Je AI is zes maanden geleden gestopt met leren
Het ticket is vorige maand geschreven. De feature gaat volgende maand uit. In de tussentijd heeft een concurrent iets vergelijkbaars uitgebracht, is een API veranderd en is een compliance-eis stilletjes van kracht geworden.

De kloof tussen schrijven en opleveren
Het ticket is vorige maand geschreven. De feature gaat volgende maand uit. In de tussentijd heeft een concurrent iets vergelijkbaars uitgebracht, is een API veranderd en is een nieuwe verplichting stilletjes van kracht geworden. Niets daarvan staat nog in het ticket.
Dit is geen hypothese. Dit is de standup van dinsdag, midden in de sprint. Iemand in het team noemt een API die zich anders gedraagt dan het ticket beschrijft. Iemand anders opent de changelog van een concurrent en ontdekt dat ze drie weken geleden bijna dezelfde feature hebben uitgebracht. Het ticket was prima toen het geschreven werd. De wereld bewoog eenvoudigweg verder voordat het sprint begon.
De schade zit niet alleen in het herwerk. Hij zit in de afbrokkeling van vertrouwen. In het sprintdoel dat stilletjes fictie wordt. In de PM die aan stakeholders moet uitleggen waarom het team iets heeft opgeleverd dat op dag één al verouderd was.
Elk team heeft zijn eigen versie van dit verhaal. De meeste teams vertellen het meer dan eens voordat er echt iets verandert.
AI heeft een kennisgrens
De meeste teams gebruiken inmiddels AI om Jira-tickets te schrijven, plannen en verfijnen. En dat werkt. AI-modellen zijn goed in het structureren van requirements, het genereren van acceptatiecriteria en het voorstellen van implementatiebenaderingen. Wie het bredere kader wil begrijpen waarom vage tickets bijzonder gevaarlijk worden zodra je ze direct aan AI overdraagt, vindt dat uitgewerkt in dit artikel: Waarom de meeste AI-tools voor Jira het alignmentprobleem verergeren in plaats van oplossen.
Wat de meeste teams niet meewegen: de trainingsdata van elk AI-model heeft een afsluitdatum — doorgaans zes tot twaalf maanden voor de huidige datum. Het model weet niet wat er is gebeurd na het einde van zijn training. Het speculeert niet, het is niet voorzichtig. Het kan het simpelweg niet zien.
Dat betekent dat het model niet weet dat Next.js 16.1 in december 2025 de ondersteuning voor Node 18 heeft laten vallen, waardoor builds van teams die op compatibiliteit rekenden stukgingen. Het weet niet dat OpenAI in februari 2026 het chatgpt-4o-latest-endpoint permanent heeft verwijderd, waarmee elke integratie die nog naar die string verwees kapotging. Het weet niet dat drie Amerikaanse staten op 1 januari 2026 uitgebreide privacywetten hebben ingevoerd die de opt-outvereisten van de ene op de andere dag uitbreidden.
De kennisgrens van je AI-assistent ligt ergens rond zes maanden geleden. Wet- en regelgeving wacht niet.
Dit is geen kwaliteitsprobleem van het model — het is structureel. Het model doet zijn werk binnen de grenzen van wat het is getraind. In de kloof tussen die grens en vandaag hopen breaking changes zich op, brengen concurrenten nieuws uit en verschuiven compliance-vereisten. Als je planningsproces die kloof niet meerekent, draagt elk AI-ondersteund ticket een verborgen houdbaarheidsdatum.

Drie gevallen waar dit echt pijn doet
Dit zijn geen abstracte risico's. Dit zijn precies de dingen die in sprintretrospectives belanden onder het label "dat konden we niet voorzien" — terwijl je het absoluut had kunnen voorzien, met vijf minuten onderzoek.
