KI behebt fehlende Abstimmung im Team nicht. Sie kaschiert sie.
Diese Tools scheinen ein bekanntes Jira-Problem zu lösen: vage Tickets in etwas Arbeitsfähiges zu verwandeln. Der Haken ist, dass ein sauber aufbereiteter Output Teams leicht das Gefühl gibt, schon abgestimmt zu sein, obwohl genau das noch fehlt.

Das Dschinn-Problem
Wenn ich über KI nachdenke, komme ich immer wieder auf dasselbe Bild zurück. KI ist ein Dschinn. Sie tut exakt das, was man sagt, nicht das, was man meint. Und genau in diesem Abstand zerbricht erstaunlich viel Produktarbeit.
Du kennst die Situation. Eine Produktperson jongliert vier Dinge gleichzeitig und tippt in zwei Minuten ein Jira-Ticket runter. Das Ticket ist nicht absichtlich schlecht. Es ist einfach vage, hastig, unvollständig und voller Annahmen, die nie laut ausgesprochen wurden.
Das Engineering-Team nimmt es auf, baut etwas Vernünftiges aus den vorhandenen Worten, und zwei Wochen später sitzen alle im Review und sagen irgendeine Variante von: So war das nicht gemeint.
Niemand hat gelogen. Niemand war nachlässig. Die eigentliche Absicht wurde nur nie klar genug gemacht, bevor die Arbeit begann. Mit KI wird dieses Problem noch härter, weil dem Modell jeder stillschweigende Teamkontext fehlt, um die Lücken zu schließen. Wenn im Ticket fast kein Kontext steckt, arbeitet der Dschinn fast aus dem Nichts.
Das schwächste Artefakt
Überleg einmal, wo das eigentliche Produktwissen wirklich liegt. Die Codebasis kennt eure Architektur, eure Benennungen, Abhängigkeiten und Umsetzungsgrenzen. Eure Design-Dateien kennen die visuelle Sprache, Interaktionsmuster und Entscheidungen, die ihr so oft wiederholt habt, dass daraus ein System geworden ist. Frühere Tickets und Dokumentation kennen den Wortschatz des Teams und die Art, wie ihr üblicherweise Zielkonflikte beschreibt.
Ein Jira-Ticket weiß von alledem fast nichts. Oft ist es das kontextärmste Artefakt im ganzen Stack. Wenn ein Team also ein Ticket in ein KI-Tool kippt und hochwertige Ergebnisse erwartet, verlangt es im Grunde eine großartige Antwort auf Grundlage des informationsärmsten Inputs, den es hat.
Darum klingt der Output so oft plausibel und passt trotzdem schlecht. Akzeptanzkriterien gehen vom falschen Nutzer aus. Design-Ideen driften in eine Bildsprache, die ihr nie ausliefern würdet. Technische Empfehlungen ignorieren euren Stack, euer Betriebsmodell oder Abkürzungen, die das Team ganz bewusst nicht nimmt. Die KI “versagt” nicht. Sie macht nur das Beste aus einem miserablen Briefing.
Selbstsicherer Unsinn
Die meisten KI-Tools für Jira folgen derselben Grundform. Issue öffnen. Knopf drücken. Beschreibung, Akzeptanzkriterien und vielleicht ein paar Unteraufgaben bekommen. Das fühlt sich produktiv an, weil das Ergebnis schnell, ordentlich und strukturiert wirkt.
Meistens sieht das so aus:
- Issue öffnen;
- auf den Knopf klicken;
- einen sauberen Textblock, Kriterien und vielleicht Unteraufgaben bekommen.
Aber Struktur ist nicht dasselbe wie Abstimmung. Wenn der Input vage und kontextfrei war, ist der Output nur eine selbstsicherer wirkende Variante derselben Unschärfe. In der Praxis kann das Tool das Problem sogar verschlimmern, weil die glatte Form Menschen davon abhält, Annahmen noch einmal zu hinterfragen, bevor die Umsetzung startet.
Genau darin liegt die stille Gefahr: Schrott rein, Schrott raus, nur dass der Schrott jetzt Überschriften, Aufzählungen und den Tonfall von Gewissheit hat. Ein Team kann mit mehr Zuversicht und gleichzeitig mit weniger Klarheit in die Umsetzung gehen.

