Twoje AI przestało się uczyć pół roku temu
Ticket powstał w zeszłym miesiącu. Funkcja wychodzi w przyszłym. W międzyczasie konkurent wypuścił coś podobnego, API się zmieniło, a nowy wymóg compliance po cichu wszedł w życie.

Przepaść między napisaniem a dostarczeniem
Ticket powstał w zeszłym miesiącu. Funkcja wychodzi w przyszłym. W międzyczasie konkurent wypuścił coś podobnego, API się zmieniło, a nowy obowiązkowy wymóg po cichu wszedł w życie. Nic z tego nie wróciło do ticketu.
To nie jest scenariusz hipotetyczny. To wtorkowy standup w środku sprintu. Ktoś z zespołu wspomina API, które zachowuje się inaczej, niż opisuje ticket. Inna osoba otwiera changelog konkurenta i odkrywa, że trzy tygodnie temu wypuścili niemal tę samą funkcję. Ticket był w porządku, kiedy powstawał. Świat po prostu wyprzedził sprint.
Koszt nie tkwi tylko w przeróbkach. Tkwi w erozji zaufania. W celu sprintu, który po cichu staje się fikcją. W PM tłumaczącym stakeholderom, dlaczego zespół dostarczył coś, co było przestarzałe już pierwszego dnia.
Każdy zespół ma swoją wersję tej historii. Większość opowiada ją więcej niż raz, zanim cokolwiek zmieni.
AI ma granicę wiedzy
Większość zespołów używa już AI do pisania, planowania i doprecyzowywania ticketów Jira. I to działa. Modele AI naprawdę dobrze strukturyzują wymagania, generują kryteria akceptacji i sugerują podejścia implementacyjne. Kto chce zrozumieć szerszy kontekst — dlaczego mgliste tickety stają się szczególnie niebezpieczne, gdy oddaje się je bezpośrednio AI — znajdzie szczegółowe omówienie w tym artykule: Dlaczego większość narzędzi AI dla Jira pogarsza problem dopasowania zamiast go rozwiązywać.
Czego większość zespołów nie uwzględnia: dane treningowe każdego modelu AI mają datę graniczną — zazwyczaj od sześciu do dwunastu miesięcy przed aktualną datą. Model nie wie, co wydarzyło się po zakończeniu treningu. Nie spekuluje, nie jest ostrożny. Po prostu tego nie widzi.
To oznacza, że model nie wie, że Next.js 16.1 usunął wsparcie dla Node 18 w grudniu 2025, psując buildy zespołów zakładających kompatybilność. Nie wie, że OpenAI w lutym 2026 trwale usunął endpoint chatgpt-4o-latest, niszcząc każdą integrację, która nadal odwoływała się do tego stringa. Nie wie, że trzy stany USA uchwaliły 1 stycznia 2026 kompleksowe przepisy o prywatności, rozszerzając wymagania dotyczące opt-outu z dnia na dzień.
Wiedza twojego asystenta AI urywa się gdzieś jakieś sześć miesięcy temu. Prawo i platformy nie czekają.
To nie jest problem z jakością modelu — to problem strukturalny. Model robi swoje w granicach tego, na czym był trenowany. W przestrzeni między tą granicą a dzisiejszym dniem nawarstwiają się breaking changes, konkurenci wypuszczają nowości i przesuwają się wymogi compliance. Jeśli proces planowania nie uwzględnia tej przestrzeni, każdy ticket tworzony z pomocą AI nosi ukrytą datę przydatności.

Trzy sytuacje, w których to naprawdę boli
To nie są abstrakcyjne ryzyka. Są to dokładnie te rzeczy, które w retrospektywach sprintu pojawiają się pod etykietą „nie mogliśmy tego przewidzieć" — podczas gdy w istocie można było, poświęcając pięć minut na sprawdzenie.
