L’IA ne répare pas le manque d’alignement. Elle le maquille.
Ces outils semblent résoudre un problème classique dans Jira : transformer des tickets flous en quelque chose d’exploitable. Mais un résultat bien présenté peut donner à l’équipe l’impression d’être alignée alors que ce n’est pas encore le cas.

Le problème du génie
Il y a une image qui me revient sans cesse quand je pense à l’IA. L’IA, c’est un génie. Elle fait exactement ce qu’on lui dit, pas ce qu’on voulait dire. Et c’est dans cet écart que beaucoup de livraisons produit commencent à dérailler.
Tu connais la scène. Une personne côté produit jongle avec quatre sujets à la fois et rédige un ticket Jira en deux minutes. Le ticket n’est pas mauvais par négligence. Il est juste flou, pressé, incomplet et rempli de présupposés que personne n’a pris le temps d’énoncer clairement.
L’ingénierie s’en empare, construit quelque chose de raisonnable à partir des mots disponibles et, deux semaines plus tard, tout le monde se retrouve en revue à dire une variante de la même phrase : ce n’est pas ça que je voulais dire.
Personne n’a menti. Personne n’a bâclé le travail. L’intention n’a simplement jamais été rendue assez explicite avant le départ. Avec l’IA, le problème devient encore plus rude, parce que le modèle n’a aucun contexte implicite d’équipe pour combler les blancs. Si le ticket apporte presque zéro contexte, le génie travaille presque à vide.
L’artefact le plus faible
Réfléchis à l’endroit où vit réellement la connaissance du produit. Ton dépôt connaît l’architecture, les conventions de nommage, les dépendances et les frontières de mise en œuvre. Les fichiers de design connaissent le langage visuel, les habitudes d’interaction et les décisions répétées assez souvent pour devenir un système. Les anciens tickets et la documentation connaissent le vocabulaire de l’équipe et la manière dont vous formulez d’ordinaire les compromis.
