ИИ не чинит рассинхрон. Он его прячет.
Эти инструменты как будто решают знакомую проблему Jira: превращают расплывчатые тикеты во что-то пригодное для работы. Но аккуратно оформленный результат часто создаёт ощущение, что команда уже договорилась, хотя на самом деле это не так.

Проблема джинна
Есть одна ментальная модель, к которой я постоянно возвращаюсь, когда думаю про ИИ. ИИ — это джинн. Он делает ровно то, что ты сказал, а не то, что ты имел в виду. И расстояние между этими двумя вещами — именно там, где удивительно часто разваливается разработка.
Ты знаешь этот сценарий. Продакт-менеджер жонглирует четырьмя вещами одновременно и за две минуты пишет тикет в Jira. Тикет не «плохой» специально. Он просто расплывчатый, спешный, неполный и забит допущениями, которые никто не проговорил вслух.
Разработка подхватывает его, строит что-то вполне разумное из тех слов, которые в тикете есть, а через две недели на разборе все говорят какую-то версию одной и той же фразы: «Я имел в виду не это».
Никто не врал. Никто не ленился. Просто замысел так и не стал достаточно явным до начала работы. В версии этой проблемы с ИИ всё ещё жёстче, потому что у модели нет живого командного контекста, чтобы заполнить пробелы. Если в задаче почти нет контекста, джинн работает почти из ничего.
Самый слабый артефакт
Подумай, где вообще живёт настоящее знание о продукте. Кодовая база знает твою архитектуру, именование, зависимости и границы реализации. Дизайн-файлы знают твой визуальный язык, паттерны взаимодействия и решения, которые ты повторял достаточно долго, чтобы они стали системой. Предыдущие тикеты и документация знают словарь команды и то, как вы обычно формулируете компромиссы.
Задача в Jira почти ничего из этого не знает. Очень часто это самый бедный по контексту артефакт во всём стеке. Поэтому, когда команда вставляет задачу в ИИ-инструмент и ждёт качественный результат, она фактически просит отличный ответ на самый бедный по информации вход из всех доступных.
Именно поэтому результат так часто звучит правдоподобно, но плохо ложится на реальность. Критерии приёмки предполагают не того пользователя. Дизайн-идеи уходят в визуальный стиль, который ты никогда бы не выпустил. Технические рекомендации игнорируют стек, модель развёртывания или те сокращения, которыми команда сознательно не пользуется. ИИ не «ошибается». Он просто делает лучшее, что можно сделать по плохому исходному описанию.
Уверенная бессмыслица
Большинство ИИ-инструментов для Jira устроены примерно одинаково. Открой задачу. Нажми кнопку. Получи описание, критерии приёмки, возможно разбиение на подзадачи. Ощущение продуктивности возникает потому, что результат выглядит структурированным, аккуратным и быстрым.
Обычно это выглядит так:
- открываешь задачу;
- нажимаешь кнопку;
- получаешь аккуратный текст, список критериев и, возможно, подзадачи.
Но структура — это не то же самое, что согласованность. Если на входе был расплывчатый текст без контекста, то на выходе получится просто более уверенная версия той же самой неоднозначности. На практике инструмент мог сделать проблему даже хуже, потому что аккуратное оформление теперь отучает людей ставить под вопрос исходные допущения до старта работы.
Вот здесь и сидит тихая опасность: мусор на входе, мусор на выходе — только теперь этот мусор выглядит как документ с заголовками, списками и интонацией уверенности. Команда может одновременно идти в реализацию и с большей уверенностью, и с меньшей ясностью.

