आपके AI ने छह महीने पहले सीखना बंद कर दिया
टिकट पिछले महीने लिखा गया था। फीचर अगले महीने शिप होगा। इस बीच एक प्रतिस्पर्धी ने कुछ मिलता-जुलता लॉन्च किया, एक API बदल गया, और एक compliance आवश्यकता चुपचाप लागू हो गई।

लिखने और डिलीवर करने के बीच का अंतर
टिकट पिछले महीने लिखा गया था। फीचर अगले महीने जाएगा। इस बीच, एक प्रतिस्पर्धी ने कुछ ऐसा ही लॉन्च किया, एक API बदल गई, और एक नई अनिवार्य आवश्यकता चुपचाप लागू हो गई। इनमें से कुछ भी टिकट में वापस नहीं आया।
यह कोई काल्पनिक बात नहीं है। यह Sprint के बीच में मंगलवार का standup है। टीम का कोई सदस्य एक ऐसे API का जिक्र करता है जो अब टिकट में बताए गए तरीके से काम नहीं करती। कोई दूसरा व्यक्ति प्रतिस्पर्धी का changelog खोलता है और पाता है कि उन्होंने तीन हफ्ते पहले लगभग वही फीचर लॉन्च किया था। टिकट तब ठीक था जब लिखा गया था। दुनिया बस sprint शुरू होने से पहले आगे बढ़ गई।
यहां नुकसान सिर्फ दोबारा काम करने में नहीं है। भरोसे के क्षरण में है। उस sprint लक्ष्य में जो चुपचाप कल्पना बन जाता है। उस PM में जो stakeholders को समझाता है कि टीम ने कुछ ऐसा क्यों शिप किया जो पहले दिन से ही पुराना था।
हर टीम के पास इस कहानी का अपना संस्करण होता है। ज्यादातर टीमें कुछ बदलने से पहले इसे एक से अधिक बार सुनाती हैं।
AI की एक ज्ञान सीमा होती है
अब ज्यादातर टीमें Jira टिकट लिखने, योजना बनाने और बेहतर बनाने में AI की मदद लेती हैं। और यह काम करता है। AI मॉडल वास्तव में आवश्यकताओं को संरचित करने, acceptance criteria बनाने और implementation approach सुझाने में अच्छे हैं। यदि आप यह समझना चाहते हैं कि अस्पष्ट टिकट AI को सीधे सौंपने पर खासतौर पर खतरनाक क्यों बन जाते हैं, तो alignment problem वाला लेख इसे विस्तार से कवर करता है: Jira के लिए अधिकतर AI टूल Alignment Problem को बेहतर नहीं बल्कि बदतर क्यों बनाते हैं।
जो बात अधिकांश टीमें नहीं सोचतीं वह यह है कि हर AI मॉडल के training data की एक cutoff date होती है — आमतौर पर मौजूदा तारीख से छह से बारह महीने पहले। मॉडल को नहीं पता कि उसकी ट्रेनिंग खत्म होने के बाद क्या हुआ। वह अनुमान नहीं लगा रहा, सावधान नहीं हो रहा। वह बस देख नहीं सकता।