Un ticket Jira ne sait presque rien de tout cela. C’est souvent l’artefact le plus pauvre en contexte de toute la pile. Donc, quand une équipe colle un ticket dans un outil d’IA en attendant une sortie de qualité, elle demande en réalité une excellente réponse à partir de l’entrée la moins informative dont elle dispose.
Voilà pourquoi la sortie paraît si souvent plausible tout en tombant à côté. Les critères d’acceptation partent du mauvais utilisateur. Les idées de design dérivent vers un style visuel que vous ne mettriez jamais en production. Les recommandations techniques ignorent votre stack, votre mode de déploiement ou les raccourcis que l’équipe refuse volontairement de prendre. L’IA n’est pas en train de “rater”. Elle fait simplement de son mieux avec un brief indigent.
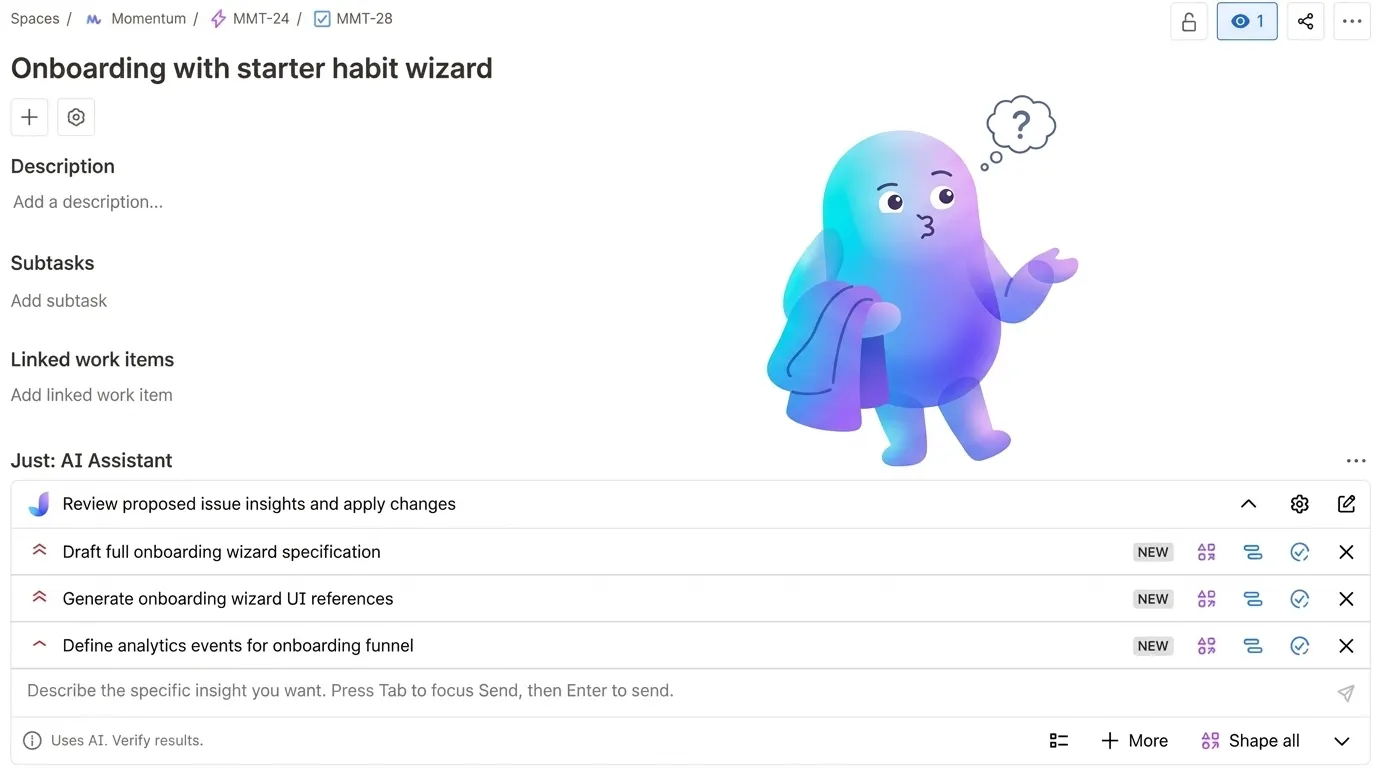
Une absurdité bien assurée
La plupart des outils d’IA pour Jira fonctionnent à peu près de la même manière. On ouvre l’issue. On clique sur un bouton. On reçoit une description, des critères d’acceptation, parfois une découpe en sous-tâches. L’expérience donne une impression d’efficacité parce que le résultat arrive vite, bien structuré et propre.
En général, cela ressemble à ceci :
- on ouvre l’issue ;
- on clique sur le bouton ;
- on récupère un texte net, des critères et parfois des sous-tâches.
Mais la structure n’est pas l’alignement. Si l’entrée était floue et sans contexte, la sortie n’est qu’une version plus assurée de cette même ambiguïté. En pratique, l’outil peut même aggraver le problème, parce qu’une présentation soignée décourage ensuite l’équipe de remettre les hypothèses en question avant de se lancer.
Le danger silencieux est là : des déchets à l’entrée, des déchets à la sortie, sauf que cette fois les déchets ont des titres, des puces et le ton de la certitude. Une équipe peut partir en mise en œuvre avec davantage de confiance et moins de clarté au même moment.

