Your AI Stopped Learning Six Months Ago
The ticket was written last month. The feature ships next month. In between, a competitor shipped, an API changed, and a compliance rule quietly went live.

The Gap Between Writing and Shipping
The ticket was written last month. The feature ships next month. In between, a competitor shipped something similar, an API changed, and a new compliance requirement quietly went into effect. None of that made it back into the ticket.
This is not a hypothetical. It is Tuesday standup, mid-sprint. Someone mentions an API that no longer behaves the way the ticket describes. Another person opens a competitor's changelog and finds they launched almost the same feature three weeks ago. The ticket was fine when it was written. The world simply moved before the sprint did.
The cost here is not just the rework. It is the trust erosion. It is the sprint goal that quietly becomes fictional. It is the PM explaining to stakeholders why the team shipped something that was already outdated on day one.
Every team has a version of this story. Most teams tell it more than once before they change anything.
AI Has a Knowledge Cutoff
Most teams are now using AI to help write, plan, and refine Jira tickets. That part is working. AI models are genuinely good at structuring requirements, generating acceptance criteria, and suggesting implementation approaches. If you want the bigger framing for why vague tickets become dangerous once teams hand them directly to AI, the alignment problem article covers that in detail: Why Most AI Tools for Jira Make the Alignment Problem Worse — Not Better.
What most teams do not factor in is that every AI model's training data has a cutoff — typically six to twelve months behind the current date. The model does not know what happened after its training ended. It is not guessing or hedging. It simply cannot see it.
That means the model does not know that Next.js 16.1 dropped Node 18 support in December 2025, breaking builds for teams that assumed compatibility. It does not know that OpenAI permanently removed the chatgpt-4o-latest model endpoint in February 2026, killing any integration still referencing that string. It does not know that three US states enacted comprehensive privacy laws on January 1, 2026, expanding data opt-out requirements overnight.
Your AI assistant's knowledge cuts off somewhere around six months ago. Regulations don't.
This is not a model quality problem. It is structural. The model is doing its job within the boundaries of what it was trained on. The gap between that boundary and today is where breaking changes accumulate, competitors ship, and compliance requirements shift. If your planning workflow does not account for that gap, every AI-assisted ticket carries a hidden expiration date.

Three Cases Where This Actually Bites
These are not abstract risks. These are the kinds of things that show up in sprint retrospectives with the label "could not have predicted" — except you absolutely could have, with five minutes of research.
- Breaking changes in dependencies. Your ticket assumes a library or API behaves the way it did when someone last integrated it. You write the implementation plan. The team picks it up. Mid-sprint, builds start failing or API calls return errors nobody expected. This is exactly what happened when OpenAI removed the
chatgpt-4o-latestmodel snapshot on February 17, 2026. Any team with a ticket scoped in late 2025 referencing that model string hit a wall because the endpoint simply stopped responding. - Competitors already shipped this. Not necessarily a reason to cancel the ticket, but always a reason to learn before building. When a competitor ships the same feature, they have already documented edge cases, collected user feedback, and sometimes hit walls you do not have to hit. Five minutes of competitor research can save two weeks of discovery or prevent the demoralization of shipping something the market already moved past.
- Regulatory and compliance shifts. This is the highest-stakes case because the consequences are not just wasted sprints — they are legal exposure. A feature ticket written in November 2025 targeting US users would not account for January 1, 2026 privacy-law changes unless someone checked before the sprint. Regulations do not file Jira tickets. They do not wait for your sprint cycle.
When to Do This Check
Timing matters more than the check itself.