- Breaking changes w zależnościach. Ticket zakłada, że biblioteka lub API działa tak samo, jak podczas ostatniej integracji. Zespół pisze plan implementacji. W połowie sprintu buildy zaczynają padać albo wywołania API zwracają błędy, których nikt się nie spodziewał. Dokładnie to przydarzyło się, gdy OpenAI 17 lutego 2026 usunął snapshot
chatgpt-4o-latest. Każdy zespół z ticketem wycenionym pod koniec 2025, który odwoływał się do tego stringa, uderzył w ścianę — endpoint po prostu przestał odpowiadać. - Konkurencja już to wypuściła. Niekoniecznie jest to powód do anulowania ticketu, ale zawsze powód do sprawdzenia i nauki przed budowaniem. Gdy konkurent wypuścił już tę samą funkcję, zdążył udokumentować edge cases, zebrać feedback od użytkowników i niekiedy natknąć się na ściany, o które ty nie musisz się rozbijać. Pięć minut analizy konkurencji może zaoszczędzić dwa tygodnie discovery — lub uchronić przed demoralizacją z powodu dostarczenia czegoś, co rynek już minął.
- Zmiany regulacyjne i compliance. To przypadek o najwyższej stawce, bo konsekwencje to nie tylko stracone sprinty — to ryzyko prawne. Ticket napisany w listopadzie 2025 z myślą o użytkownikach z USA nie uwzględni zmian w przepisach o prywatności z 1 stycznia 2026, jeśli nikt nie sprawdzi przed sprintem. Regulatorzy nie tworzą ticketów Jira. Nie czekają na twój cykl sprintów.
Kiedy wykonywać to sprawdzenie
Moment jest ważniejszy niż samo sprawdzenie.
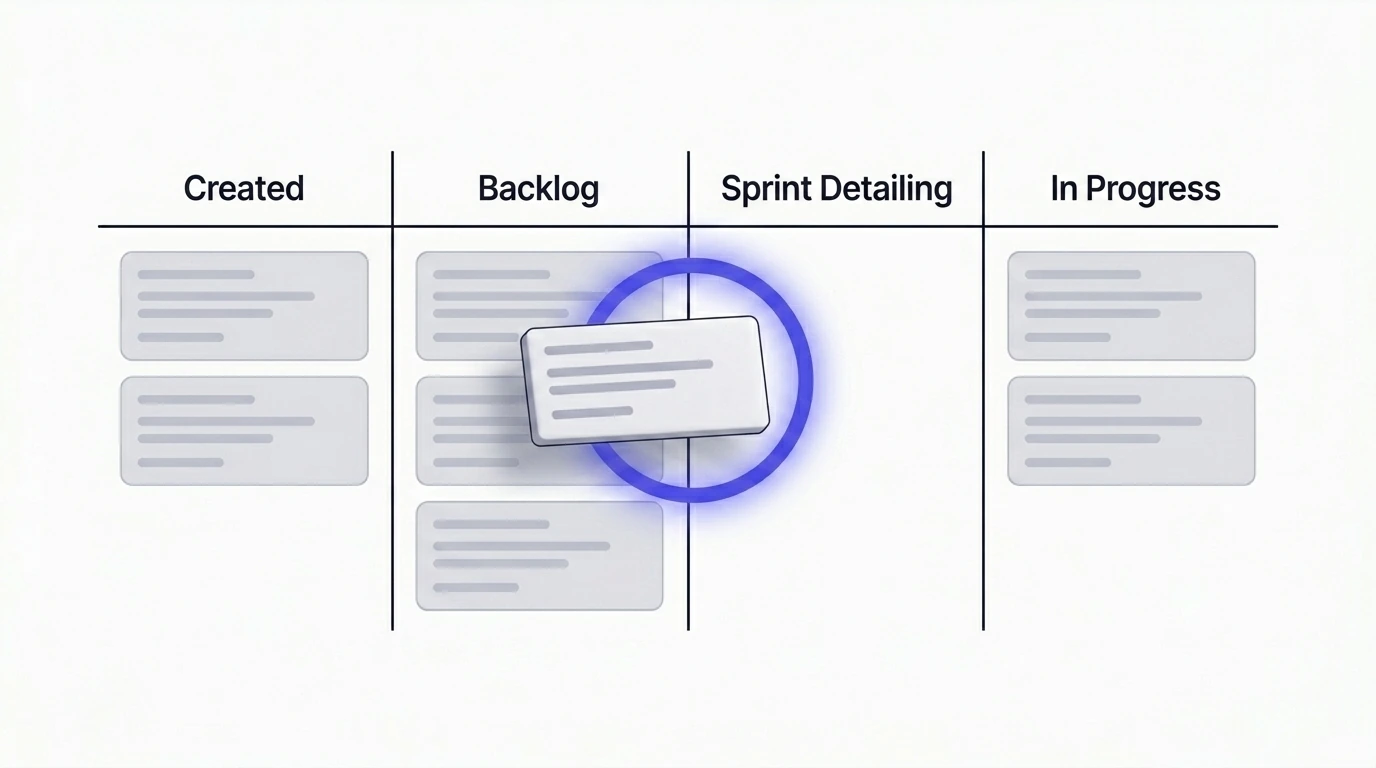
- Nie w chwili tworzenia ticketu. To za wcześnie. Ticket może leżeć w backlogu tygodniami lub miesiącami. To, co sprawdzisz teraz, będzie nieaktualne, gdy ktoś faktycznie go podejmie.