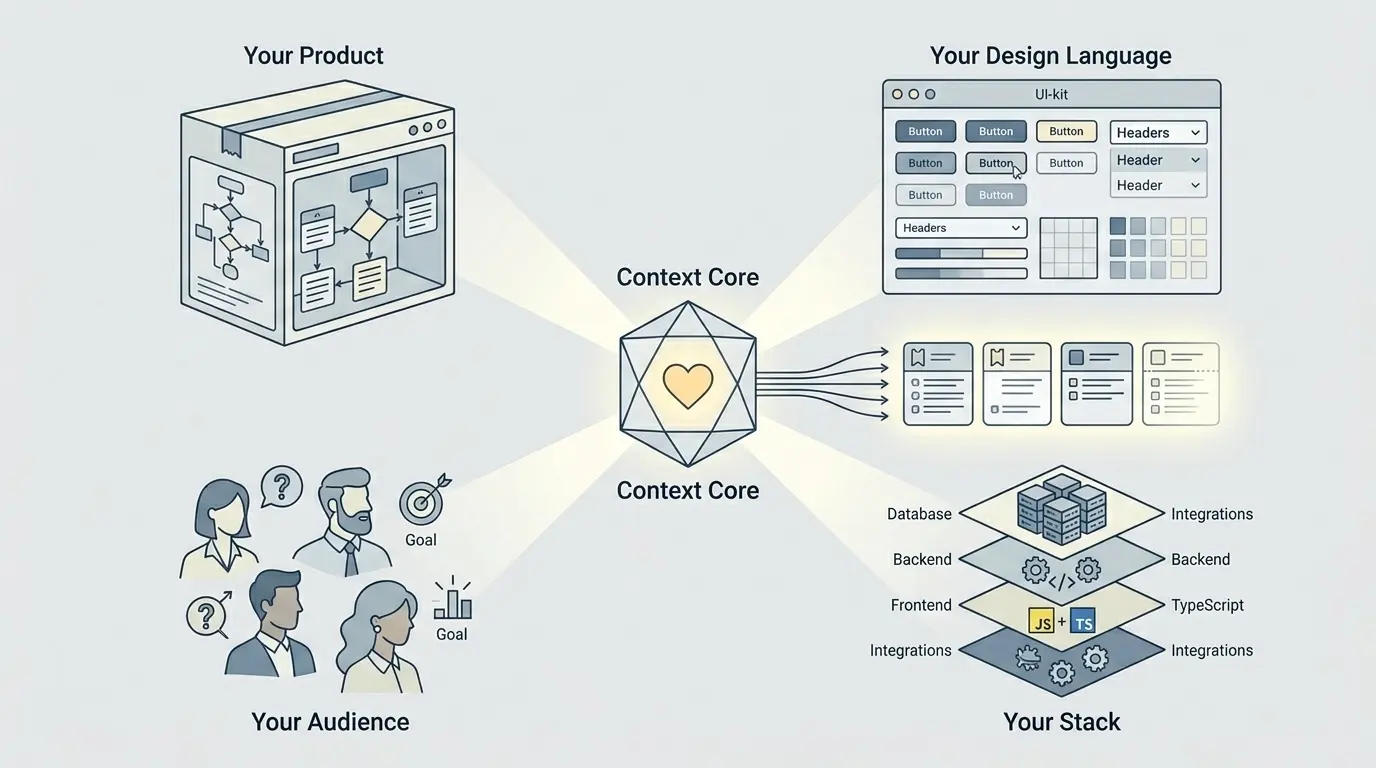
Ce qu’il faut vraiment à l’IA
Avant que l’IA puisse produire quelque chose d’utilisable pour une issue Jira, elle doit comprendre quatre choses sur le monde dans lequel elle travaille :
- Votre produit : ce qu’il fait, quels résultats comptent et ce que la fonctionnalité doit améliorer pour les utilisateurs comme pour l’entreprise.
- Votre langage de design : les schémas visuels, la bibliothèque d’interface et les habitudes d’interaction qui font qu’une sortie ressemble à votre produit plutôt qu’à une démonstration générique.
- Votre audience : qui sont les utilisateurs, ce dont ils ont besoin, ce qu’ils attendent et ce qu’ils ignorent. Cela change presque toujours la formulation, l’interaction et les cas limites.
- Votre stack : les vrais cadres techniques, les frontières d’exécution, les intégrations, les contraintes de données et les limites techniques qui doivent définir ce qui constitue une suggestion valable.
Le point intéressant, c’est que la plupart des équipes possèdent déjà tout cela. C’est présent dans le code, la documentation, les maquettes et la mémoire collective. Ce qui manque, c’est une forme visible par l’IA à l’intérieur de Jira. Voilà pourquoi les outils qui ne regardent que Jira passent à côté du contexte le plus important du projet.