- Breaking changes in afhankelijkheden. Het ticket gaat ervan uit dat een library of API zich nog steeds gedraagt zoals bij de laatste integratie. Het team schrijft het implementatieplan. Midden in de sprint beginnen builds te falen of geven API-aanroepen fouten die niemand verwachtte. Precies dit gebeurde toen OpenAI op 17 februari 2026 de
chatgpt-4o-latest-snapshot verwijderde. Elk team met een ticket dat eind 2025 was ingeschat en nog verwees naar die modelstring liep tegen een muur — het endpoint reageerde simpelweg niet meer. - Concurrenten hebben het al uitgebracht. Niet per se een reden om het ticket te cancelen, maar altijd een reden om eerst te kijken en te leren voordat je bouwt. Als een concurrent dezelfde feature al heeft uitgebracht, heeft hij al edge cases gedocumenteerd, gebruikersfeedback verzameld en is hij soms al tegen muren aangelopen waar jij niet tegenaan hoeft. Vijf minuten concurrentieonderzoek kan twee weken discovery besparen — of de demoralisatie voorkomen van iets opleveren dat de markt al achter zich heeft gelaten.
- Regulatorische en compliance-wijzigingen. Dit is het meest kritieke geval, omdat de gevolgen niet alleen verloren sprints zijn — maar ook juridische blootstelling. Een ticket geschreven in november 2025 voor Amerikaanse gebruikers zou geen rekening houden met privacywetswijzigingen van 1 januari 2026, tenzij iemand dat voor de sprint heeft gecheckt. Toezichthouders openen geen Jira-tickets. Ze wachten niet op jouw sprintcyclus.
Wanneer deze check uitvoeren
Het moment telt meer dan de check zelf.
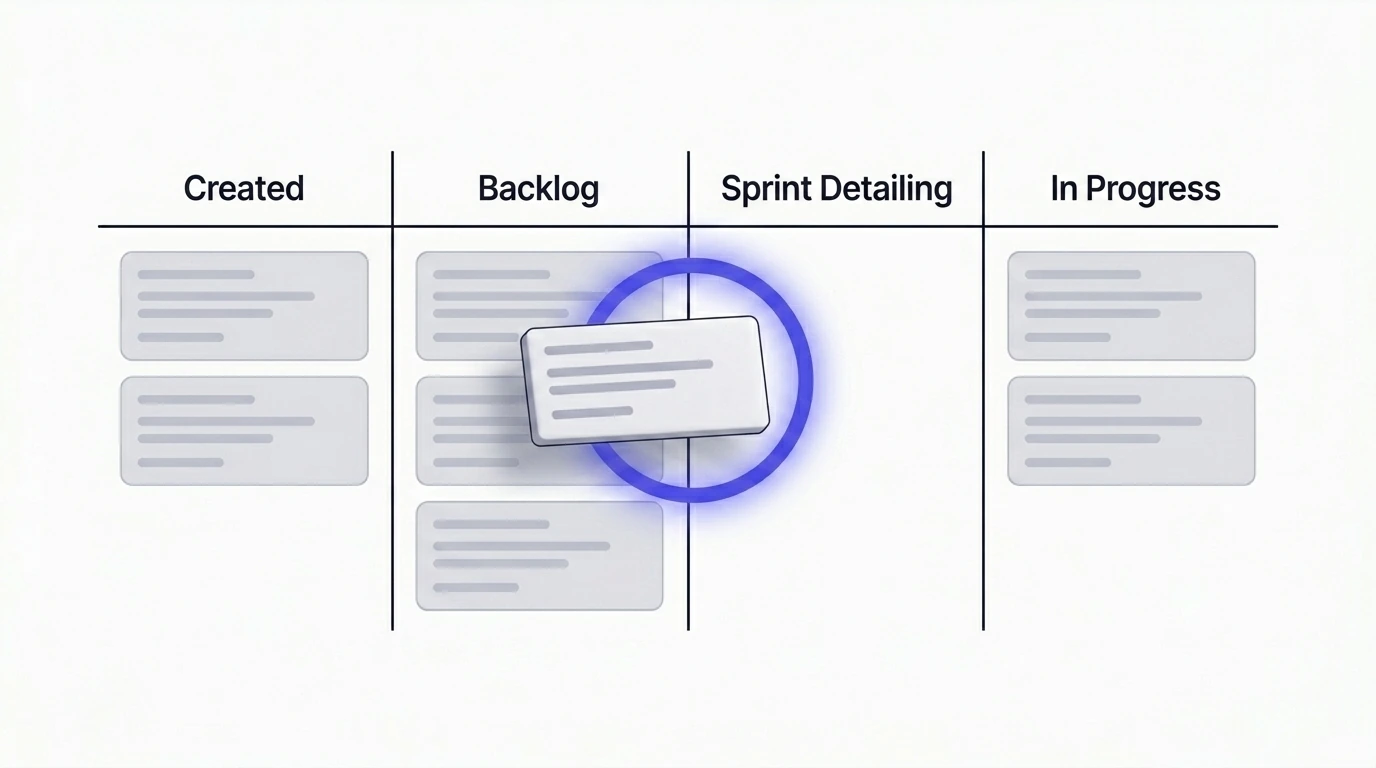