Was KI tatsächlich braucht
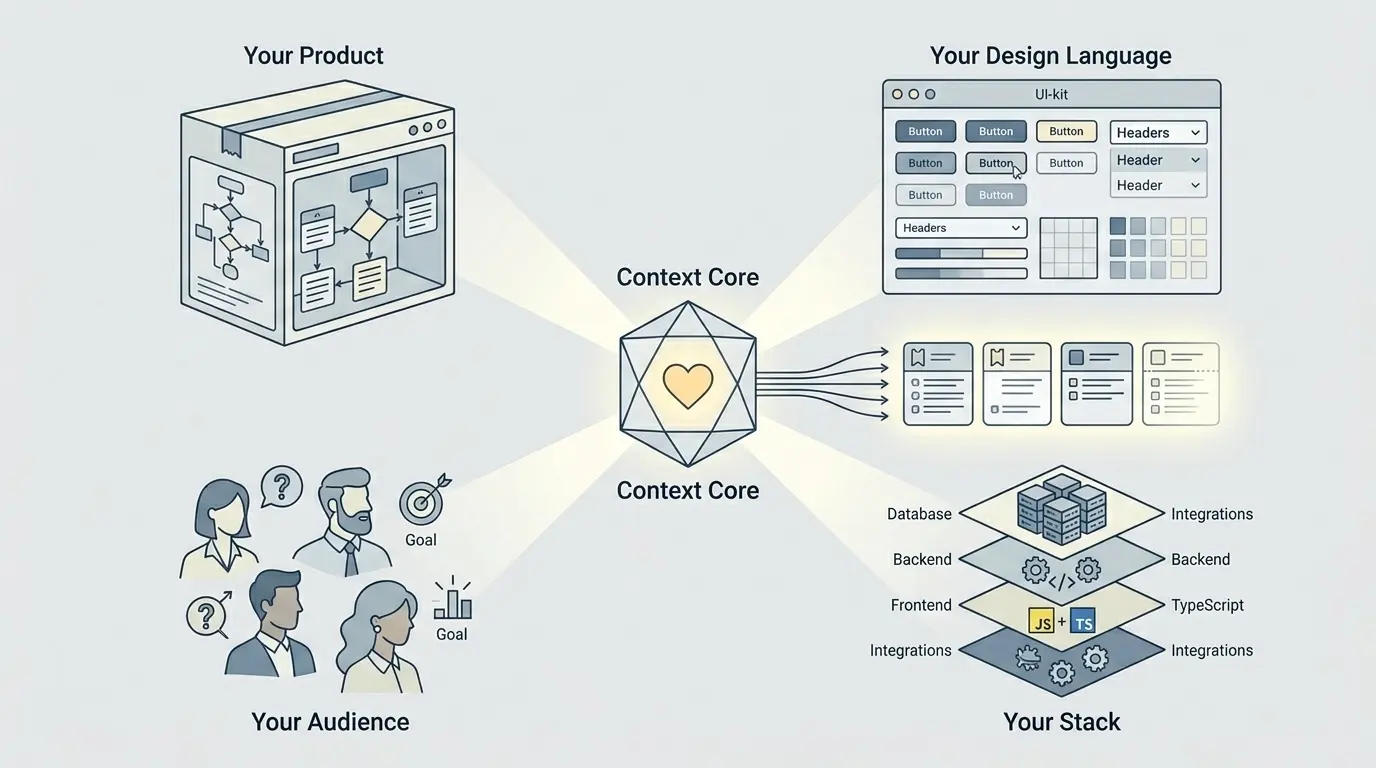
Bevor KI für ein Jira-Issue etwas wirklich Nützliches liefern kann, muss sie vier Dinge über die Welt verstehen, in der sie arbeitet:
- Euer Produkt: was es tut, welche Ergebnisse zählen und was die Funktion für Nutzer und Geschäft konkret verbessern soll.
- Eure Designsprache: visuelle Muster, UI-Bibliothek und Interaktionsgewohnheiten, die dafür sorgen, dass sich der Output nach eurem Produkt anfühlt und nicht nach einer austauschbaren Demo.
- Eure Zielgruppe: wer diese Menschen sind, was sie brauchen, was sie erwarten und was sie nicht wissen. Das verändert Formulierungen, Interaktionslogik und Randfälle in fast jeder Funktion.
- Euren Stack: echte Frameworks, Laufzeitgrenzen, Integrationen, Datenbeschränkungen und technische Grenzen, die bestimmen sollten, was überhaupt ein brauchbarer Vorschlag ist.