Si tu veux une version plus concrète de cette couche de contexte, votre IA est en train d’inventer votre produit explique quoi stocker et comment le réutiliser.
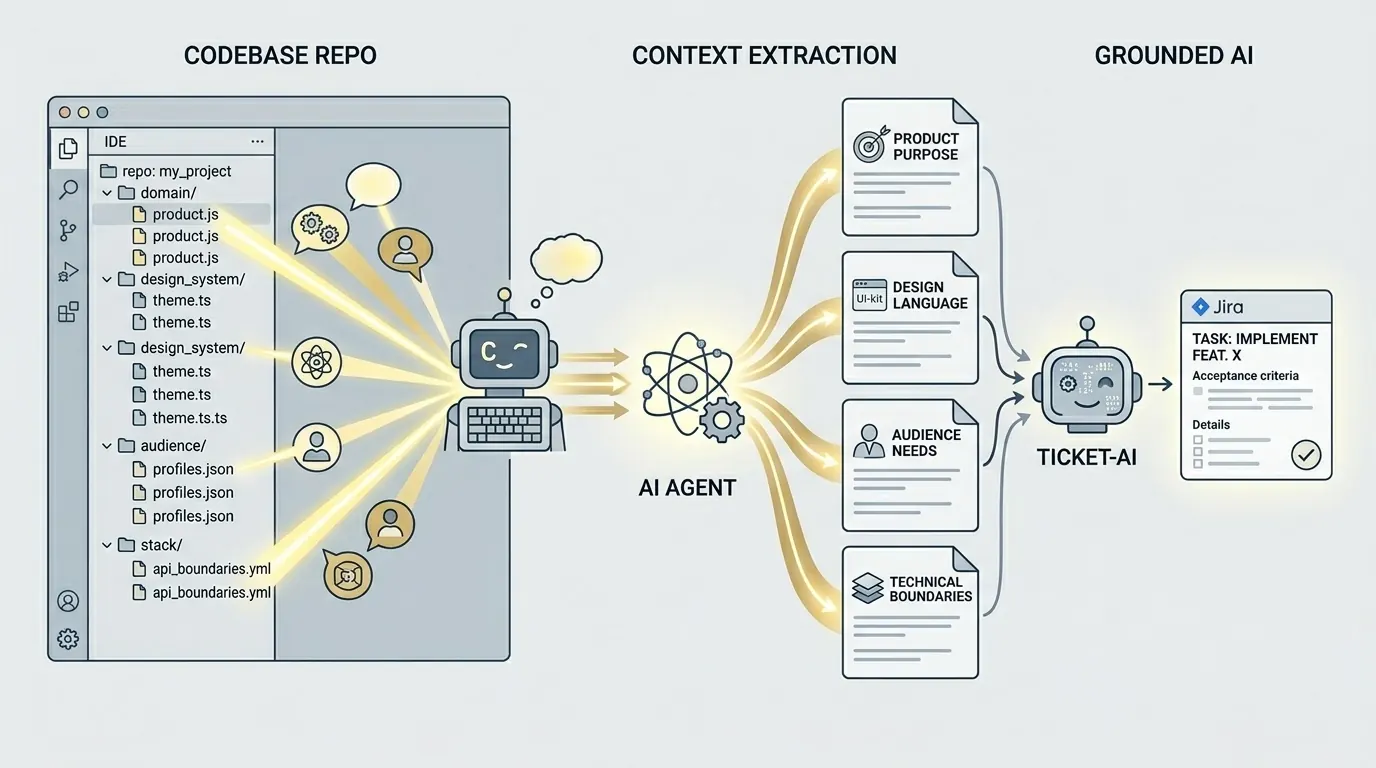
Votre code en sait plus
L’une des choses réellement enthousiasmantes avec les agents de code actuels, c’est leur capacité à lire un dépôt et à en tirer un contexte clair en langage courant. On peut orienter Claude Code, Codex ou un autre agent solide vers le dépôt et lui demander un résumé markdown sur la finalité du produit, le stack, les limites de mise en œuvre, les manques connus et les signaux métier. Cela prend quelques minutes, pas une semaine de documentation.
