft
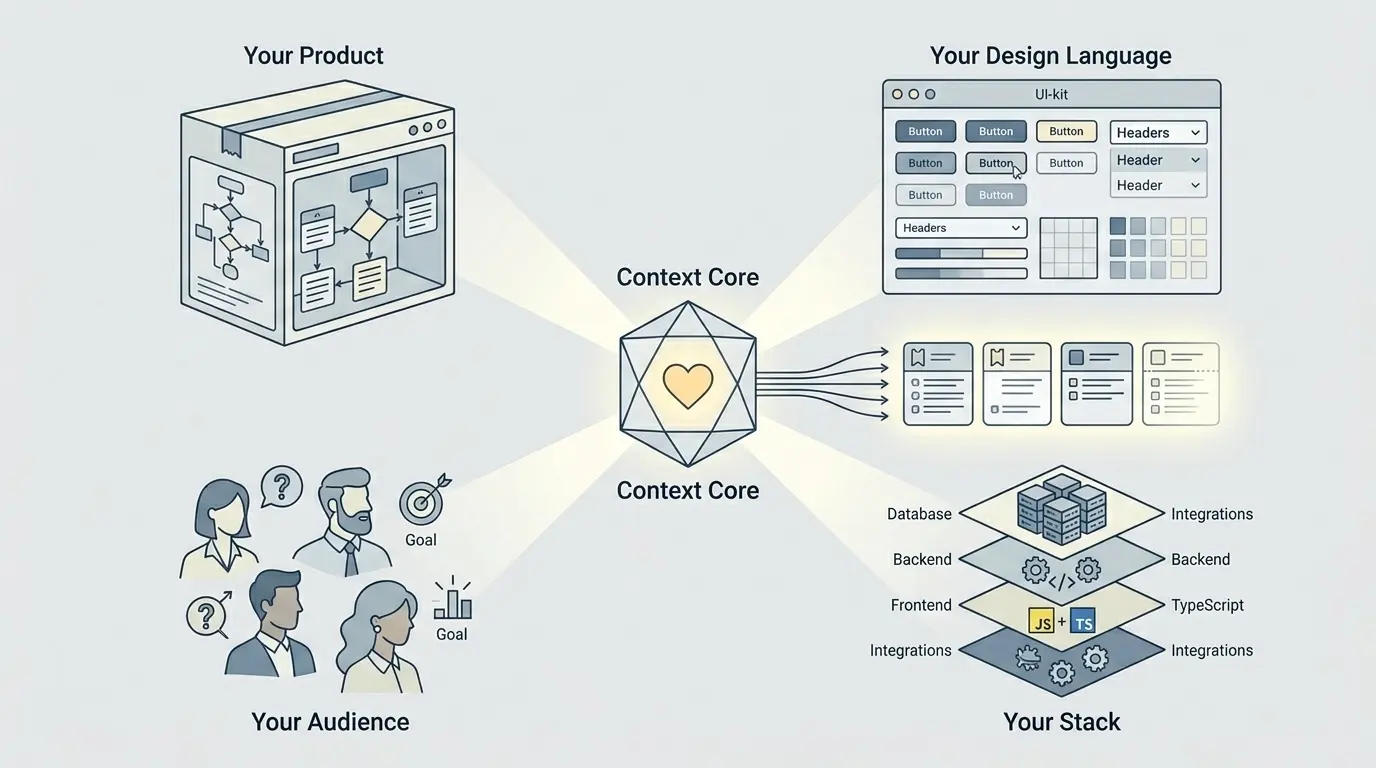
Voordat AI iets echt bruikbaars kan opleveren voor een Jira-issue, moet het vier dingen begrijpen over de wereld waarin het werkt:
- Je product: wat het doet, welke uitkomsten tellen en wat de functie moet verbeteren voor gebruikers en voor het bedrijf.
- Je ontwerptaal: visuele patronen, interfacebibliotheek en interactiegewoonten die ervoor zorgen dat de output aanvoelt als jouw product en niet als een willekeurige demo.
- Je doelgroep: wie die mensen zijn, wat ze nodig hebben, wat ze verwachten en wat ze niet weten. Dat verandert bewoordingen, interactie en randgevallen in bijna elke functie.