Что на самом деле нужно ИИ
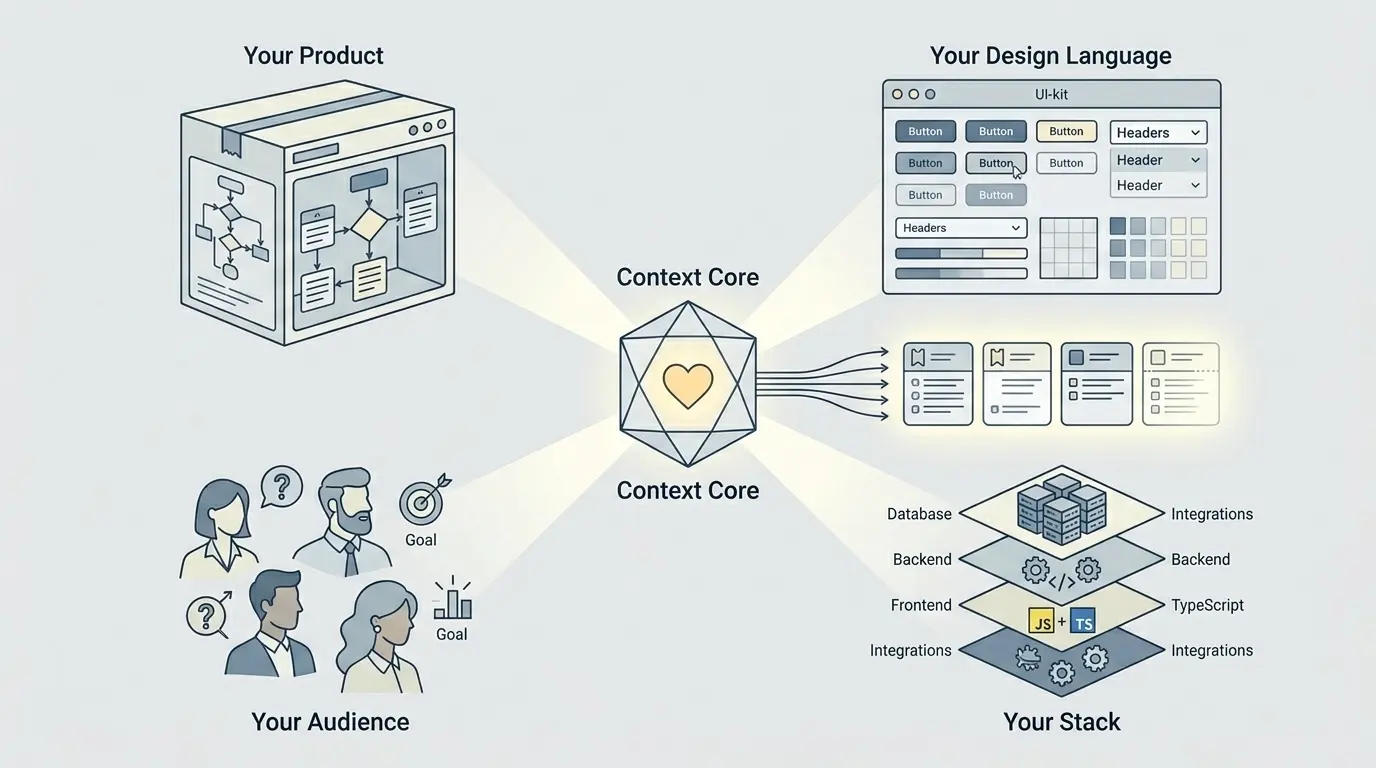
Прежде чем ИИ сможет выдать по-настоящему полезный результат для задачи в Jira, он должен понимать четыре вещи о мире, внутри которого работает:
- Сам продукт — что он делает, какие результаты важны и что именно функция должна улучшить для пользователей и бизнеса.
- Дизайн-язык — визуальные паттерны, библиотеку интерфейса и привычки взаимодействия, которые делают результат похожим на твой продукт, а не на абстрактное демо стартапа.
- Аудиторию — кто эти пользователи, что им нужно, чего они ожидают и чего не знают. Это влияет почти на всё: формулировки, поведение интерфейса и пограничные случаи.
- Стек — реальные фреймворки, границы среды выполнения, интеграции, ограничения по данным и технические рамки, которые должны определять, что вообще считается рабочим предложением.