Et là, l’équation change. Au lieu de demander à l’IA de générer à partir d’un ticket de deux phrases dans le vide, on lui donne un résumé solide du produit, du système de design, de l’audience et du stack. D’un coup, le modèle n’improvise plus dans le noir. Il raisonne dans un monde qui ressemble vraiment au projet.
Le dépôt contenait déjà les réponses. Les noms de composants révèlent le langage de design. Les modèles métier montrent comment le produit pense. Les intégrations et les bibliothèques dessinent les frontières techniques. Il ne faut pas inventer ce contexte depuis zéro. Il faut l’extraire dans un format qu’une autre IA pourra exploiter de manière fiable.
Les décisions cachées
Même avec un excellent contexte projet, il reste un second problème que l’IA ne peut pas résoudre par simple supposition : les décisions que personne n’a encore prises. Chaque issue Jira transporte des hypothèses cachées sur les permissions, les règles de déploiement, les cas limites, la compatibilité ascendante, les détails d’interaction et même la manière de juger qu’une fonctionnalité est réussie une fois confrontée à de vrais utilisateurs.
Ces décisions ne disparaissent pas lorsqu’on commence à travailler. Elles ressurgissent simplement en plein sprint, c’est-à-dire au moment le plus coûteux pour les découvrir. Une designer demande quel écran sert de référence. Un ingénieur doit savoir s’il existe déjà une API pour ce flux. Quelqu’un réalise soudain que les critères d’acceptation supposaient des utilisateurs connectés alors qu’une bonne partie du parcours est anonyme. Rien de tout cela n’est surprenant après coup. Tout cela était déjà là.
Voilà pourquoi le contexte seul ne suffit pas. Il faut aussi des questions : des questions précises, appuyées à la fois sur le ticket et sur le contexte réel du produit. Est-ce que cela s’applique aux utilisateurs existants ou seulement aux nouveaux ? Que se passe-t-il si le navigateur se ferme au milieu du parcours ? La fonctionnalité est-elle réservée aux administrateurs ? Est-ce une action ponctuelle ou un comportement récurrent ? Une courte série de réponses franches crée plus d’alignement qu’une nouvelle spécification impeccable.
Comment cela fonctionne dans Just
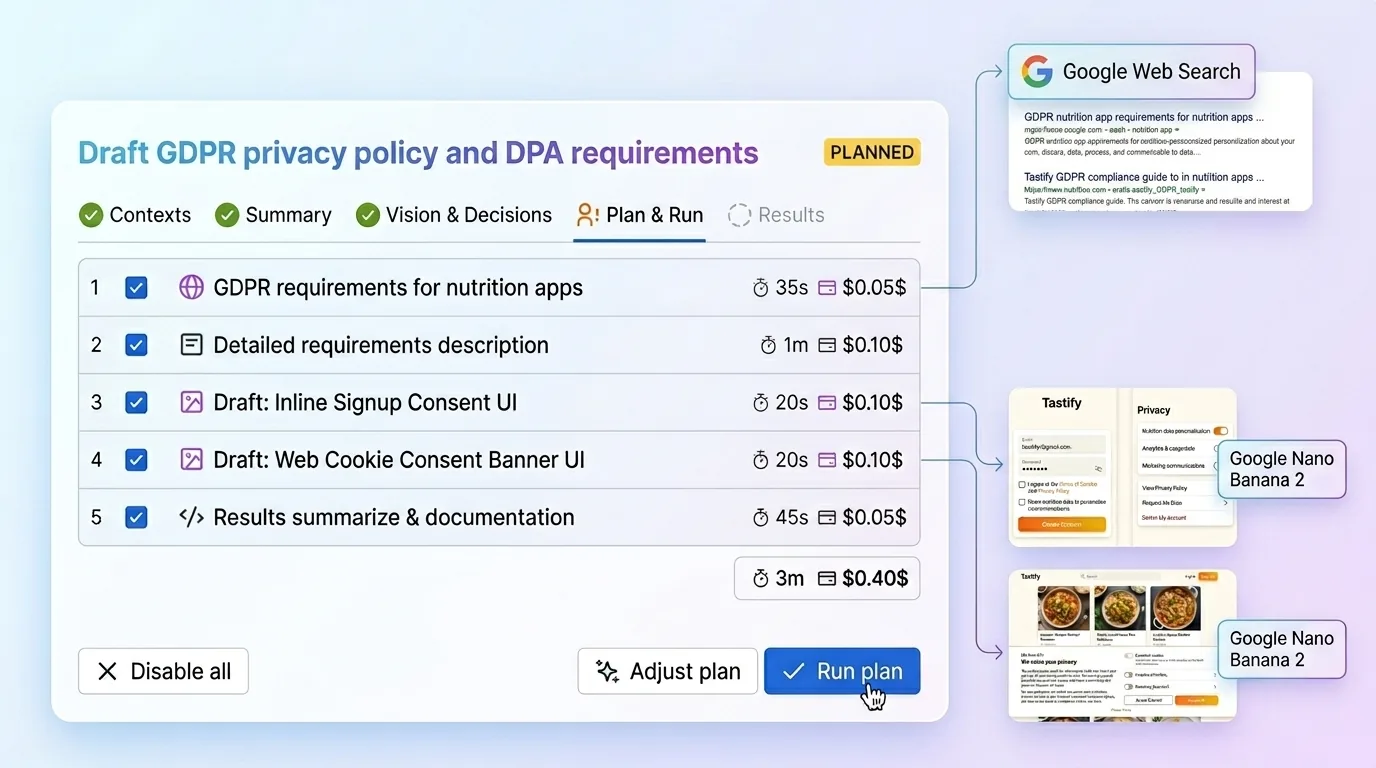
