Votre IA a arrêté d'apprendre il y a six mois
Le ticket a été écrit le mois dernier. La fonctionnalité sort le mois prochain. Entre les deux, un concurrent a sorti quelque chose de similaire, une API a changé, et une exigence réglementaire est silencieusement entrée en vigueur.

L'écart entre la rédaction et la livraison
Le ticket a été écrit le mois dernier. La fonctionnalité sort le mois prochain. Entre les deux, un concurrent a sorti quelque chose de similaire, une API a changé, et une nouvelle obligation réglementaire est silencieusement entrée en vigueur. Rien de tout ça ne s'est retrouvé dans le ticket.
Ce n'est pas une hypothèse. C'est le standup du mardi en plein milieu du sprint. Quelqu'un dans l'équipe mentionne une API qui ne se comporte plus comme le ticket le décrit. Une autre personne ouvre le changelog d'un concurrent et découvre qu'ils ont lancé presque la même fonctionnalité il y a trois semaines. Le ticket était correct quand il a été écrit. Le monde a simplement avancé avant que le sprint ne le rattrape.
Le coût n'est pas seulement dans les retouches. Il est dans l'érosion de la confiance. Dans l'objectif de sprint qui devient silencieusement fictif. Dans le PM qui doit expliquer aux parties prenantes pourquoi l'équipe a livré quelque chose déjà dépassé dès le premier jour.
Chaque équipe a sa propre version de cette histoire. La plupart la raconte plus d'une fois avant de vraiment changer quelque chose.
L'IA a une date limite de connaissance
La plupart des équipes utilisent désormais l'IA pour rédiger, planifier et affiner les tickets Jira. Et ça fonctionne. Les modèles d'IA sont réellement bons pour structurer les exigences, générer des critères d'acceptation et proposer des approches d'implémentation. Pour comprendre le cadre plus large sur la raison pour laquelle les tickets vagues deviennent particulièrement dangereux quand on les confie directement à l'IA, l'article sur le problème d'alignement couvre ça en détail : Pourquoi la plupart des outils IA pour Jira aggravent le problème d'alignement au lieu de le résoudre.
Ce que la plupart des équipes ne prend pas en compte : les données d'entraînement de chaque modèle d'IA ont une date limite — typiquement six à douze mois avant la date actuelle. Le modèle ne sait pas ce qui s'est passé après la fin de son entraînement. Il ne spécule pas, il ne fait pas preuve de prudence. Il ne peut tout simplement pas le voir.
Ça signifie que le modèle ignore que Next.js 16.1 a abandonné le support de Node 18 en décembre 2025, cassant les builds des équipes qui misaient sur la compatibilité. Il ne sait pas qu'OpenAI a définitivement supprimé l'endpoint chatgpt-4o-latest en février 2026, rendant inopérantes toutes les intégrations qui référençaient encore cette chaîne. Il ne sait pas que trois États américains ont adopté des lois complètes sur la confidentialité des données le 1er janvier 2026, élargissant du jour au lendemain les exigences en matière de désinscription.
La connaissance de votre assistant IA s'arrête quelque part autour de six mois en arrière. Les réglementations, elles, n'attendent pas.
Ce n'est pas un problème de qualité du modèle — c'est structurel. Le modèle fait son travail dans les limites de ce sur quoi il a été entraîné. C'est dans l'écart entre cette limite et aujourd'hui que s'accumulent les changements cassants, que les concurrents lancent leurs nouveautés et que les exigences réglementaires évoluent. Si le processus de planification ne tient pas compte de cet écart, chaque ticket conçu avec l'aide de l'IA porte une date de péremption cachée.

Trois cas où ça fait vraiment mal
Ce ne sont pas des risques abstraits. Ce sont exactement les choses qui finissent dans les rétrospectives de sprint sous l'étiquette « on ne pouvait pas le prévoir » — alors qu'on aurait très bien pu, avec cinq minutes de recherche.
