L’IA non risolve il disallineamento del team. Lo nasconde.
Questi strumenti sembrano risolvere un problema classico di Jira: trasformare ticket vaghi in qualcosa di operativo. Il punto è che un risultato ben rifinito può far sembrare il team allineato quando in realtà non lo è ancora.

Il problema del genio
C’è un’immagine mentale a cui torno spesso quando penso all’IA. L’IA è un genio. Fa esattamente quello che le dici, non quello che intendevi dire. Ed è proprio in quella distanza che una parte sorprendente del lavoro di prodotto comincia a rompersi.
La scena la conosci. Una persona di prodotto sta tenendo insieme quattro cose nello stesso momento e scrive un ticket Jira in due minuti. Il ticket non è brutto per cattiva volontà. È semplicemente vago, frettoloso, incompleto e pieno di supposizioni che nessuno ha mai reso esplicite.
Il team di sviluppo lo prende in carico, costruisce qualcosa di sensato a partire dalle parole disponibili e, due settimane dopo, tutti si ritrovano in review a dire una qualche versione di: non era questo che intendevo.
Nessuno ha mentito. Nessuno è stato pigro. È solo che l’idea non è mai diventata abbastanza esplicita prima dell’inizio del lavoro. Con l’IA questa stessa dinamica è ancora più dura, perché al modello manca quel contesto di squadra che spesso colma i vuoti. Se il ticket porta pochissimo contesto, il genio lavora quasi al buio.
L’artefatto più debole
Pensa a dove vive davvero la conoscenza di un prodotto. Il codice conosce l’architettura, i nomi, le dipendenze e i confini dell’implementazione. I file di design conoscono il linguaggio visivo, i modelli d’interazione e le decisioni ripetute abbastanza a lungo da diventare sistema. I ticket precedenti e la documentazione conoscono il vocabolario del team e il modo in cui di solito affrontate i compromessi.
Un ticket Jira non sa quasi nulla di tutto questo. Spesso è l’artefatto meno ricco di contesto di tutto lo stack. Quindi quando un team incolla un ticket dentro uno strumento di IA e si aspetta un risultato di qualità, in pratica sta chiedendo un’ottima risposta partendo dall’input meno informativo che ha a disposizione.
Ecco perché il risultato suona spesso plausibile ma si adatta male alla realtà. I criteri di accettazione danno per scontato l’utente sbagliato. Le idee di design scivolano verso uno stile visivo che non pubblicheresti mai. I consigli tecnici ignorano il tuo stack, il tuo modello di rilascio o le scorciatoie che il team sceglie volutamente di non prendere. L’IA non sta “sbagliando”. Sta facendo il meglio possibile con una richiesta impostata male.
Sicurezza di sé senza sostanza
La maggior parte degli strumenti di IA per Jira segue più o meno lo stesso copione. Apri l’issue. Premi un pulsante. Ottieni una descrizione, criteri di accettazione e magari una scomposizione in sottoattività. L’esperienza sembra produttiva perché il risultato è rapido, ordinato e ben impaginato.
Di solito funziona così:
- apri l’issue;
- premi il pulsante;
- ricevi un testo pulito, i criteri e magari delle sottoattività.
Ma avere struttura non significa avere allineamento. Se l’input era vago e privo di contesto, l’output è solo una versione più sicura di quella stessa ambiguità. In pratica lo strumento può persino peggiorare il problema, perché una forma ben rifinita scoraggia le persone dal rimettere in discussione le ipotesi prima di partire con l’implementazione.
Qui sta il pericolo silenzioso: spazzatura in ingresso, spazzatura in uscita, solo che adesso la spazzatura ha titoli, elenchi e tono da certezza. Un team può entrare in sviluppo con più fiducia e meno chiarezza nello stesso momento.