Das Interessante ist: Die meisten Teams haben all das längst. Es steckt im Code, in Dokumenten, Mockups und im Kopf der Beteiligten. Nur in Jira liegt es nicht in einer Form vor, die KI sehen kann. Darum sind Werkzeuge, die nur auf Jira schauen, blind für den wichtigsten Projektkontext.
Wenn du die praktische Version dieser Kontextschicht sehen willst, erklärt Deine KI rät bei deinem Produkt nur herum, was man speichern und wie man es wiederverwenden sollte.
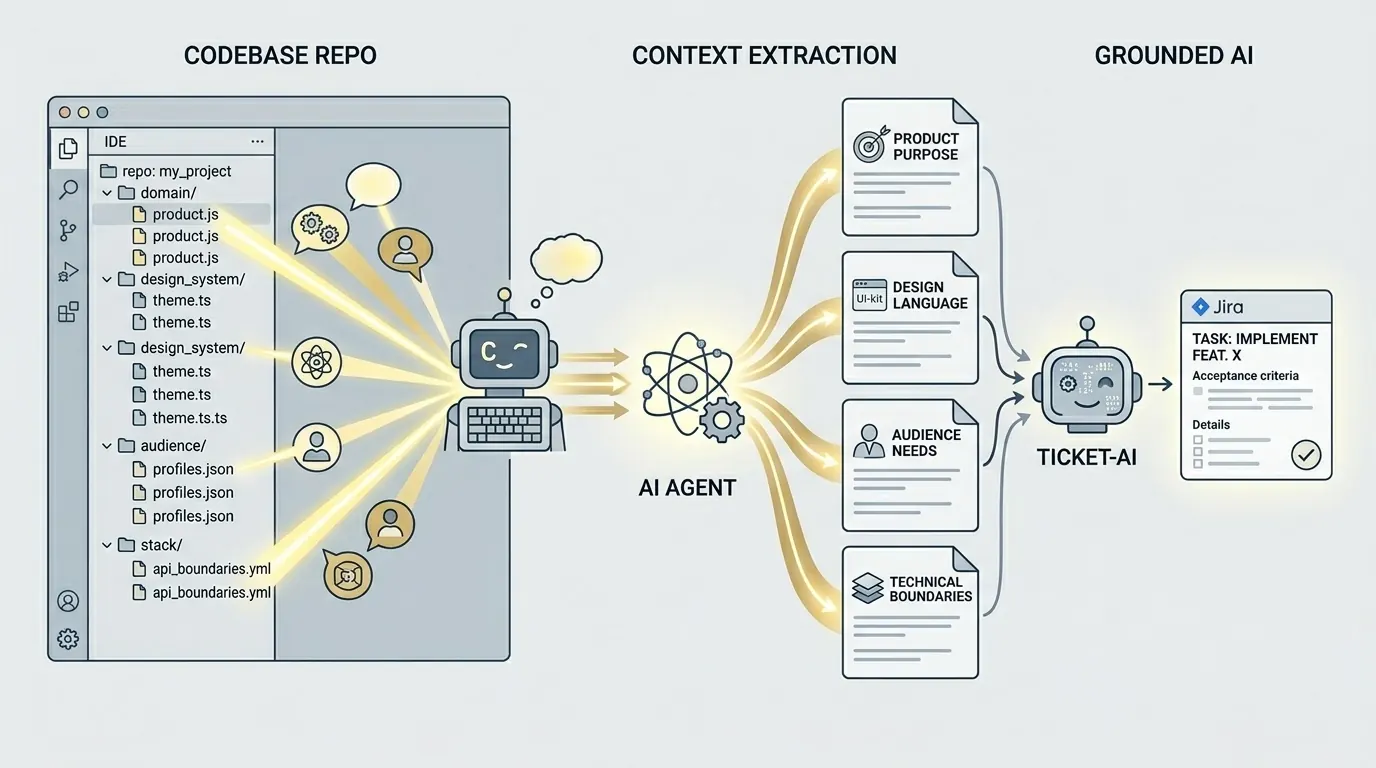
Euer Code weiß mehr
Eine der wirklich spannenden Stärken heutiger Coding-Agenten ist, dass sie ein Repository sehr gut lesen und in verständlichen Kontext übersetzen können. Man kann Claude Code, Codex oder einen anderen starken Agenten auf das Repo ansetzen und um eine Markdown-Zusammenfassung zu Produktzweck, Stack, Umsetzungsgrenzen, bekannten Lücken und Geschäftssignalen bitten. Das dauert Minuten und kein wochenlanges Dokumentationsprojekt.