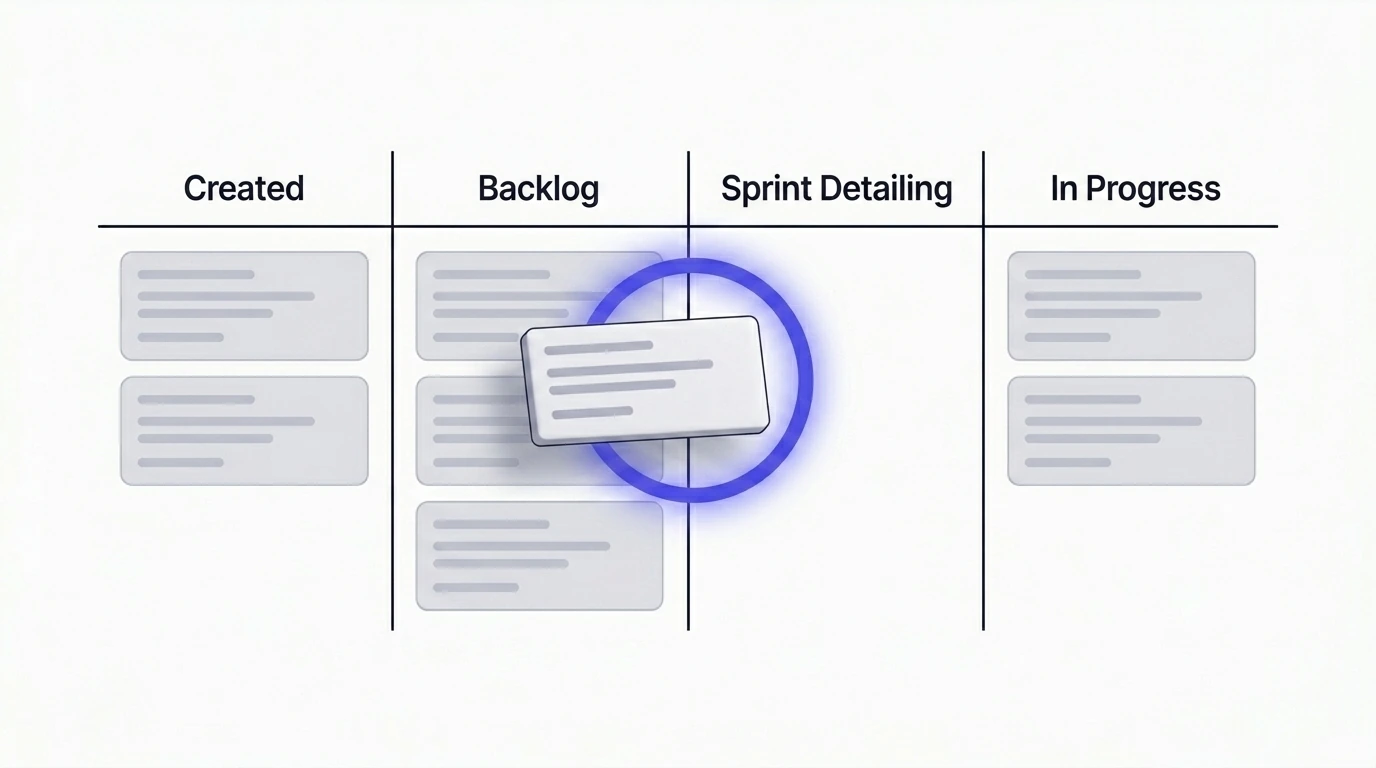
- Not when the ticket is created. That is too early. The ticket may sit in the backlog for weeks or months. Whatever you check now will be stale by the time someone picks it up.
- Not mid-sprint. That is too late. The team has already committed capacity. Discovering a breaking change or a regulatory shift at this point means rework, blocked stories, and a sprint goal that is no longer achievable.
- When the ticket is being detailed and scheduled for the next sprint. This is when the team is already investing real time in the ticket — refining scope, writing subtasks, confirming approach. Adding a five-to-ten-minute market check at this point is low cost and high return. For the structure of what a build-ready ticket should look like after this check, the implementation-plan article is the natural follow-up: Turning Vague Jira Tickets into Clear Implementation Plans.
What to check before committing the ticket to sprint:
- Has anything changed in the relevant dependency or platform since the ticket was written?
- Has a competitor shipped this, and what did they learn?
- Are there any recent regulatory or compliance signals relevant to this feature area?
- Are there new tools, patterns, or approaches that did not exist when the ticket was scoped?
These four questions take minutes. Skipping them costs sprints.
How Just Automates This Step
The hard part is not knowing you should check. The hard part is making the check part of the workflow instead of something that depends on one person remembering.