Cosa serve davvero all’IA
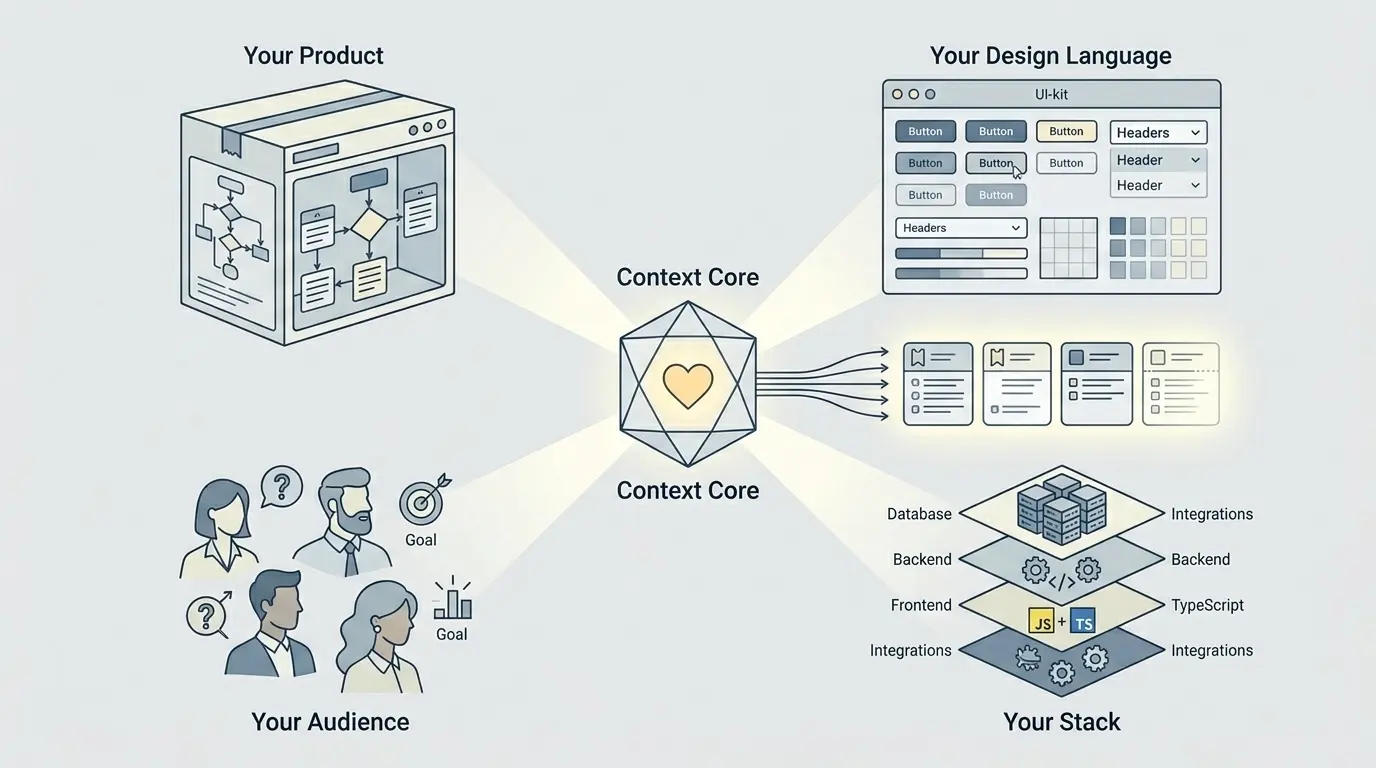
Prima che l’IA possa produrre qualcosa di realmente utile per un’issue di Jira, deve capire quattro cose del mondo in cui sta lavorando:
- Il tuo prodotto: cosa fa, quali risultati contano e che cosa la funzionalità dovrebbe migliorare per utenti e business.
- Il tuo linguaggio di design: schemi visivi, libreria di interfaccia e abitudini d’interazione che fanno sembrare l’output parte del tuo prodotto e non di una demo qualsiasi.
- Il tuo pubblico: chi sono gli utenti, di cosa hanno bisogno, che cosa si aspettano e che cosa non sanno. Questo cambia quasi sempre il linguaggio, le interazioni e i casi limite.
- Il tuo stack: framework reali, confini di esecuzione, integrazioni, vincoli sui dati e limiti tecnici che dovrebbero determinare quali suggerimenti sono davvero validi.