इसका मतलब है कि मॉडल को नहीं पता कि Next.js 16.1 ने दिसंबर 2025 में Node 18 का समर्थन हटा दिया, जिससे compatibility मान कर चल रहे टीमों के builds टूट गए। उसे नहीं पता कि OpenAI ने फरवरी 2026 में chatgpt-4o-latest मॉडल endpoint स्थायी रूप से हटा दिया, जिससे उस string को reference करने वाला कोई भी integration टूट गया। उसे नहीं पता कि अमेरिका के तीन राज्यों ने 1 जनवरी 2026 को व्यापक गोपनीयता कानून लागू किए, जिसने रातोरात data opt-out आवश्यकताओं का विस्तार कर दिया।
आपके AI सहायक की जानकारी लगभग छह महीने पहले रुक गई। कानून और प्लेटफॉर्म इंतजार नहीं करते।
यह मॉडल की गुणवत्ता की समस्या नहीं है — यह संरचनात्मक है। मॉडल उसी के दायरे में काम करता है जिस पर उसे train किया गया था। उस सीमा और आज के बीच की खाई में ही breaking changes जमा होते हैं, प्रतिस्पर्धी ship करते हैं, और compliance आवश्यकताएं बदलती हैं। यदि आपकी योजना प्रक्रिया इस खाई का हिसाब नहीं रखती, तो AI-सहायता से बना हर टिकट एक छुपी हुई expiry date लेकर चलता है।

तीन मामले जहां यह सच में तकलीफ देता है
ये abstract जोखिम नहीं हैं। ये वही चीजें हैं जो Sprint retrospectives में "हम इसका अनुमान नहीं लगा सकते थे" के लेबल के साथ आती हैं — जबकि पांच मिनट की research से इसका बिल्कुल अनुमान लगाया जा सकता था।
- Dependencies में breaking changes। टिकट मानता है कि एक library या API उसी तरह काम कर रही है जैसे आखिरी बार integrate की गई थी। टीम implementation plan लिखती है। Sprint के बीच में builds fail होने लगती हैं या API calls ऐसे errors देती हैं जिनकी किसी को उम्मीद नहीं थी। यह ठीक वही है जो तब हुआ जब OpenAI ने 17 फरवरी 2026 को
chatgpt-4o-latestsnapshot हटाया। 2025 के अंत में estimate किए गए और उस model string को reference करने वाले हर टीम के टिकट दीवार से टकराए — क्योंकि endpoint ने जवाब देना ही बंद कर दिया। - Competitors पहले ही यह ship कर चुके हैं। जरूरी नहीं कि यह टिकट cancel करने का कारण हो, लेकिन बनाने से पहले सीखने का कारण हमेशा होता है। जब कोई competitor वही feature पहले ही launch कर चुका है, तो उसने edge cases document कर लिए हैं, user feedback इकट्ठा कर लिया है, और कभी-कभी उन दीवारों से टकरा चुका है जिनसे आपको टकराने की जरूरत नहीं है। Competitor research पर पांच मिनट खर्च करने से दो हफ्तों की discovery बच सकती है — या यह निराशा टल सकती है कि आपने कुछ ऐसा ship किया जो market पहले ही पार कर चुका था।