- Breaking changes dans les dépendances. Le ticket part du principe qu'une bibliothèque ou une API fonctionne toujours comme lors de la dernière intégration. L'équipe rédige le plan d'implémentation. À mi-sprint, les builds commencent à échouer ou les appels API renvoient des erreurs que personne n'attendait. C'est exactement ce qui s'est passé quand OpenAI a supprimé le snapshot
chatgpt-4o-latestle 17 février 2026. Toute équipe avec un ticket estimé fin 2025 et référençant cette chaîne de modèle s'est retrouvée bloquée — l'endpoint avait tout simplement cessé de répondre. - Les concurrents l'ont déjà sorti. Pas nécessairement une raison d'annuler le ticket, mais toujours une raison de regarder et d'apprendre avant de construire. Quand un concurrent a déjà lancé la même fonctionnalité, il a déjà documenté les cas limites, recueilli des retours utilisateurs et parfois heurté des murs contre lesquels vous n'avez pas à foncer. Cinq minutes de veille concurrentielle peuvent économiser deux semaines de discovery — ou éviter la démoralisation de livrer quelque chose que le marché a déjà dépassé.
- Changements réglementaires et de conformité. C'est le cas le plus sensible, car les conséquences ne se limitent pas à des sprints perdus — elles incluent une exposition juridique. Un ticket rédigé en novembre 2025 pour des utilisateurs américains ne tient pas compte des changements de loi sur la vie privée du 1er janvier 2026, à moins que quelqu'un n'ait vérifié avant le sprint. Les régulateurs ne créent pas de tickets Jira. Ils ne s'adaptent pas à votre calendrier de sprints.
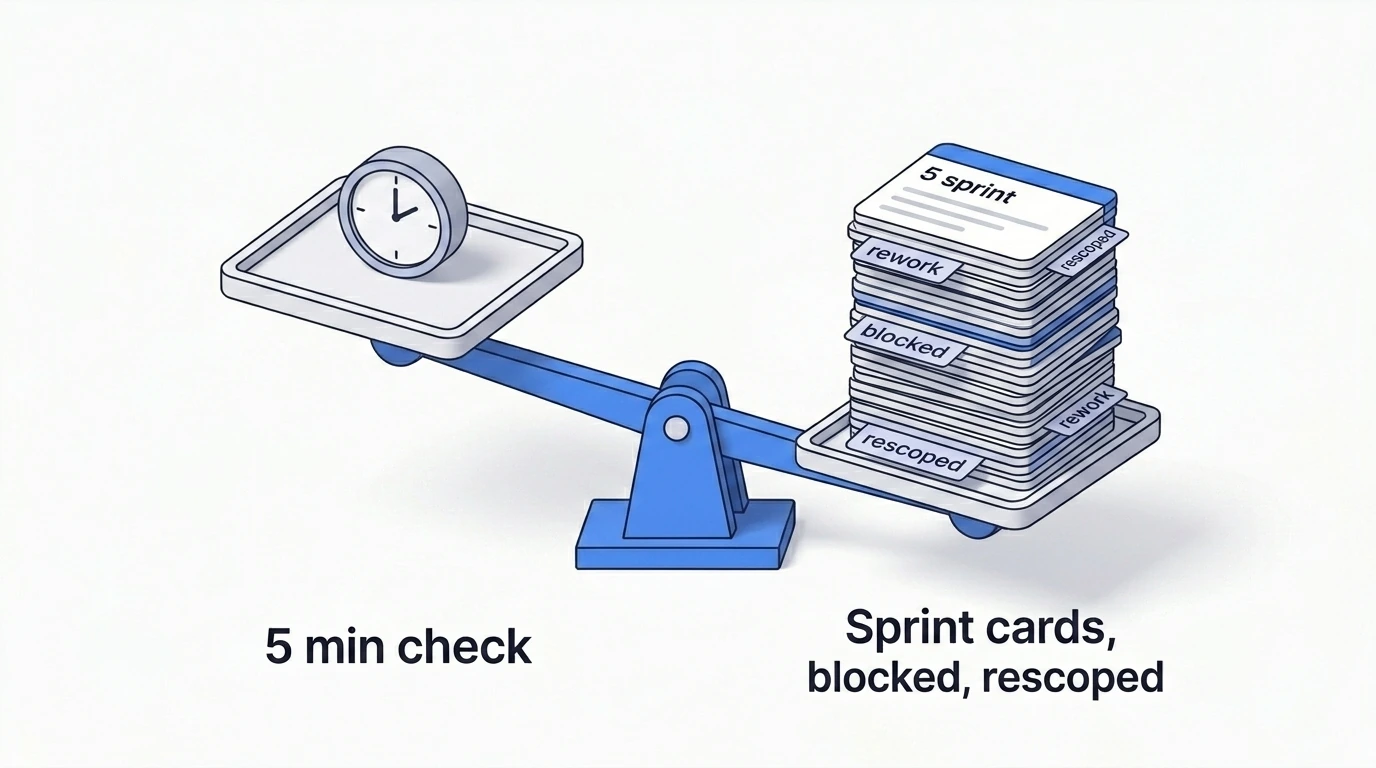
Quand faire cette vérification
Le timing compte plus que la vérification elle-même.
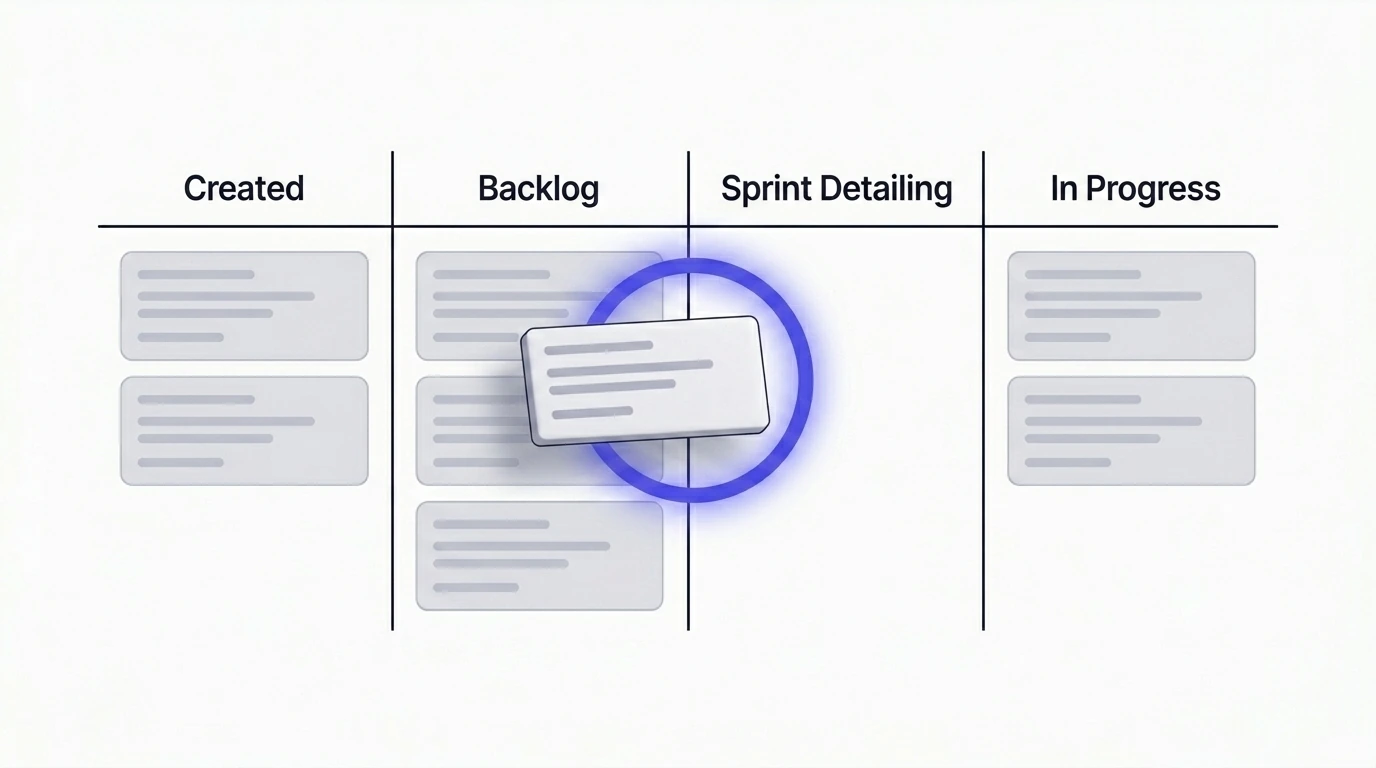
- Pas quand le ticket est créé. C'est trop tôt. Le ticket peut rester dans le backlog pendant des semaines ou des mois. Ce que vous vérifiez maintenant sera périmé quand quelqu'un le prendra enfin en main.