- Je stack: echte frameworks, uitvoeringsgrenzen, koppelingen, databeperkingen en technische grenzen die moeten bepalen wat überhaupt een zinvolle suggestie is.
Het interessante is dat de meeste teams dit allemaal al hebben. Het zit in code, documentatie, ontwerpen en teamgeheugen. Alleen bestaat het niet in Jira in een vorm die AI kan zien. Daarom zijn hulpmiddelen die alleen naar Jira kijken blind voor de belangrijkste context van het project.
Als je de praktische versie van zo’n contextlaag wilt zien, legt jouw AI gokt naar je product uit wat je moet opslaan en hoe je het opnieuw gebruikt.
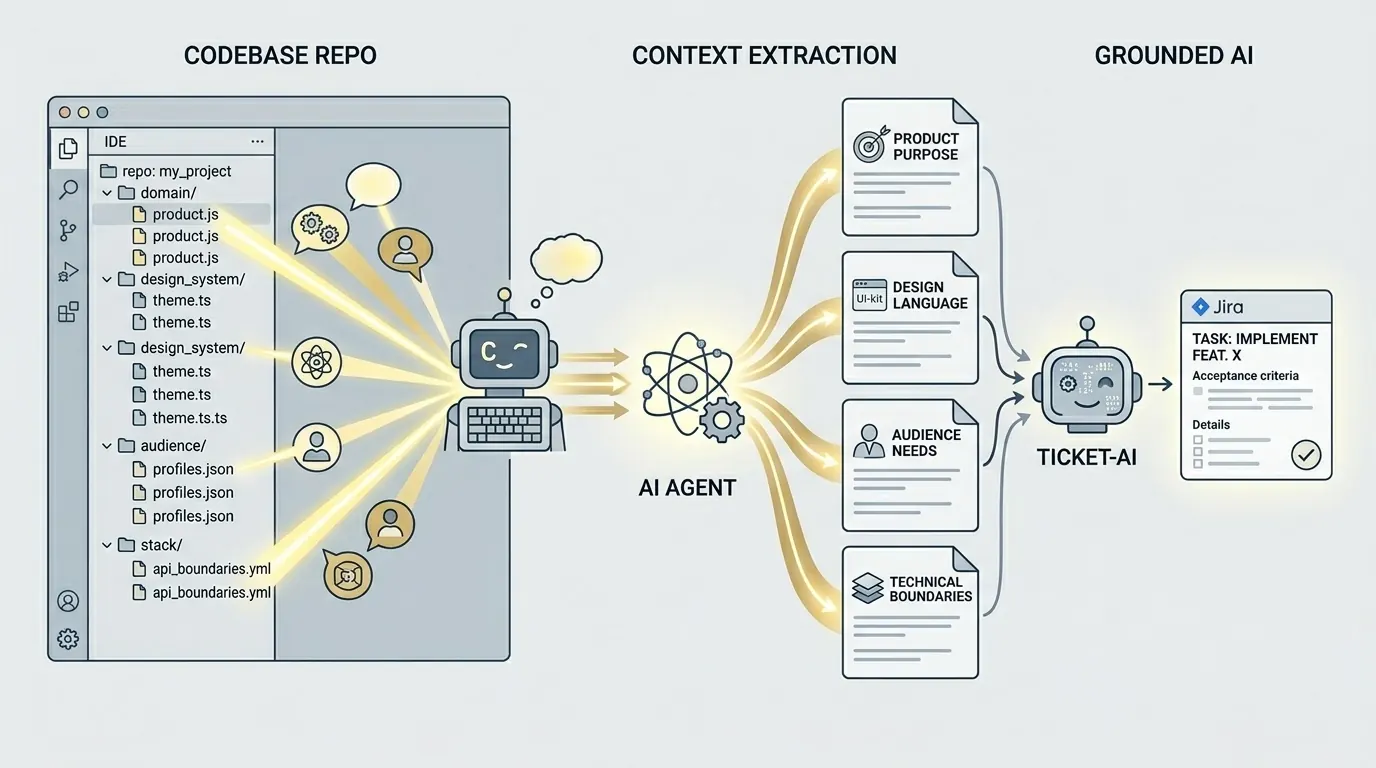
Je code weet meer
Een van de echt sterke punten van de huidige codeagenten is dat ze een repository heel goed kunnen lezen en omzetten in gewone taal. Je kunt Claude Code, Codex of een andere sterke codeagent op je repo zetten en vragen om een markdownsamenvatting van productdoel, stack, uitvoeringsgrenzen, bekende gaten en zakelijke signalen. Dat kost minuten, geen week documentatie.