- नियामक और compliance बदलाव। यह सबसे जोखिम भरा मामला है क्योंकि परिणाम सिर्फ बर्बाद sprints नहीं हैं — कानूनी खतरा भी है। नवंबर 2025 में US users के लिए लिखा गया टिकट 1 जनवरी 2026 के गोपनीयता कानून बदलावों का हिसाब नहीं रखेगा, जब तक कोई sprint से पहले जांच न करे। नियामक Jira tickets नहीं खोलते। वे आपके sprint cycle का इंतजार नहीं करते।
यह जांच कब करें
समय खुद जांच से ज्यादा मायने रखता है।
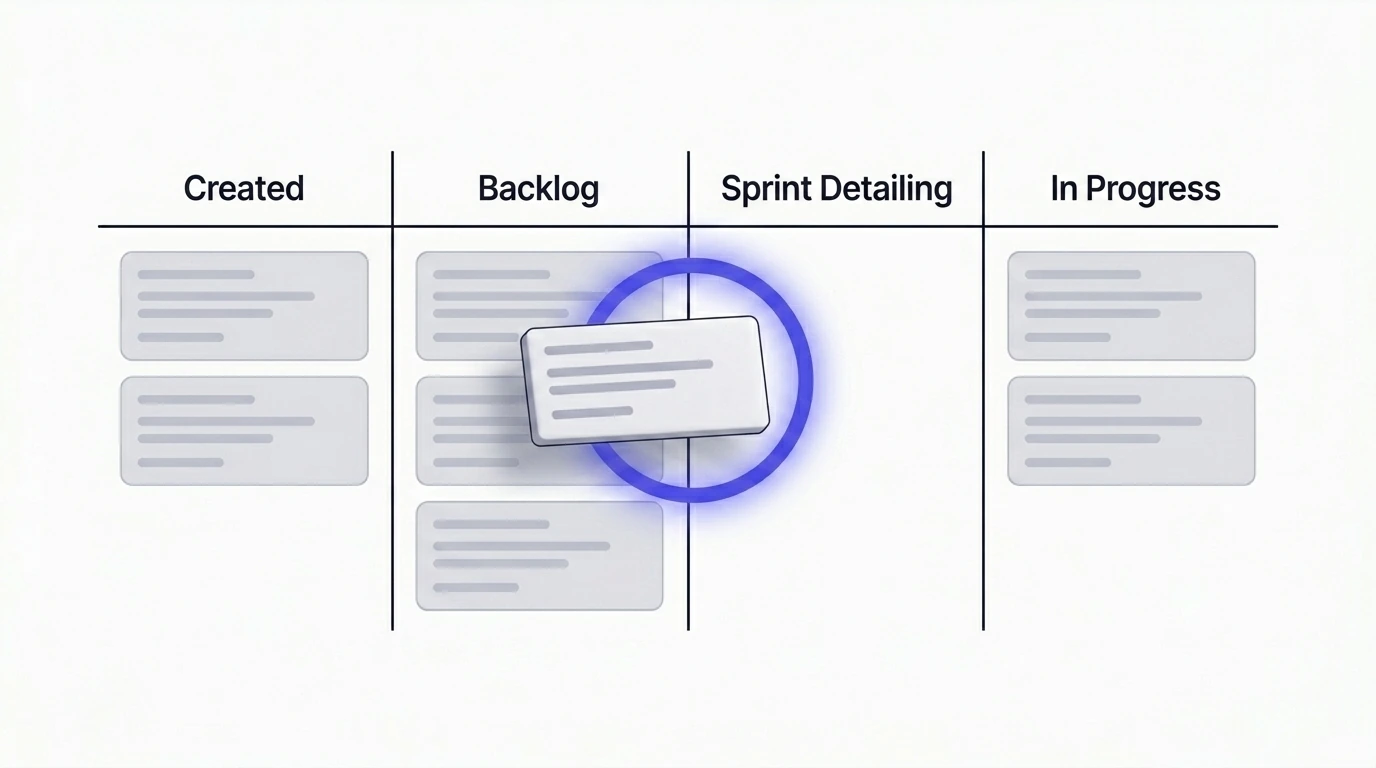
- जब टिकट बनाया जाए, तब नहीं। यह बहुत जल्दी है। टिकट हफ्तों या महीनों backlog में पड़ा रह सकता है। आप अभी जो जांचेंगे वह तब तक पुराना हो जाएगा जब कोई इसे उठाएगा।
- Sprint के बीच में भी नहीं। यह बहुत देर हो चुकी है। टीम पहले ही capacity commit कर चुकी है। इस बिंदु पर breaking change या regulatory shift पता चलना मतलब है दोबारा काम, blocked stories और sprint goal जो अब achievable नहीं रहा।
- जब टिकट detail किया जा रहा हो और अगले sprint के लिए schedule किया जा रहा हो। ठीक उसी समय जब टीम पहले से ही टिकट में real time लगा रही होती है — scope refine करना, subtasks लिखना, approach confirm करना। इस समय पांच से दस मिनट की market check जोड़ना कम लागत में ज्यादा फायदा देता है। इस जांच के बाद development-ready टिकट कैसा दिखना चाहिए इसकी structure के लिए, implementation plan article प्राकृतिक अगला कदम है: अस्पष्ट Jira Tickets को स्पष्ट Implementation Plans में बदलना।
Sprint में टिकट commit करने से पहले जांचें:
- क्या टिकट लिखे जाने के बाद से relevant dependency या platform में कुछ बदला है?
- क्या किसी competitor ने यह ship किया है, और उन्होंने क्या सीखा?
- क्या इस feature area से जुड़े कोई हालिया regulatory या compliance signals हैं?
- क्या ऐसे नए tools, patterns या approaches हैं जो टिकट scope होने के समय मौजूद नहीं थे?