- Nie w trakcie sprintu. To za późno. Zespół już zaangażował pojemność. Odkrycie breaking change lub przesunięcia regulacyjnego w tym momencie oznacza przeróbki, zablokowane stories i cel sprintu, który jest już nieosiągalny.
- Gdy ticket jest doprecyzowywany i planowany na kolejny sprint. To właśnie wtedy zespół i tak inwestuje w niego realny czas — doprecyzowuje zakres, pisze podzadania, potwierdza podejście. Dodanie w tym momencie pięcio-dziesięciominutowego przeglądu rynku ma niski koszt i wysoki zwrot. Kto szuka struktury gotowego do wdrożenia ticketu po takim sprawdzeniu, znajdzie naturalne uzupełnienie tu: Przekształcanie mglistych ticketów Jira w klarowne plany implementacji.
Co sprawdzić przed ostatecznym wciągnięciem ticketu do sprintu:
- Czy w istotnej zależności lub platformie coś się zmieniło od momentu napisania ticketu?
- Czy konkurent już to wypuścił i czego się przy tym nauczył?
- Czy pojawiły się nowe sygnały regulacyjne lub compliance istotne dla tego obszaru funkcjonalności?
- Czy istnieją nowe narzędzia, wzorce lub podejścia, których nie było, gdy ticket był wyceniany?
Te cztery pytania zajmują minuty. Ich pominięcie kosztuje sprinty.
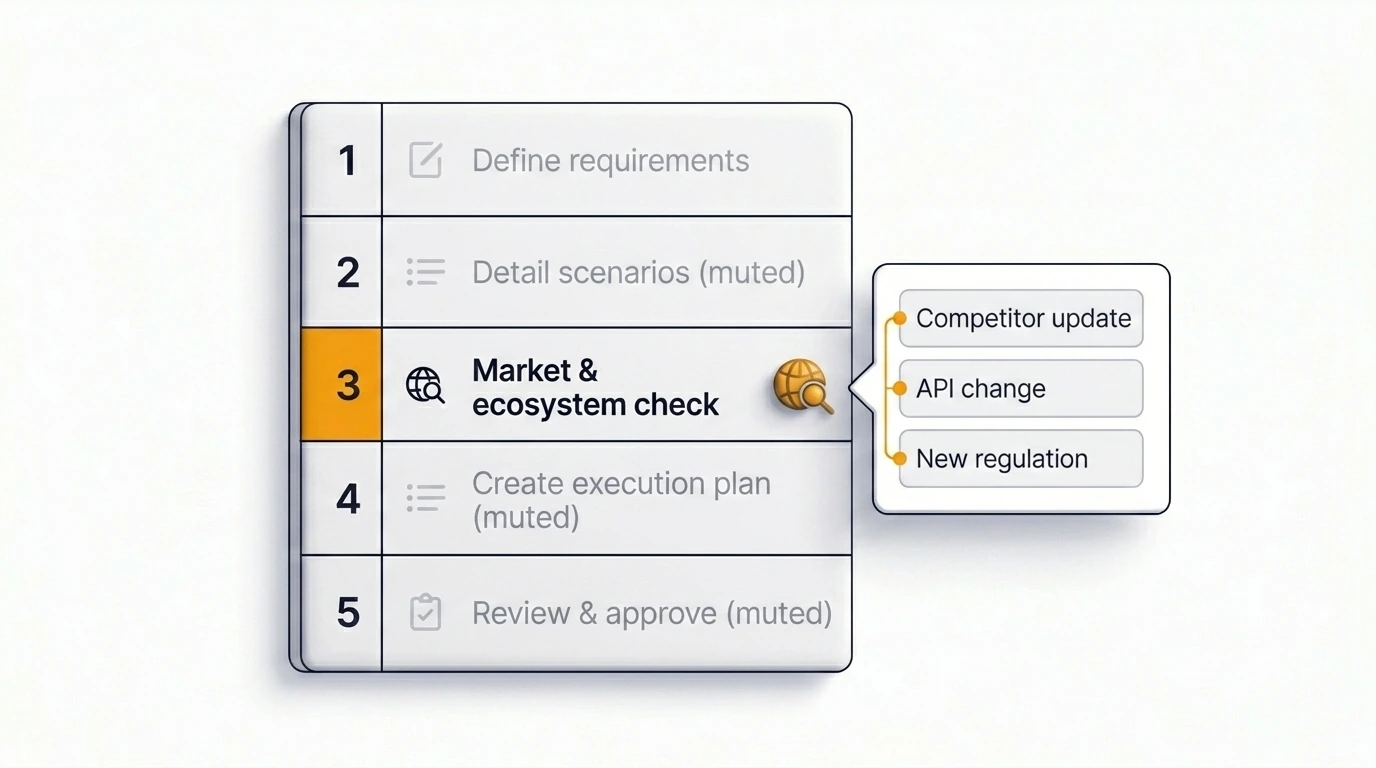
Jak Just automatyzuje ten krok
Najtrudniejsza część to nie wiedzieć, że powinieneś sprawdzić. Najtrudniejsza część to sprawić, żeby sprawdzenie stało się elementem procesu, a nie czymś zależnym od pamięci jednej osoby.
