你的AI六个月前就停止学习了
工单上个月写好了,功能下个月上线。在这之间,竞争对手发布了类似产品,API改变了,一条合规要求悄然生效。

写完和上线之间的落差
工单上个月写好了。功能下个月上线。就在这段时间里,竞争对手发布了类似的东西,API发生了变化,一项新的强制要求悄然生效。这些都没有反映回工单中。
这不是假设情境。这就是每周二站会上发生的事,sprint进行到一半的时候。团队里有人提到一个API的行为已经和工单描述的不一样了。另一个人打开竞争对手的更新日志,发现他们三周前发布了几乎一模一样的功能。工单在写的时候没有问题——是世界在sprint开始之前先动了。
代价不只是返工。是信任的流失。是sprint目标悄悄变成空话。是PM向干系人解释,为什么团队交付的东西在上线第一天就已经过时。
每个团队都有自己版本的这个故事。大多数都要讲不止一次,才会真正改变什么。
AI的知识有截止日期
现在大多数团队已经在用AI帮助撰写、规划和细化Jira工单。这个部分是有效的。AI模型确实擅长结构化需求、生成验收标准、建议实现方案。如果你想了解更宏观的背景——为什么把模糊的工单直接交给AI会特别危险,这篇文章有详细说明:为什么大多数AI工具让Jira的对齐问题更严重而非更好。
大多数团队没有考虑到的是:每个AI模型的训练数据都有截止日期——通常比当前日期早六到十二个月。模型不知道训练结束后发生了什么。它不是在猜测,也不是在刻意回避——它就是看不到。
这意味着模型不知道Next.js 16.1在2025年12月取消了对Node 18的支持,导致那些假设兼容性的团队构建失败。它不知道OpenAI在2026年2月永久删除了chatgpt-4o-latest模型端点,所有仍在引用该字符串的集成因此断掉。它不知道美国三个州在2026年1月1日通过了全面的隐私法,一夜之间扩大了数据退出要求。
你的AI助手的知识在大约六个月前就停了。法规可不等人。
这不是模型质量的问题——这是结构性问题。模型在其训练数据的范围内完成自己的工作。而在那条边界和今天之间,破坏性变更不断积累,竞争对手持续发布新功能,合规要求也在移动。如果规划流程不考虑这个落差,每一张AI辅助生成的工单都带着一个隐藏的有效期。

三个真实踩坑的场景