Интересно то, что у большинства команд всё это уже есть. Оно существует в коде, документации, макетах и командной памяти. Просто этого нет в Jira в такой форме, которую ИИ способен увидеть. Поэтому инструменты, которые смотрят только на Jira, слепы к самому важному контексту проекта.
Если нужна практическая версия того, как такой слой контекста собрать и использовать, я отдельно разобрал это в статье Сначала задайте контекст продукта. Пожалуйста..
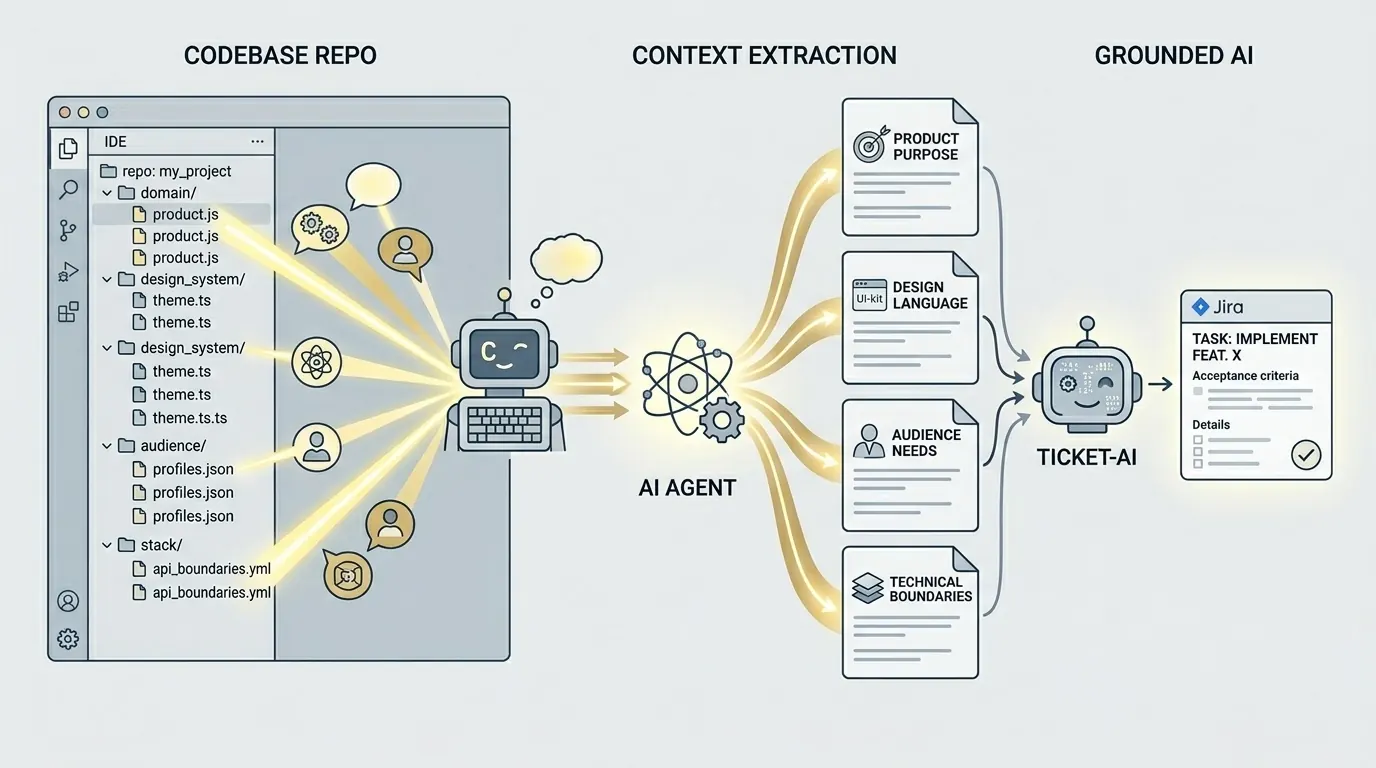
Твой код знает больше
Одна из действительно сильных сторон современных агентов для кода состоит в том, что они очень хорошо читают репозиторий и превращают его в понятный текстовый контекст. Можно направить Claude Code, Codex или другого сильного агента на репозиторий и попросить краткую сводку: для чего нужен продукт, какой у него стек, где границы реализации, какие есть известные пробелы и какие бизнес-сигналы уже видны. Это занимает минуты, а не неделю документации.