En dat verandert de vergelijking. In plaats van AI iets te laten genereren vanuit een ticket van twee zinnen in het luchtledige, geef je een onderbouwde samenvatting van product, ontwerpsysteem, doelgroep en stack. Opeens improviseert het model niet meer in het donker. Het redeneert binnen een wereld die echt op jouw project lijkt.
Je codebasis had die antwoorden al die tijd al in zich. Componentnamen verraden de ontwerptaal. Domeinmodellen laten zien hoe het product denkt. Koppelingen en bibliotheken maken technische grenzen zichtbaar. Je hoeft context niet vanaf nul te verzinnen. Je moet die alleen naar een vorm brengen die een andere AI betrouwbaar kan gebruiken.
Verborgen beslissingen
Zelfs met uitstekende projectcontext blijft er een tweede probleem over dat AI niet kan oplossen door te raden: de beslissingen die nog niemand heeft genomen. In elk Jira-issue zitten verborgen aannames over rechten, uitrolregels, randgevallen, achterwaartse compatibiliteit, interactiedetails en zelfs over wat succes eigenlijk betekent zodra de functie echte gebruikers bereikt.
Die beslissingen verdwijnen niet zodra iemand aan het werk gaat. Ze komen alleen halverwege de sprint weer boven, en dat is zo ongeveer het duurste moment om ze te ontdekken. Een ontwerper vraagt welk bestaand scherm als referentie geldt. Een ontwikkelaar moet weten of er voor deze stroom al een API bestaat. Iemand merkt dat de acceptatiecriteria uitgingen van ingelogde gebruikers, terwijl de helft van de ervaring anoniem is. Achteraf is niets daarvan verrassend. Het zat er vanaf het begin al in.
Daarom is context alleen niet genoeg. Je hebt ook vragen nodig: concrete vragen, verankerd in zowel het ticket als de echte productcontext. Geldt dit voor bestaande gebruikers of alleen voor nieuwe? Wat gebeurt er als de browser halverwege sluit? Is deze functie alleen voor beheerders? Gaat het om een eenmalige handeling of terugkerend gedrag? Een korte reeks eerlijke antwoorden levert meer afstemming op dan nog een keurig opgepoetste specificatie.
Hoe dat in Just werkt
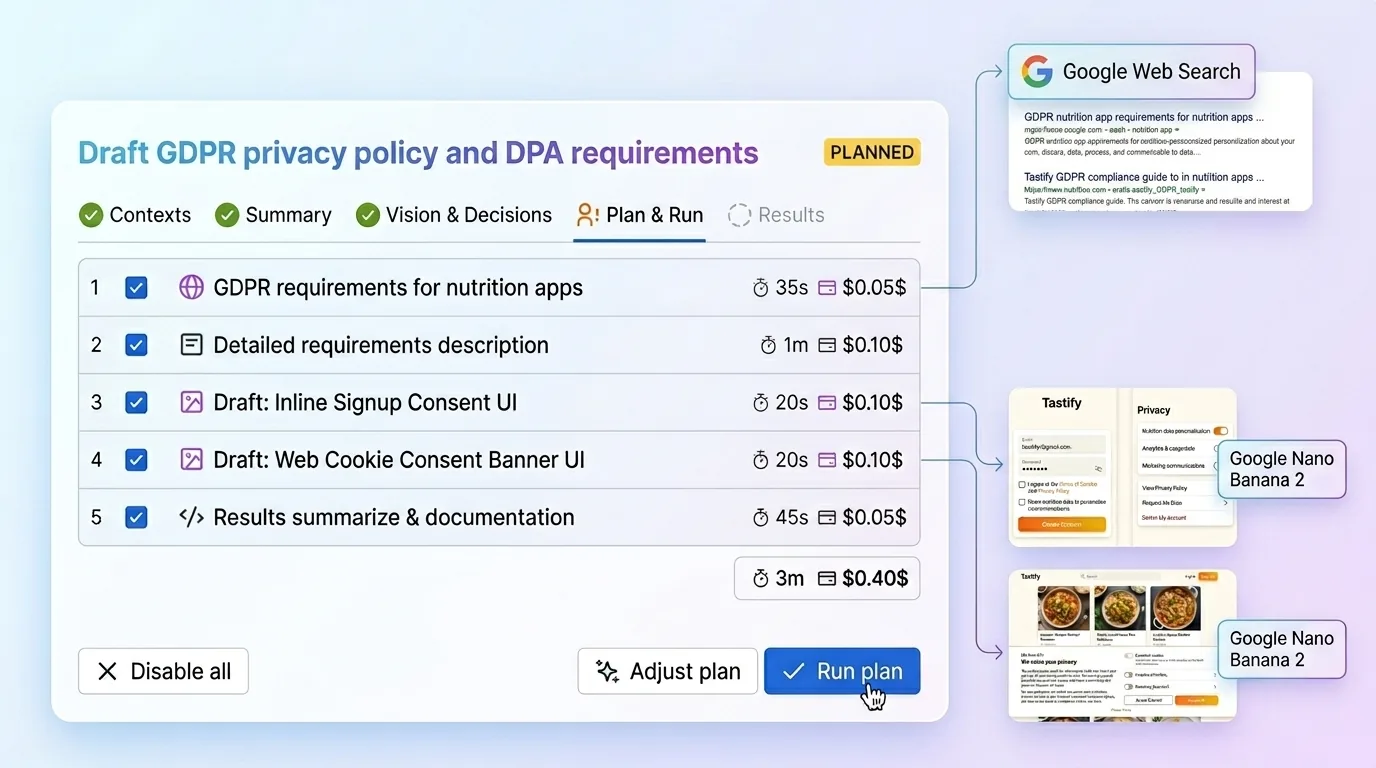