这些不是抽象风险。这正是那种在sprint回顾中出现、被打上"无法预测"标签的事情——而实际上,花五分钟调研就完全可以预测到。
- 依赖库的破坏性变更。 工单假设某个库或API的行为和上次集成时一样。团队写好实现计划,拿起工单开始干。sprint进行到一半,构建开始失败,或者API调用返回没人预期的错误。这正是OpenAI在2026年2月17日删除
chatgpt-4o-latest快照时发生的事。任何在2025年底估算工单并引用了该模型字符串的团队都撞上了一堵墙——那个端点直接停止了响应。 - 竞争对手已经发布了这个功能。 这不一定是取消工单的理由,但始终是"先看看再动手"的理由。当竞争对手已经发布了同样的功能,他们已经记录了边界案例,收集了用户反馈,有时还踩过了你不必再踩的坑。五分钟的竞品调研,可以省掉两周的探索,也可以避免交付一个市场已经走过了的东西带来的挫败感。
- 监管和合规要求的变化。 这是风险最高的情况,因为后果不只是浪费的sprint——还有法律风险。一张2025年11月为美国用户写的工单,不会考虑2026年1月1日的隐私法变化,除非有人在sprint前专门去查了。监管机构不会在Jira里开工单。他们不会等你的sprint周期。
什么时候做这个检查
时机比检查本身更重要。
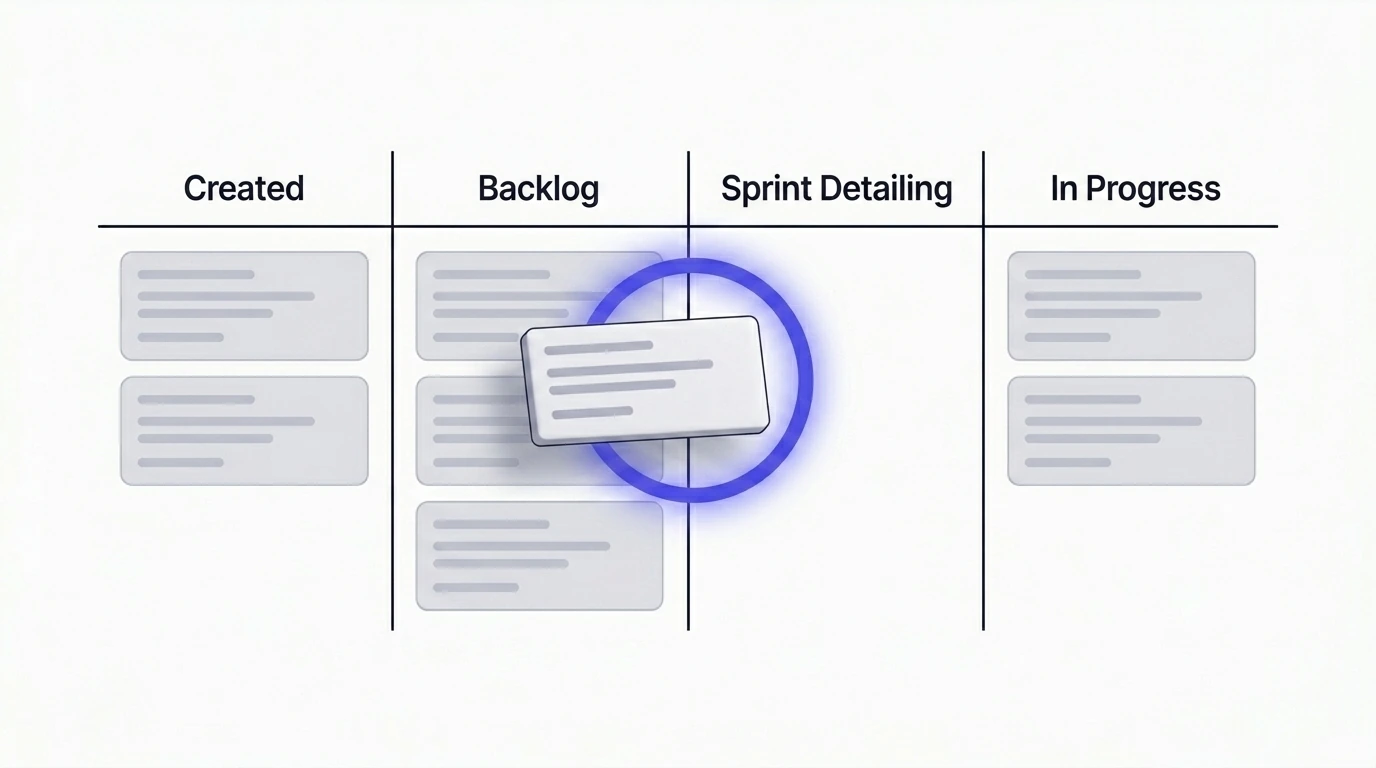
- 不是工单创建时。 太早了。工单可能在backlog里躺几周甚至几个月。你现在查的东西,等到有人真正拿起它时早就过时了。
- 不是sprint中途。 太晚了。团队已经投入了容量。这时候发现破坏性变更或合规变化,意味着返工、阻塞的故事,和已经无法完成的sprint目标。
- 工单被细化并排入下一个sprint的时候。 正是这个节点,团队已经在为它投入真正的时间——细化范围、拆分子任务、确认方案。在这个时候加一次五到十分钟的市场检查,成本低、回报高。如果想了解这次检查之后一张"可开发"的工单应该是什么结构,这篇文章是自然的延续:把模糊的Jira工单变成清晰的实现计划。
在把工单提交进sprint前要确认的几点:
- 自工单撰写以来,相关依赖或平台有没有发生变化?
- 竞争对手有没有已经发布过类似的东西,他们从中学到了什么?
- 这个功能领域是否出现了新的监管或合规信号?
- 工单估算时不存在的新工具、模式或方法,现在有了吗?