Und damit verändert sich die Gleichung. Statt KI aus einem Zwei-Satz-Ticket im luftleeren Raum generieren zu lassen, gibst du ihr eine fundierte Zusammenfassung zu Produkt, Designsystem, Zielgruppe und Stack. Plötzlich improvisiert das Modell nicht mehr im Dunkeln. Es denkt innerhalb einer Welt, die eurem Projekt tatsächlich ähnelt.
Die Codebasis trägt diese Antworten längst in sich. Komponentennamen zeigen die Designsprache. Domänenmodelle verraten, wie das Produkt denkt. Integrationen und Bibliotheken markieren technische Grenzen. Man muss Kontext nicht aus dem Nichts erfinden. Man muss ihn nur in ein Format überführen, das eine andere KI verlässlich nutzen kann.
Versteckte Entscheidungen
Selbst mit hervorragendem Projektkontext bleibt ein zweites Problem, das KI nicht erraten kann: Entscheidungen, die noch niemand getroffen hat. In jedem Jira-Issue stecken verborgene Annahmen über Berechtigungen, Rollout-Regeln, Randfälle, Abwärtskompatibilität, Interaktionsdetails und darüber, woran man überhaupt erkennt, dass die Funktion bei echten Nutzern erfolgreich ist.
Diese Entscheidungen verschwinden nicht, sobald jemand mit der Umsetzung beginnt. Sie tauchen nur mitten im Sprint wieder auf, also genau dann, wenn ihre Entdeckung am teuersten ist. Eine Designerin fragt, welcher bestehende Screen als Referenz gilt. Ein Entwickler muss wissen, ob es für diesen Ablauf schon eine API gibt. Jemand merkt, dass die Akzeptanzkriterien von eingeloggten Nutzern ausgingen, obwohl die Hälfte der Erfahrung anonym abläuft. Nichts davon ist im Nachhinein überraschend. Es war die ganze Zeit da.
Darum reicht Kontext allein nicht. Es braucht auch Fragen: konkrete Fragen, die gleichzeitig im Ticket und im tatsächlichen Produktkontext verankert sind. Gilt das für bestehende Nutzer oder nur für neue? Was passiert, wenn der Browser mitten im Ablauf geschlossen wird? Ist die Funktion nur für Admins gedacht? Ist das eine einmalige Aktion oder wiederkehrendes Verhalten? Eine kurze Serie ehrlicher Antworten schafft mehr Abstimmung als noch eine sauber formulierte Spezifikation.
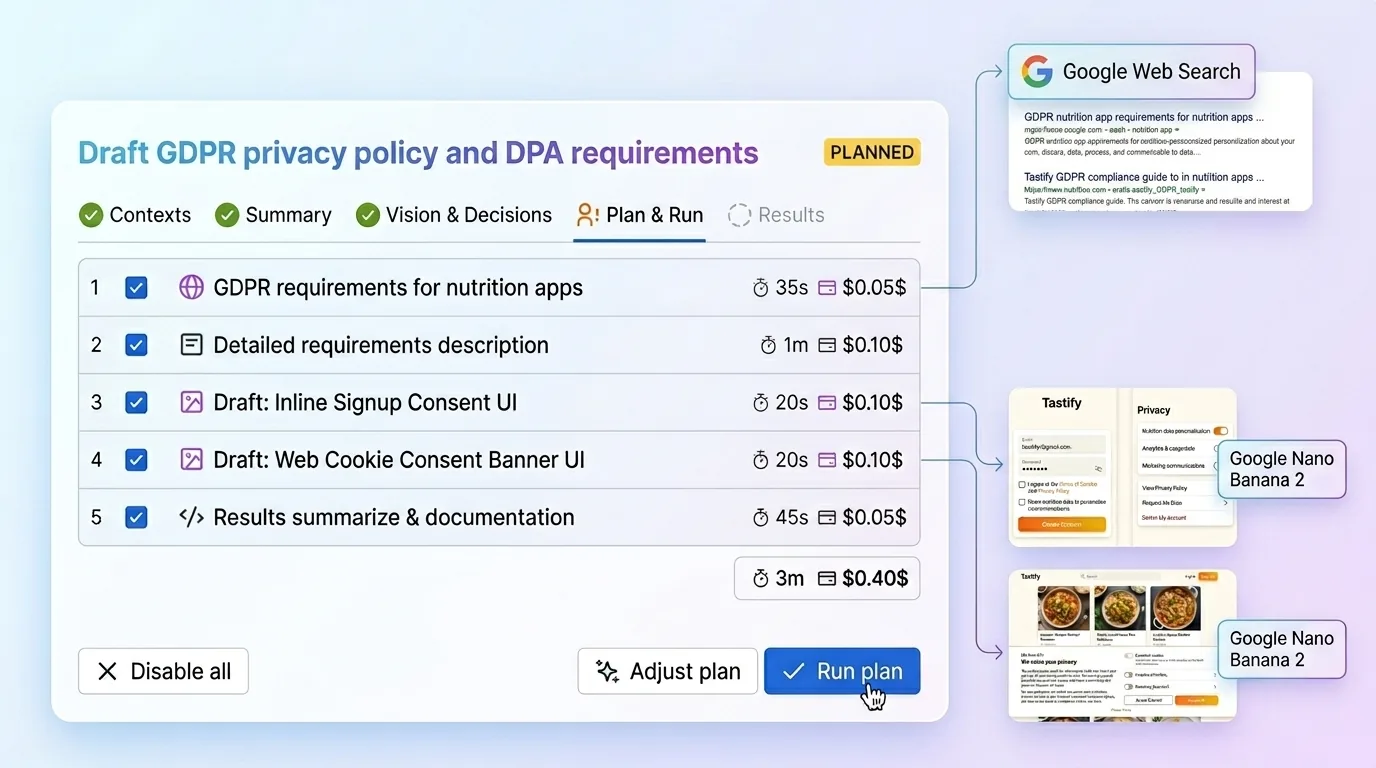
Wie das in Just funktioniert