ये चार सवाल मिनटों में पूछे जा सकते हैं। इन्हें छोड़ने की कीमत पूरे sprints होती है।
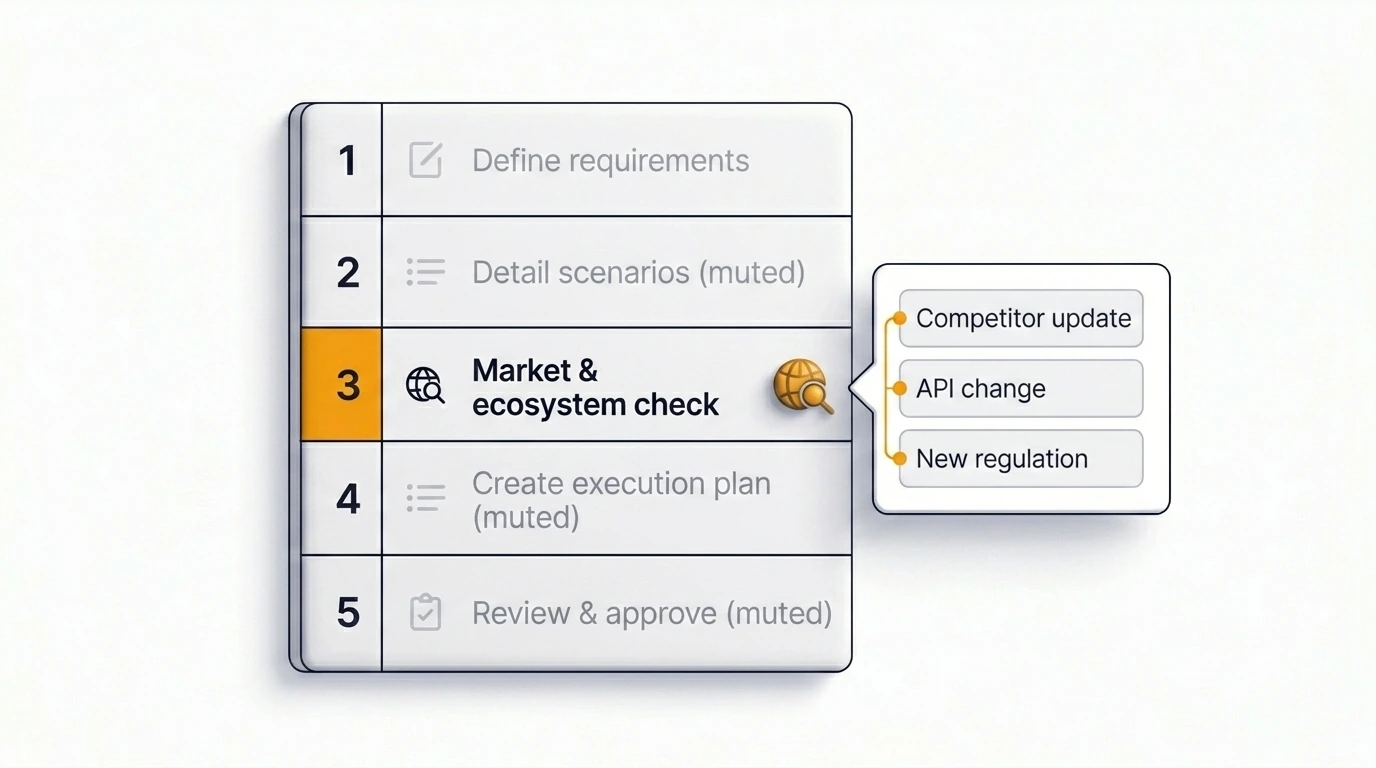
Just इस कदम को कैसे automate करता है
मुश्किल हिस्सा यह जानना नहीं है कि आपको जांच करनी चाहिए। मुश्किल हिस्सा है जांच को एक ऐसी चीज बनाना जो process का हिस्सा हो, न कि किसी एक व्यक्ति की याददाश्त पर निर्भर हो।
Just planning और insight flow के अंदर एक web search step शामिल करता है — हर टिकट पर blanket default के रूप में नहीं, बल्कि कुछ ऐसा जिसे team उन टिकटों पर enable करती है जहां external context मायने रखता है। Enable होने पर, Just plan generate करने से पहले issue के लिए relevant current information pull करता है, जिसमें हाल के dependency changes, competitor patterns, regulatory signals और ecosystem shifts structured output के रूप में सामने आते हैं।
परिणाम एक ऐसा plan है जो आज वास्तव में सच है उसे reflect करता है, न कि वह जो AI model train होने के समय सच था। यह Atlassian ecosystem में currently available Jira planning में real-time market research का सबसे direct integration है।
जांच एक habit नहीं, एक step बन जाती है। Steps team changes में survive करते हैं। Habits नहीं। अगर product सीधे देखना हो तो यह Just के Marketplace page पर है।
अभी पांच मिनट — या बाद में एक पूरा Sprint
Backlog पुराना होते समय market रुकता नहीं। Dependencies breaking changes ship करती हैं। Competitors वह feature launch करते हैं जिसे आप अभी आधा बना रहे हैं। नियम ऐसी तारीखों पर लागू होते हैं जिनका आपके sprint calendar से कोई लेना-देना नहीं।
एक टिकट लिखे जाने और ship होने के बीच की खाई ही वह जगह है जहां assumptions पुराने पड़ते हैं। Sprint detailing से पहले एक quick market check कोई अतिरिक्त process नहीं है। यह हर उस टिकट के लिए न्यूनतम सावधानी है जो किसी ऐसी चीज को छूता है जो बदलती है।