这四个问题花不了几分钟。跳过它们,代价是整个sprint。
Just如何把这一步自动化
难的不是知道"应该去查"。难的是让这个检查成为流程的一部分,而不是靠某个人记得去做。
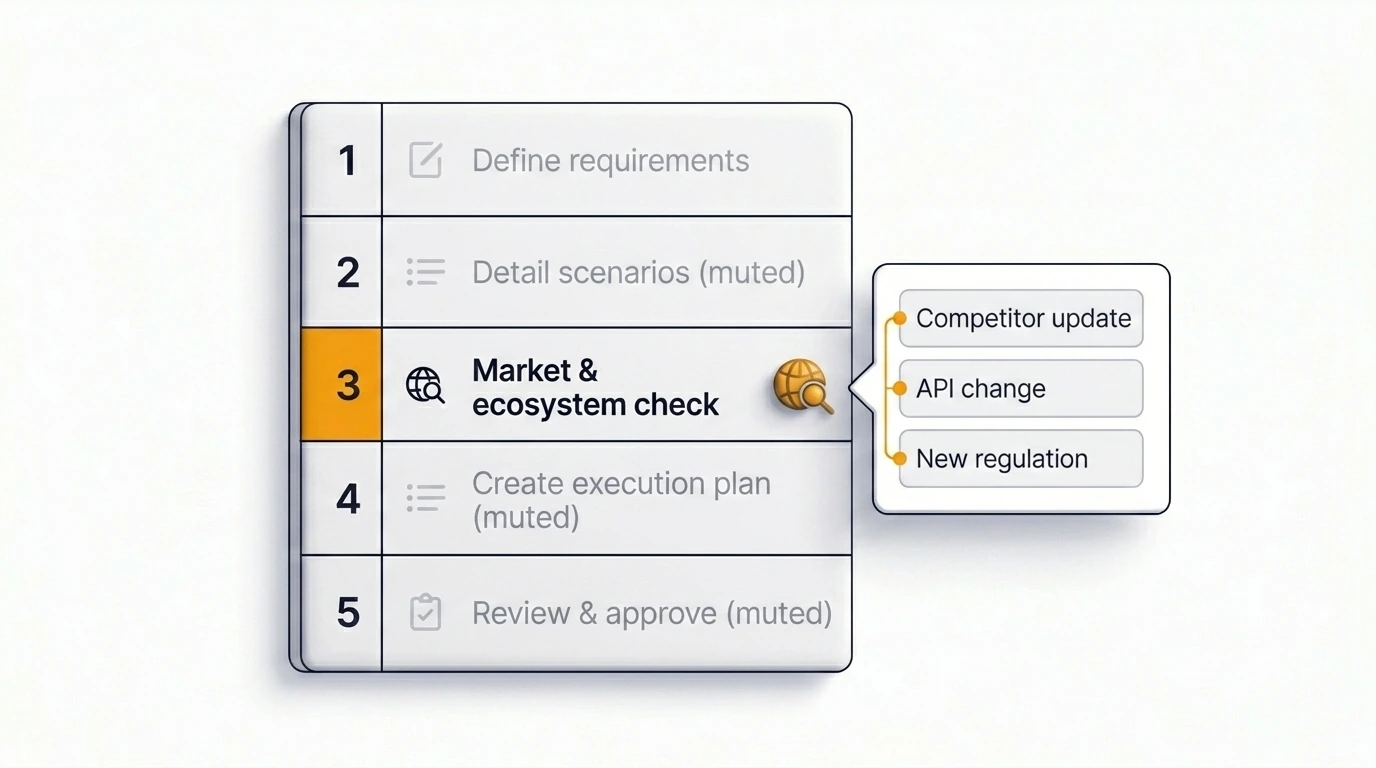
Just在规划和洞察流程中内置了一个网络搜索步骤——不是对每张工单都强制开启,而是让团队在外部背景重要的工单上选择启用。启用之后,Just会在生成计划之前拉取与issue相关的最新信息,把近期的依赖变更、竞品动态、监管信号和生态系统变化,直接带入结构化输出中。
结果是一份反映今天真实情况的计划,而不是模型训练时的情况。这是Atlassian生态系统中目前最直接地将实时市场调研整合进Jira规划的方式。
检查变成了一个步骤,而不是一个习惯。步骤能在团队变化中存续。习惯则不然。想直接看产品的话,可以去Just的Marketplace页面。
现在五分钟,还是之后一个sprint
市场不会在backlog变老的时候暂停。依赖库会发布破坏性变更。竞争对手会发布你正在做到一半的功能。法规会在和你的sprint日历毫无关系的日期生效。
工单写完到上线之间的那段时间,正是假设变质的地方。在sprint细化之前做一次快速的市场检查,不是额外的流程。这是对任何涉及会变动的东西的工单,应有的最低限度的审慎。