C’est précisément le flux que j’ai construit dans Just: AI Assistant for Jira :
- On définit une seule fois le contexte projet à l’aide de quatre champs structurés : résumé du produit, système de design, audience et stack. Just fournit même des consignes que l’on peut faire passer dans Claude Code ou n’importe quel agent de code afin de générer ces résumés directement depuis le dépôt. On colle le résultat une fois, puis ce contexte est réutilisé sur les tickets suivants.
- On ouvre une issue Jira. Pas de bricolage de prompts, pas de réglage supplémentaire pour chaque tâche. Just lit l’issue avec le contexte enregistré et fait remonter des observations réellement façonnées par le projet. Ensuite, il pose des questions de clarification qui ne sont pas génériques : elles tiennent compte du produit, de la réalité technique et du langage de design de l’équipe.
- On construit le plan. Just transforme ces réponses en exigences, direction de design, cas limites, résultats attendus et chemin d’exécution structuré sur lequel l’équipe peut vraiment avancer. Il peut aussi aller chercher du contexte web frais quand c’est utile, et il fonctionne avec les cinq grands fournisseurs d’IA pour utiliser le meilleur modèle selon l’étape. L’objectif n’est pas de faire “magique”. L’objectif est d’aider l’équipe à produire la bonne chose, pas simplement quelque chose de rapide. Le flux complet est visible sur aiapps.me.
Ce que cela change
Alors pourquoi la plupart des outils d’IA pour Jira aggravent-ils le problème d’alignement au lieu de l’améliorer ? Parce qu’ils interviennent généralement une fois que l’ambiguïté est déjà dans le ticket, puis lui donnent simplement une apparence propre et complète.
Le vrai levier se situe plus tôt. Il faut d’abord rendre clair ce que l’équipe veut vraiment, faire remonter les décisions cachées avant le début de la mise en œuvre et donner à l’IA assez de contexte pour travailler dans la forme réelle du produit plutôt que de deviner à partir d’un brief trop pauvre.
C’est tout le sujet. Si l’équipe comprend ce qu’elle veut avant de se lancer, l’IA devient utile. Sinon, la sortie peut rester impressionnante en apparence, mais cette confusion se paiera très probablement plus tard en retours arrière.