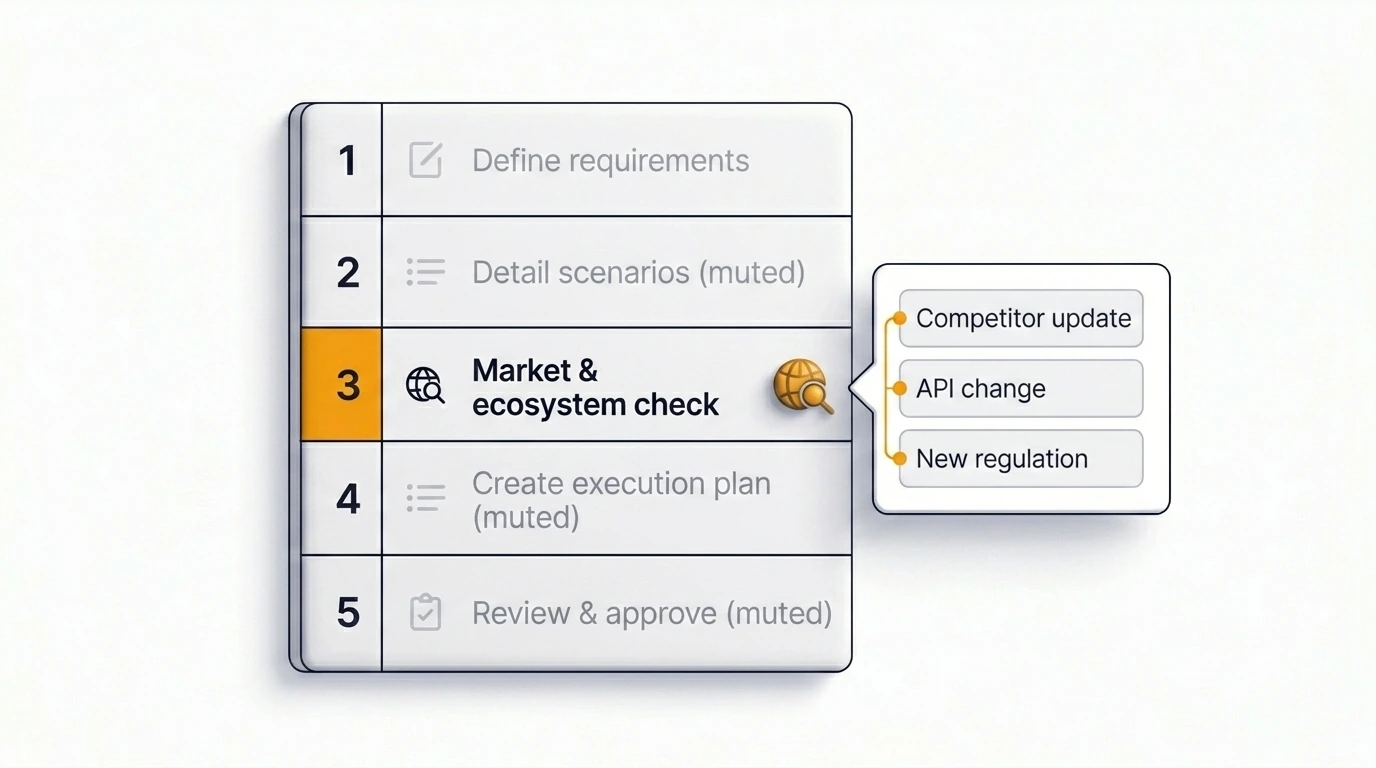
Just includes a web search step inside the planning and insight flow — not as a blanket default on every ticket, but as something the team opts into for tickets where external context matters. When enabled, Just pulls current information relevant to the issue before generating the plan, surfacing recent dependency changes, competitor patterns, regulatory signals, and ecosystem shifts as part of the structured output.
The result is a plan that reflects what is actually true today, not what was true when the AI model was trained. This is the most direct integration of real-time market research into Jira planning currently available in the Atlassian ecosystem.
The check becomes a step, not a habit. Steps survive team changes. Habits do not. If you want to see the product directly, it is on the Just Marketplace page.
Five Minutes Now, or a Sprint Later
The market does not pause while the backlog ages. Dependencies ship breaking changes. Competitors launch the feature you are halfway through building. Regulations go into effect on dates that have nothing to do with your sprint calendar.
The gap between when a ticket is written and when it ships is where assumptions go stale. A quick market check before sprint detailing is not extra process. It is the minimum due diligence for any ticket that touches something that moves.