Just zawiera krok wyszukiwania w internecie bezpośrednio w przepływie planowania i insightów — nie jako domyślny element dla każdego ticketu, ale jako coś, co zespół włącza dla ticketów, w których liczy się kontekst zewnętrzny. Po włączeniu Just pobiera aktualne informacje istotne dla zgłoszenia, zanim wygeneruje plan — niedawne zmiany w zależnościach, wzorce konkurencji, sygnały regulacyjne i przesunięcia ekosystemowe trafiają bezpośrednio do ustrukturyzowanego wyniku.
Efektem jest plan odzwierciedlający to, co jest prawdą dziś — a nie to, co było prawdą w dniu trenowania modelu. To najbardziej bezpośrednia integracja aktualnego rozpoznania rynku z planowaniem w Jira, jaka jest obecnie dostępna w ekosystemie Atlassian.
Sprawdzenie staje się krokiem, nie nawykiem. Kroki przeżywają zmiany w zespole. Nawyki nie. Kto chce zobaczyć produkt bezpośrednio, znajdzie go na stronie Just w Marketplace.
Pięć minut teraz — albo cały sprint potem
Rynek nie pauzuje, gdy backlog się starzeje. Zależności wypuszczają breaking changes. Konkurenci lansują funkcję, którą ty dopiero budujesz. Przepisy wchodzą w życie w datach, które nie mają nic wspólnego z twoim kalendarzem sprintów.
Przestrzeń między napisaniem ticketu a jego dostarczeniem to miejsce, gdzie założenia się dezaktualizują. Szybki przegląd rynku przed uszczegółowieniem sprintu to nie dodatkowy proces. To minimalny poziom staranności dla każdego ticketu, który dotyka czegoś, co się porusza.