- Pas en plein sprint. C'est trop tard. L'équipe a déjà engagé sa capacité. Découvrir un breaking change ou un glissement réglementaire à ce stade signifie des retouches, des stories bloquées et un objectif de sprint qui n'est plus atteignable.
- Quand le ticket est détaillé et planifié pour le prochain sprint. C'est là que l'équipe investit déjà du temps réel dans le ticket — affiner la portée, écrire les sous-tâches, confirmer l'approche. Ajouter une vérification de marché de cinq à dix minutes à ce moment est peu coûteux et très rentable. Pour la structure de ce à quoi devrait ressembler un ticket prêt au développement après cette vérification, l'article sur les plans d'implémentation est le prolongement naturel : Transformer des tickets Jira vagues en plans d'implémentation clairs.
Ce qu'il faut vérifier avant de valider le ticket pour le sprint :
- Quelque chose a-t-il changé dans la dépendance ou la plateforme concernée depuis l'écriture du ticket ?
- Un concurrent a-t-il lancé ça, et qu'a-t-il appris ?
- Y a-t-il de nouveaux signaux réglementaires ou de conformité liés à ce domaine fonctionnel ?
- Existe-t-il de nouveaux outils, patterns ou approches qui n'existaient pas quand le ticket a été estimé ?
Ces quatre questions prennent quelques minutes. Les ignorer coûte des sprints.
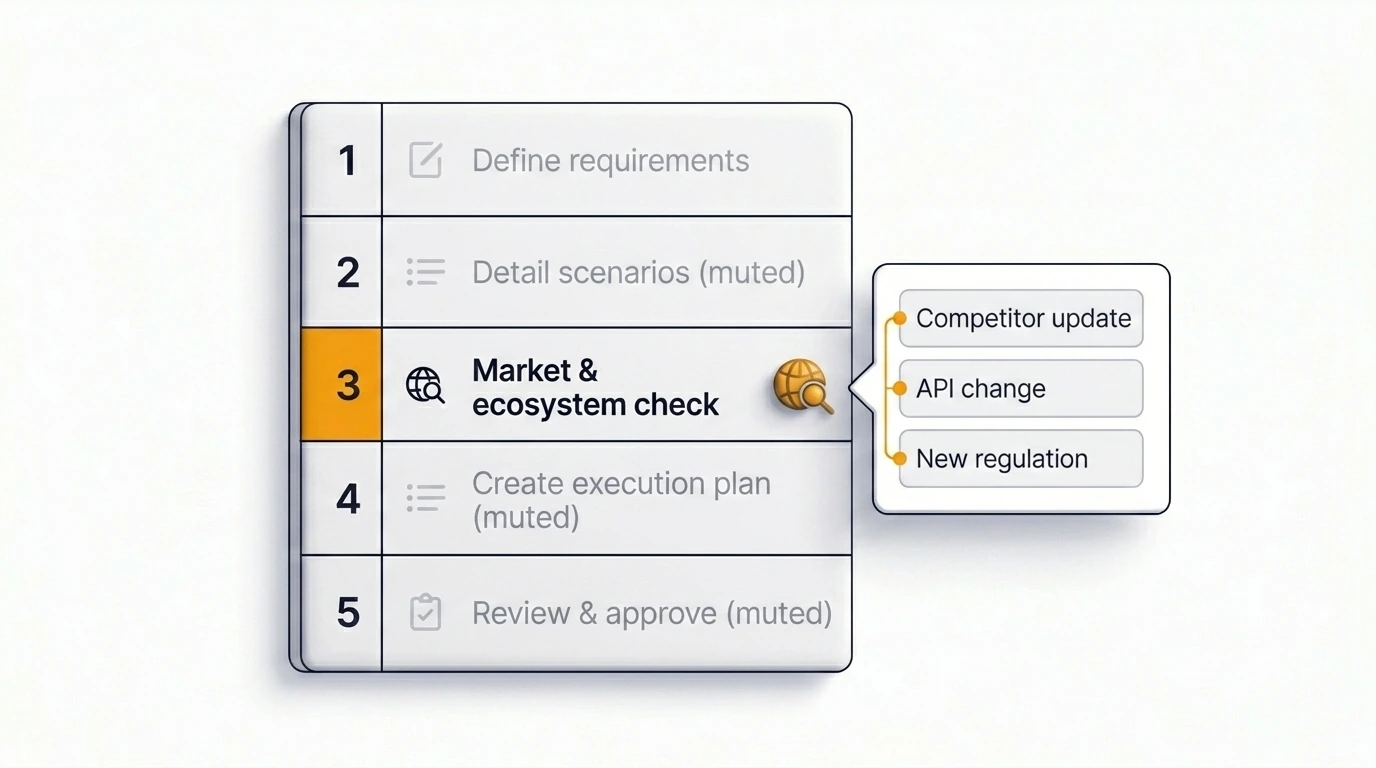
Comment Just automatise cette étape
La difficulté n'est pas de savoir qu'il faut vérifier. La difficulté est d'intégrer la vérification dans le processus plutôt que de la laisser dépendre de la mémoire d'une seule personne.