И это меняет уравнение. Вместо того чтобы просить ИИ генерировать что-то из двух предложений в тикете, ты даёшь ему опорную сводку о продукте, дизайн-системе, аудитории и стеке. В этот момент модель уже не импровизирует в темноте. Она рассуждает внутри мира, который действительно похож на твой проект.
Кодовая база всё это знание держала у себя с самого начала. Названия компонентов показывают дизайн-язык. Предметные модели раскрывают, как думает продукт. Интеграции и библиотеки объясняют технические границы. Контекст не нужно выдумывать с нуля. Его нужно достать в формат, который другой ИИ сможет использовать надёжно.
Скрытые решения
Даже с отличным контекстом проекта остаётся вторая проблема, которую ИИ не может решить угадыванием: решения, которые никто ещё не принял. Каждая задача в Jira несёт в себе скрытые допущения про права доступа, правила раскатки, пограничные случаи, обратную совместимость, детали поведения интерфейса и то, что вообще будет считаться успехом, когда функция встретится с реальными пользователями.
Эти решения никуда не исчезают, если их не принять заранее. Они просто всплывают посреди спринта — а это самое дорогое время, в которое можно заметить их отсутствие. Дизайнер спрашивает, какой экран считать точкой отсчёта. Инженеру нужно понять, есть ли уже API для этого сценария. Кто-то внезапно обнаруживает, что критерии приёмки предполагали авторизованных пользователей, хотя половина пути вообще анонимная. Всё это не неожиданности постфактум. Всё это было спрятано там с самого начала.
Именно поэтому одного контекста мало. Нужны ещё вопросы — конкретные, привязанные и к самому тикету, и к реальному контексту продукта одновременно. Это только для новых пользователей или и для существующих тоже? Что происходит, если браузер закрыли посередине сценария? Это функция только для админов? Это разовое действие или повторяющееся поведение? Короткая серия честных ответов создаёт больше согласованности, чем ещё один аккуратно оформленный документ.
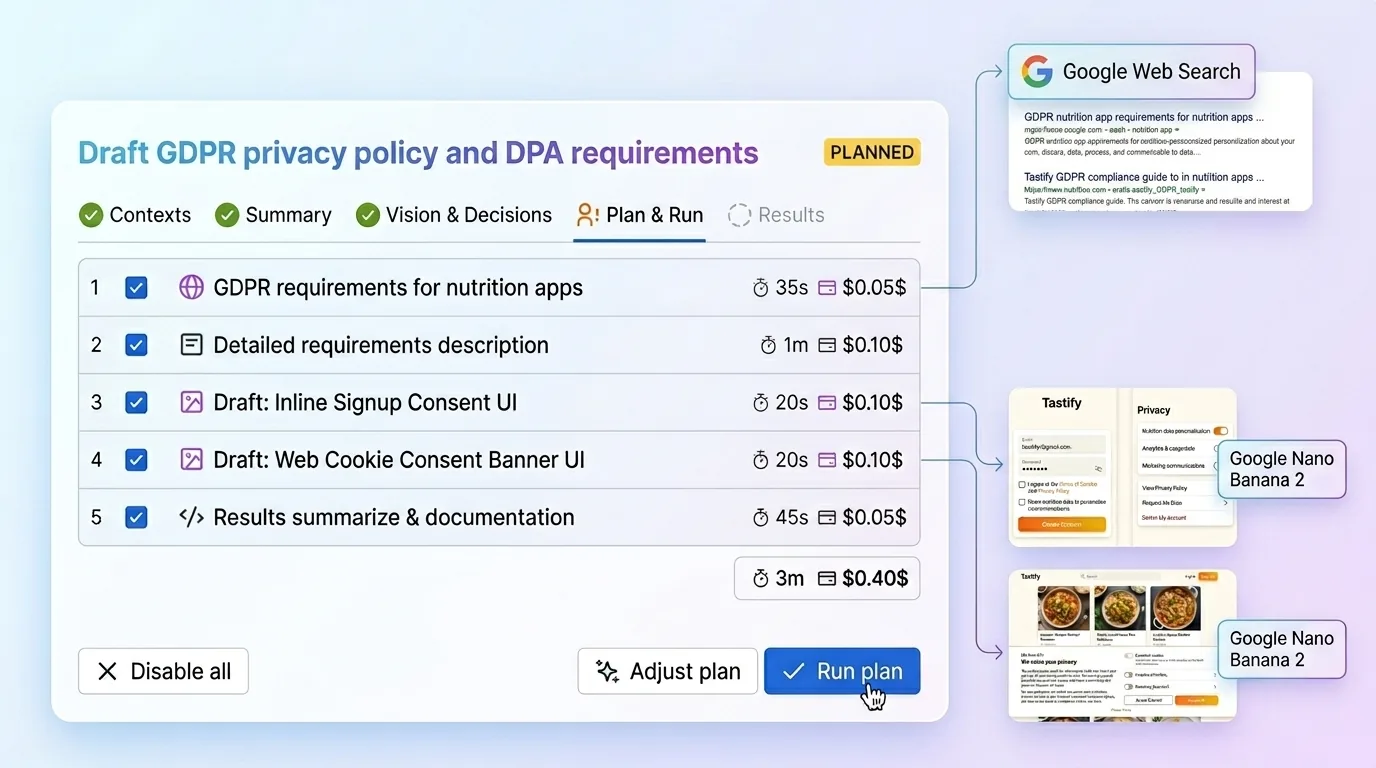
Как это работает в Just