Dat is precies de werkwijze die ik in Just: AI Assistant for Jira heb ingebouwd:
- Je legt projectcontext één keer vast in vier gestructureerde velden: productsamenvatting, ontwerpsysteem, doelgroep en stack. Just geeft zelfs aanwijzingen die je door Claude Code of een andere codeagent kunt halen om die samenvattingen rechtstreeks uit je repository te laten maken. Je plakt het resultaat één keer in, en die context wordt daarna hergebruikt bij volgende tickets.
- Je opent een Jira-issue. Geen gepuzzel met prompts en geen extra inrichting per taak. Just leest het issue samen met de opgeslagen context en haalt inzichten naar boven die echt door jouw project zijn gevormd. Daarna stelt het verhelderende vragen die niet algemeen blijven, maar gegrond zijn in je product, je technische werkelijkheid en de ontwerptaal van je team.
- Je bouwt het plan. Just zet die antwoorden om in vereisten, ontwerprichting, randgevallen, verwachte uitkomsten en een gestructureerd uitvoeringspad waar het team mee kan werken. Het kan ook verse webcontext ophalen wanneer dat relevant is, en werkt met alle vijf grote AI-aanbieders zodat je per stap het best passende model kunt gebruiken. Het doel is niet om magisch te lijken. Het doel is om het team te helpen het juiste te maken, niet alleen iets snels. De volledige stroom vind je op aiapps.me.
Wat dat verandert
Waarom maken de meeste AI-hulpmiddelen voor Jira het afstemmingsprobleem dan groter in plaats van kleiner? Omdat ze meestal pas instappen nadat de dubbelzinnigheid al in het ticket zit, en die dubbelzinnigheid daarna vooral netjes en afgerond laten lijken.
De echte hefboom zit eerder. Eerst moet helder worden wat het team werkelijk wil, moeten verborgen beslissingen zichtbaar worden vóór de uitvoering begint, en moet AI genoeg context krijgen om binnen de echte vorm van het product te werken in plaats van te raden vanuit een karige omschrijving.
Daar draait het om. Als het team vóór de start goed begrijpt wat het wil, wordt AI nuttig. Zo niet, dan kan de output er nog steeds indrukwekkend uitzien, maar die verwarring betaal je later vrijwel zeker terug in herstelwerk.