Genau diesen Ablauf habe ich in Just: AI Assistant for Jira eingebaut:
- Projektkontext wird einmal über vier strukturierte Felder festgelegt: Produktzusammenfassung, Designsystem, Zielgruppe und Stack. Just liefert dafür sogar Anweisungen, die man durch Claude Code oder einen anderen Coding-Agenten laufen lassen kann, um diese Zusammenfassungen direkt aus dem Repository zu erzeugen. Das Ergebnis wird einmal eingefügt und anschließend für künftige Tickets wiederverwendet.
- Dann öffnet man ein Jira-Issue. Keine Prompt-Bastelei, keine Extra-Einrichtung pro Aufgabe. Just liest das Issue zusammen mit dem gespeicherten Kontext und bringt Erkenntnisse hervor, die tatsächlich von eurem Projekt geprägt sind. Danach stellt es Rückfragen, die nicht allgemein bleiben, sondern auf Produkt, technischer Realität und der Designsprache des Teams aufbauen.
- Danach entsteht der Plan. Just macht aus den Antworten Anforderungen, Designrichtung, Randfälle, erwartete Ergebnisse und einen strukturierten Ausführungspfad, mit dem das Team arbeiten kann. Bei Bedarf holt es frischen Web-Kontext dazu, und es funktioniert mit allen fünf großen KI-Anbietern, damit pro Schritt das passende Modell genutzt werden kann. Der Punkt ist nicht, magisch zu wirken. Der Punkt ist, dem Team zu helfen, das Richtige zu erzeugen und nicht bloß irgendetwas Schnelles. Den vollständigen Ablauf findest du auf aiapps.me.
Was sich dadurch ändert
Warum verschärfen also die meisten KI-Tools für Jira das Abstimmungsproblem eher, statt es zu lösen? Weil sie meist erst eingreifen, nachdem die Unschärfe schon im Ticket steckt, und dieser Unschärfe dann nur noch eine polierte, abgeschlossene Form geben.
Der eigentliche Hebel liegt früher. Das Team muss erst klar benennen, was es wirklich will, versteckte Entscheidungen vor der Umsetzung sichtbar machen und der KI genug Kontext geben, damit sie innerhalb der echten Form des Produkts arbeiten kann, statt aus einem dünnen Briefing heraus zu raten.
Darum geht es im Kern. Wenn das Team vor dem Start versteht, was es eigentlich will, wird KI nützlich. Wenn nicht, kann der Output immer noch beeindruckend aussehen, aber die Verwirrung zahlt ihr später sehr wahrscheinlich als Nacharbeit zurück.