Именно такую логику я и заложил в Just: ИИ-ассистент для Jira:
- Один раз задаёшь контекст проекта через четыре структурированных поля: краткое описание продукта, дизайн-систему, аудиторию и стек. Just даже даёт подсказки, которые можно прогнать через Claude Code или любого агента для кода, чтобы вытащить эти сводки прямо из репозитория. Ты вставляешь результат один раз, и этот контекст потом переиспользуется на будущих тикетах.
- Открываешь задачу в Jira. Без шаманства с промптами и без отдельной настройки под каждую задачу. Just читает её вместе с сохранённым контекстом и выдаёт инсайты, уже подогнанные под твой проект. Потом он задаёт уточняющие вопросы, которые уже не общие — они опираются на продукт, техническую реальность и дизайн-язык команды.
- Получаешь план. Just собирает требования, дизайн-направление, пограничные случаи, ожидаемые результаты и структурированный путь выполнения, по которому команда может реально работать. При необходимости он также подтягивает свежий веб-контекст, а работать может со всеми пятью крупными ИИ-провайдерами, чтобы на каждом шаге использовать лучшую модель под конкретную задачу. Смысл здесь не в магии. Смысл в том, чтобы помочь команде генерировать правильный результат, а не просто быстрый. Полный сценарий можно посмотреть на aiapps.me.
Что это меняет
Так почему большинство ИИ-инструментов для Jira усиливают проблему рассинхрона, а не уменьшают её? Потому что обычно они подключаются уже после того, как неоднозначность попала внутрь тикета, а потом просто делают её аккуратной и внешне законченной.
Настоящая точка усиления находится раньше. Нужно сначала чётко понять, чего команда хочет, вытащить скрытые решения до старта реализации и дать ИИ достаточно контекста, чтобы он работал внутри реальной формы продукта, а не гадал по бедному описанию.
Вот и вся суть. Если команда понимает, чего хочет, ещё до старта работы, ИИ становится полезным. Если нет — результат всё равно может выглядеть впечатляюще, но за путаницу почти наверняка придётся расплачиваться позже переделками.