- Niet bij het aanmaken van het ticket. Dat is te vroeg. Het ticket kan weken of maanden in de backlog liggen. Wat je nu checkt, is verouderd tegen de tijd dat iemand het oppakt.
- Niet midden in de sprint. Dat is te laat. Het team heeft al capaciteit vastgelegd. Een breaking change of een compliance-verschuiving nu ontdekken betekent herwerk, geblokkeerde stories en een sprintdoel dat niet meer haalbaar is.
- Wanneer het ticket wordt uitgedetailleerd en ingepland voor de volgende sprint. Dat is het moment waarop het team al echte tijd in het ticket investeert — scope verfijnen, subtasks schrijven, aanpak bevestigen. Een vijf-tot-tien-minuten marktcheck op dit punt toevoegen is goedkoop en levert veel op. Voor de structuur van hoe een ontwikkelklaar ticket er na deze check uit moet zien, is het artikel over implementatieplannen de logische vervolgstap: Vage Jira-tickets omzetten in heldere implementatieplannen.
Wat te checken voordat je het ticket voor de sprint vastlegt:
- Is er iets veranderd in de relevante afhankelijkheid of het platform sinds het ticket werd geschreven?
- Heeft een concurrent dit al uitgebracht, en wat hebben ze daarbij geleerd?
- Zijn er recente regulatorische of compliance-signalen die relevant zijn voor dit functiegebied?
- Zijn er nieuwe tools, patronen of benaderingen die er nog niet waren toen het ticket werd ingeschat?
Deze vier vragen kosten minuten. Ze overslaan kost sprints.
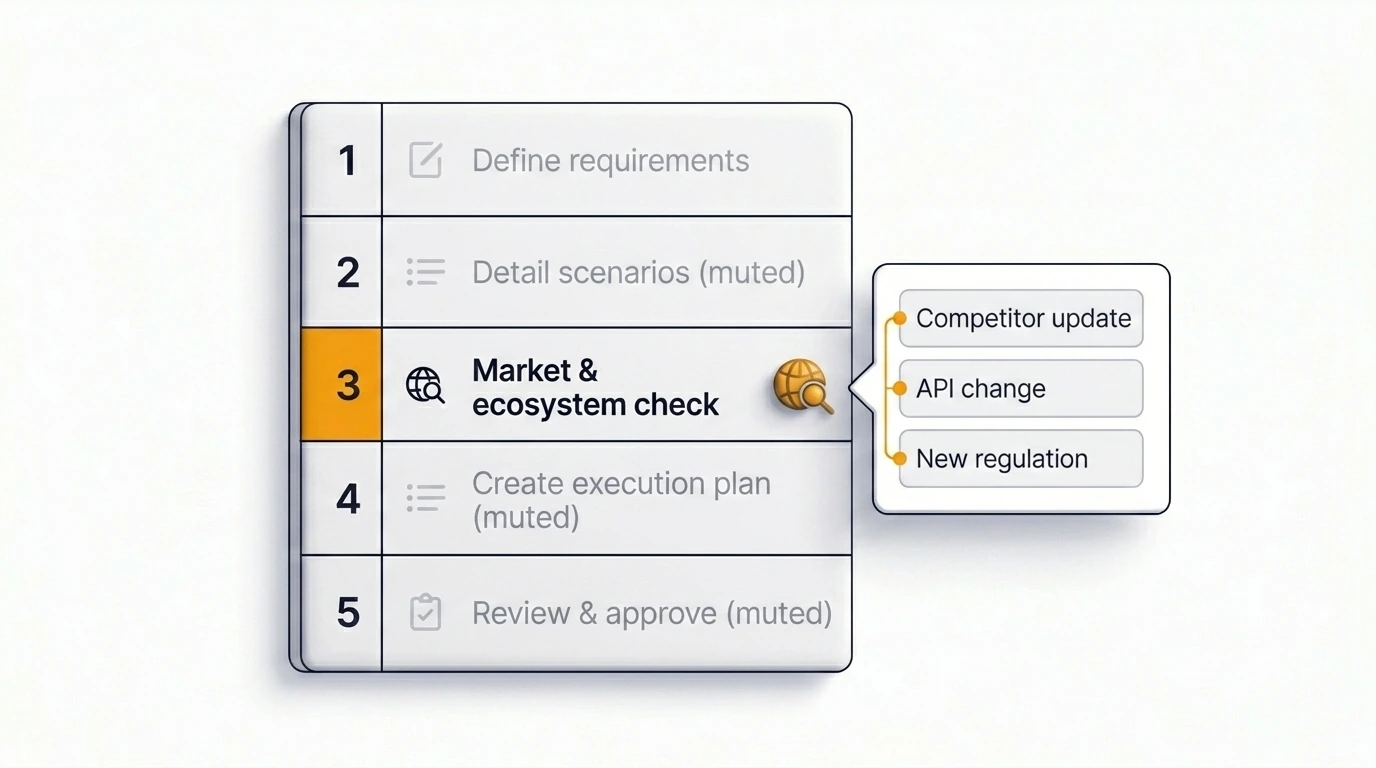
Hoe Just deze stap automatiseert