La parte interessante è che la maggior parte dei team ha già tutto questo. Esiste nel codice, nei documenti, nei mockup e nella memoria del gruppo. Semplicemente non esiste dentro Jira in una forma che l’IA riesca a vedere. Per questo gli strumenti che guardano solo Jira sono ciechi proprio rispetto al contesto più importante del progetto.
Se vuoi una versione pratica di questo livello di contesto, la tua IA sta tirando a indovinare sul tuo prodotto spiega cosa conviene salvare e come riusarlo.
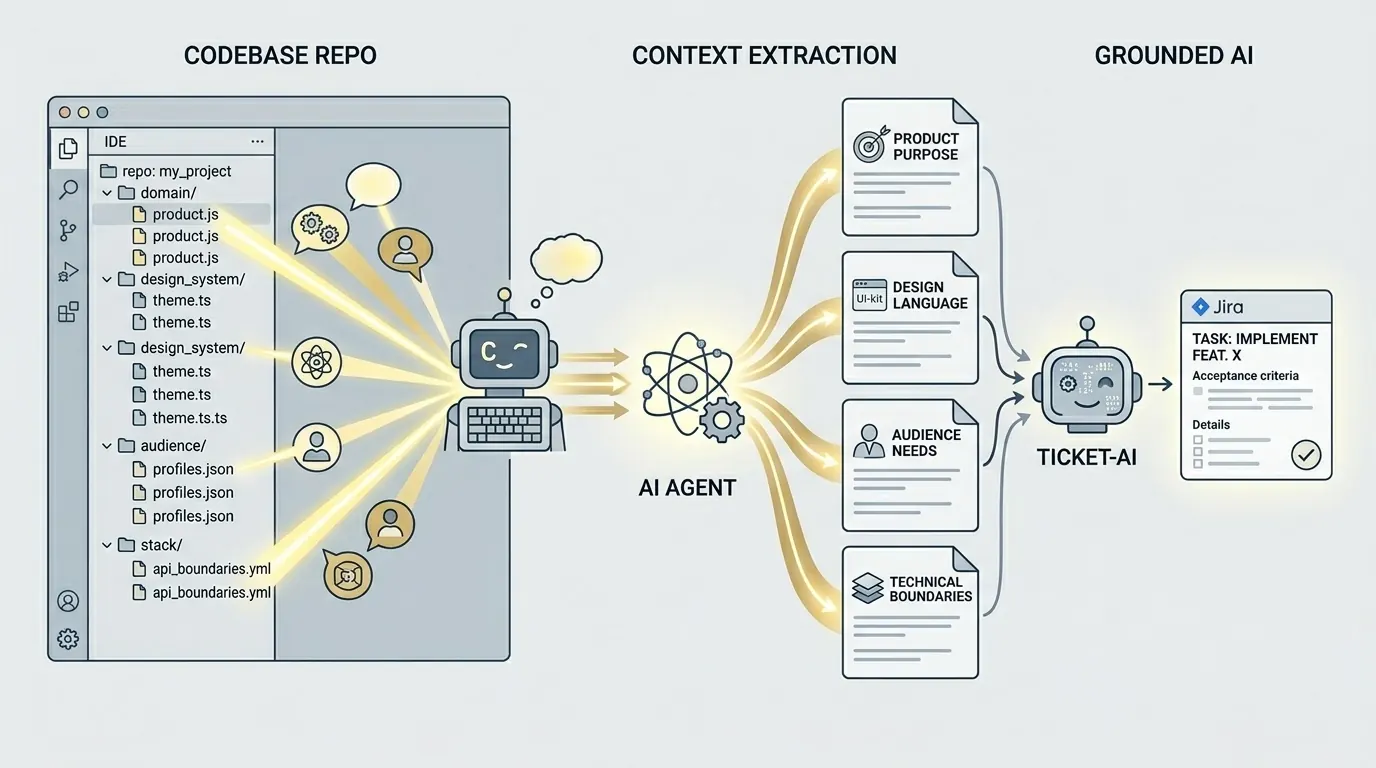
Il tuo codice ne sa di più
Una delle cose davvero forti degli attuali agenti di programmazione è che sanno leggere un repository molto bene e trasformarlo in contesto leggibile. Puoi puntare Claude Code, Codex o un altro agente solido sul tuo repository e chiedergli un riepilogo in markdown su scopo del prodotto, stack, confini di implementazione, lacune note e segnali di business. Ci vogliono minuti, non una settimana di documentazione.