Just intègre une étape de recherche web directement dans le flux de planification et d'insights — pas comme un comportement par défaut sur chaque ticket, mais comme quelque chose que l'équipe active pour les tickets où le contexte externe compte. Lorsqu'elle est activée, Just récupère les informations actuelles pertinentes pour le ticket avant de générer le plan, faisant remonter les changements récents dans les dépendances, les patterns des concurrents, les signaux réglementaires et les évolutions de l'écosystème dans le résultat structuré.
Le résultat est un plan qui reflète ce qui est vrai aujourd'hui, pas ce qui était vrai quand le modèle a été entraîné. C'est l'intégration la plus directe de veille marché en temps réel dans la planification Jira actuellement disponible dans l'écosystème Atlassian.
La vérification devient une étape, pas une habitude. Les étapes résistent aux changements d'équipe. Les habitudes non. Si vous voulez voir le produit directement, il est sur la page Just dans le Marketplace.
Cinq minutes maintenant, ou un sprint plus tard
Le marché ne fait pas pause pendant que le backlog vieillit. Les dépendances introduisent des breaking changes. Les concurrents lancent la fonctionnalité que vous êtes en train de construire. Les réglementations entrent en vigueur à des dates qui n'ont rien à voir avec votre calendrier de sprints.
L'écart entre l'écriture d'un ticket et sa livraison, c'est là que les hypothèses deviennent obsolètes. Une vérification rapide du marché avant le détaillage du sprint n'est pas un processus supplémentaire. C'est la due diligence minimale pour tout ticket qui touche quelque chose qui bouge.