Het moeilijke is niet weten dat je zou moeten checken. Het moeilijke is de check onderdeel maken van het proces in plaats van iets dat afhankelijk is van de herinnering van één persoon.
Just bevat een webzoekstap direct in de plannings- en insightsflow — niet als standaard voor elk ticket, maar als iets dat het team inschakelt voor tickets waarbij externe context ertoe doet. Als dit is ingeschakeld, haalt Just actuele informatie op die relevant is voor het issue voordat het plan wordt gegenereerd. Recente wijzigingen in afhankelijkheden, patronen bij concurrenten, regulatorische signalen en verschuivingen in het ecosysteem komen zo terecht in de gestructureerde output.
Het resultaat is een plan dat weergeeft wat vandaag werkelijk het geval is, niet wat het geval was toen het model werd getraind. Dit is de meest directe integratie van realtime marktonderzoek in Jira-planning die momenteel beschikbaar is in het Atlassian-ecosysteem.
De check wordt een stap, niet een gewoonte. Stappen overleven teamwisselingen. Gewoontes niet. Wie het product direct wil zien, vindt het op de Just Marketplace-pagina.
Vijf minuten nu, of een sprint later
De markt pauzeert niet terwijl de backlog veroudert. Afhankelijkheden brengen breaking changes. Concurrenten lanceren de feature die jij halverwege aan het bouwen bent. Regelgeving treedt in werking op datums die niets met jouw sprintkalender te maken hebben.
De kloof tussen wanneer een ticket geschreven wordt en wanneer het wordt opgeleverd, is de plek waar aannames stale worden. Een snelle marktcheck voor de sprintdetaillering is geen extra proces. Het is de minimale zorgvuldigheid voor elk ticket dat iets aanraakt dat beweegt.