E questo cambia l’equazione. Invece di chiedere all’IA di generare qualcosa da un ticket di due frasi nel vuoto, le dai un riepilogo concreto di prodotto, sistema di design, pubblico e stack. A quel punto il modello non improvvisa più nel buio. Ragiona dentro un mondo che somiglia davvero al tuo progetto.
Il codice custodiva già tutte queste risposte. I nomi dei componenti mostrano il linguaggio di design. I modelli di dominio rivelano come ragiona il prodotto. Integrazioni e librerie spiegano i confini tecnici. Non serve inventare contesto da zero. Serve estrarlo in un formato che un’altra IA possa usare in modo affidabile.
Decisioni nascoste
Anche con un ottimo contesto di progetto, resta un secondo problema che l’IA non può risolvere tirando a indovinare: le decisioni che nessuno ha ancora preso. Ogni issue di Jira si porta dietro assunzioni nascoste su permessi, regole di rilascio, casi limite, retrocompatibilità, dettagli di interazione e perfino su che cosa significhi davvero “successo” quando la funzionalità incontra utenti reali.
Queste decisioni non spariscono quando il lavoro parte. Semplicemente riemergono a metà sprint, che è il momento più costoso possibile per accorgersene. Una designer chiede quale schermata esistente vada presa come riferimento. Uno sviluppatore ha bisogno di sapere se esiste già un’API per quel flusso. Qualcuno si accorge che i criteri di accettazione davano per scontati utenti autenticati, mentre metà dell’esperienza è anonima. Nulla di tutto questo sorprende col senno di poi. Era lì fin dall’inizio.
Per questo il contesto da solo non basta. Servono anche domande: domande precise, fondate insieme sul ticket e sul contesto reale del prodotto. Vale per gli utenti esistenti o solo per quelli nuovi? Che cosa succede se il browser si chiude a metà del flusso? È una funzione riservata agli amministratori? È un’azione una tantum o un comportamento ricorrente? Una breve raffica di risposte sincere crea più allineamento di un’altra specifica impeccabile.
Come funziona in Just
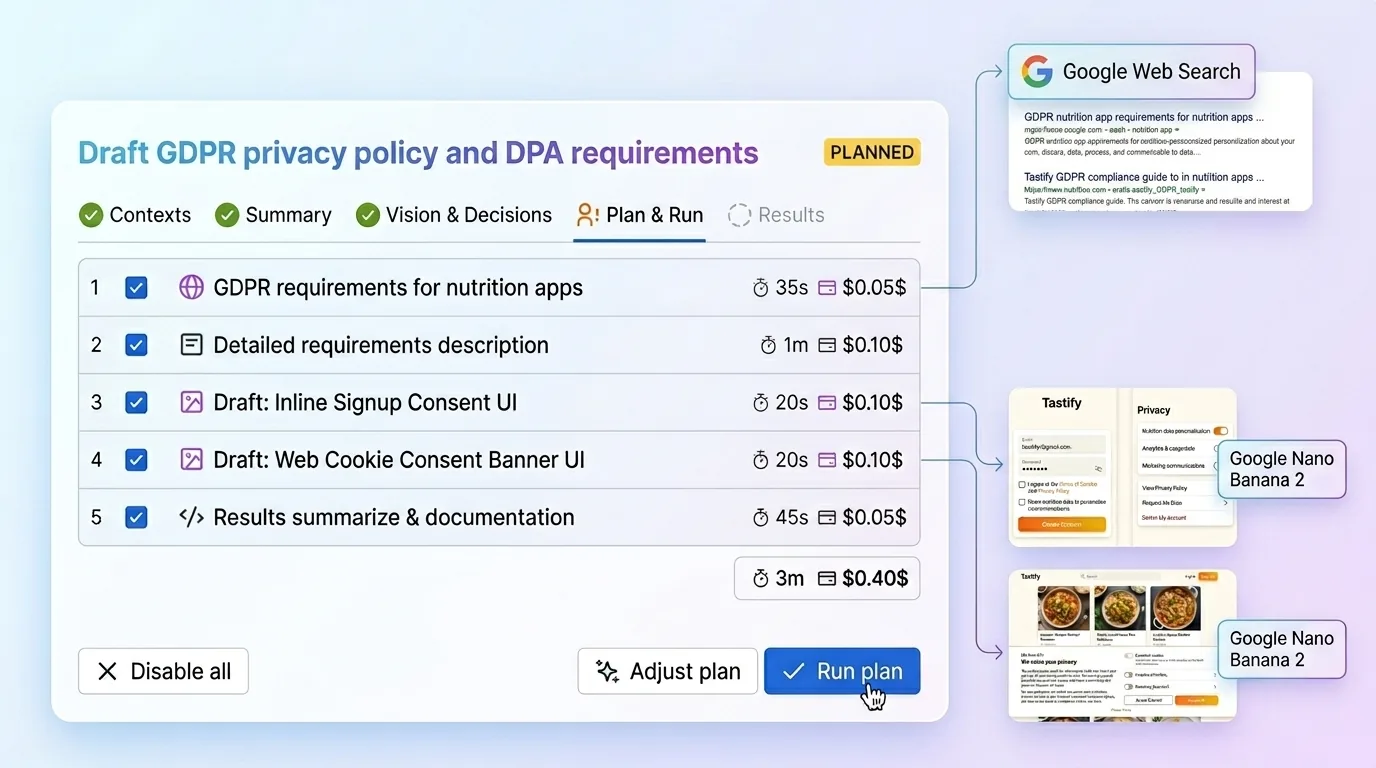
È esattamente questo il flusso che ho costruito in Just: AI Assistant for Jira:
- Imposti una sola volta il contesto di progetto attraverso quattro campi strutturati: sintesi del prodotto, sistema di design, pubblico e stack. Just fornisce anche indicazioni che puoi passare a Claude Code o a qualunque agente di programmazione per generare questi riepiloghi dal repository. Incolli il risultato una volta e quel contesto viene riutilizzato nei ticket successivi.
- Apri un’issue di Jira. Niente acrobazie con i prompt e nessuna configurazione aggiuntiva per ogni task. Just legge l’issue insieme al contesto salvato e fa emergere spunti davvero plasmati sul tuo progetto. Poi pone domande di chiarimento che non sono generiche: si basano sul prodotto, sulla realtà tecnica e sul linguaggio di design con cui il team lavora già.
- Costruisci il piano. Just trasforma quelle risposte in requisiti, direzione di design, casi limite, risultati attesi e un percorso di esecuzione strutturato su cui il team può lavorare davvero. Può anche integrare contesto fresco dal web quando serve, e funziona con tutti e cinque i principali fornitori di IA così da usare il modello migliore in ogni passaggio. Il punto non è sembrare magico. Il punto è aiutare il team a generare la cosa giusta, non semplicemente qualcosa in fretta. Puoi vedere l’intero flusso su aiapps.me.
Cosa cambia
Quindi perché la maggior parte degli strumenti di IA per Jira peggiora il problema dell’allineamento invece di ridurlo? Perché di solito entra in gioco quando l’ambiguità è già finita dentro al ticket e poi si limita a darle una forma ordinata e apparentemente completa.
La vera leva è prima. Bisogna chiarire che cosa il team vuole davvero, portare allo scoperto le decisioni nascoste prima dell’implementazione e dare all’IA abbastanza contesto da farla lavorare dentro la forma reale del prodotto, invece di costringerla a indovinare partendo da un brief povero.
Questo è il punto centrale. Se il team capisce bene che cosa vuole prima di iniziare, l’IA diventa utile. Se non lo capisce, l’output può comunque sembrare impressionante, ma quella confusione quasi certamente si pagherà più tardi in rilavorazione.