Tu IA dejó de aprender hace seis meses
El ticket se escribió el mes pasado. La funcionalidad sale el mes que viene. En el medio, un competidor lanzó algo similar, una API cambió, y un requisito de cumplimiento entró silenciosamente en vigor.

La brecha entre escribir y entregar
El ticket se escribió el mes pasado. La funcionalidad sale el mes que viene. En el medio, un competidor lanzó algo parecido, una API cambió, y una nueva obligación regulatoria entró silenciosamente en vigor. Nada de eso quedó reflejado en el ticket.
Esto no es una hipótesis. Es el standup del martes a mitad de sprint. Alguien del equipo menciona una API que ya no se comporta como describe el ticket. Otra persona abre el changelog del competidor y descubre que lanzaron casi la misma funcionalidad hace tres semanas. El ticket era correcto cuando se escribió. El mundo simplemente avanzó antes de que el sprint lo alcanzara.
El coste no está solo en el retrabajo. Está en la erosión de la confianza. En el objetivo de sprint que silenciosamente se vuelve ficticio. En el PM que tiene que explicar a los stakeholders por qué el equipo entregó algo que ya estaba obsoleto desde el primer día.
Cada equipo tiene su versión de esta historia. La mayoría la cuenta más de una vez antes de cambiar algo.
La IA tiene un límite de conocimiento
La mayoría de los equipos ya usan IA para redactar, planificar y refinar tickets de Jira. Y funciona. Los modelos de IA son genuinamente buenos para estructurar requisitos, generar criterios de aceptación y proponer enfoques de implementación. Si quieres el marco más amplio sobre por qué los tickets vagos se vuelven especialmente peligrosos cuando se entregan directamente a la IA, el artículo sobre el problema de alineación lo cubre en detalle: Por qué la mayoría de las herramientas de IA para Jira empeoran el problema de alineación en lugar de resolverlo.
Lo que la mayoría de los equipos no considera es que los datos de entrenamiento de cualquier modelo de IA tienen una fecha de corte — típicamente entre seis y doce meses antes de la fecha actual. El modelo no sabe qué ocurrió después de que terminó su entrenamiento. No está especulando ni siendo cauteloso. Simplemente no puede verlo.
Eso significa que el modelo no sabe que Next.js 16.1 eliminó el soporte para Node 18 en diciembre de 2025, rompiendo las builds de los equipos que asumían compatibilidad. No sabe que OpenAI eliminó permanentemente el endpoint chatgpt-4o-latest en febrero de 2026, destruyendo cualquier integración que aún referenciara ese string. No sabe que tres estados de EE. UU. promulgaron leyes integrales de privacidad el 1 de enero de 2026, ampliando de un día para otro los requisitos de exclusión de datos.
El conocimiento de tu asistente de IA se corta hace aproximadamente seis meses. Las regulaciones no esperan.
Esto no es un problema de calidad del modelo — es estructural. El modelo hace su trabajo dentro de los límites de aquello en lo que fue entrenado. La brecha entre ese límite y el día de hoy es donde se acumulan los cambios disruptivos, donde los competidores lanzan nuevas funcionalidades y donde se desplazan los requisitos de cumplimiento. Si el flujo de planificación no tiene en cuenta esa brecha, cada ticket generado con IA lleva una fecha de caducidad oculta.

Tres casos donde esto duele de verdad
Estos no son riesgos abstractos. Son exactamente el tipo de cosas que aparecen en las retrospectivas del sprint con la etiqueta "no podíamos haberlo predicho" — cuando en realidad sí se podría, con cinco minutos de investigación.
- Breaking changes en dependencias. El ticket asume que una biblioteca o API se comporta igual que cuando alguien la integró por última vez. El equipo escribe el plan de implementación. A mitad de sprint, las builds empiezan a fallar o las llamadas a la API devuelven errores que nadie esperaba. Esto es exactamente lo que pasó cuando OpenAI eliminó el snapshot
chatgpt-4o-latestel 17 de febrero de 2026. Cualquier equipo con un ticket estimado a finales de 2025 que referenciara ese string se topó con una pared — el endpoint simplemente dejó de responder. - Los competidores ya lo han lanzado. No necesariamente es razón para cancelar el ticket, pero siempre es razón para aprender antes de construir. Cuando un competidor ya ha lanzado la misma funcionalidad, ha documentado los casos extremos, ha recogido feedback de usuarios y, a veces, se ha topado con paredes contra las que tú no tienes que chocar. Cinco minutos de investigación competitiva pueden ahorrar dos semanas de discovery — o evitar la desmoralización de entregar algo que el mercado ya ha superado.
- Cambios regulatorios y de cumplimiento. Este es el caso de mayor riesgo, porque las consecuencias no son solo sprints perdidos — son exposición legal. Un ticket escrito en noviembre de 2025 para usuarios de EE. UU. no contemplaría los cambios en las leyes de privacidad del 1 de enero de 2026, a menos que alguien lo verificara antes del sprint. Los reguladores no abren tickets en Jira. No esperan al ciclo de tu sprint.
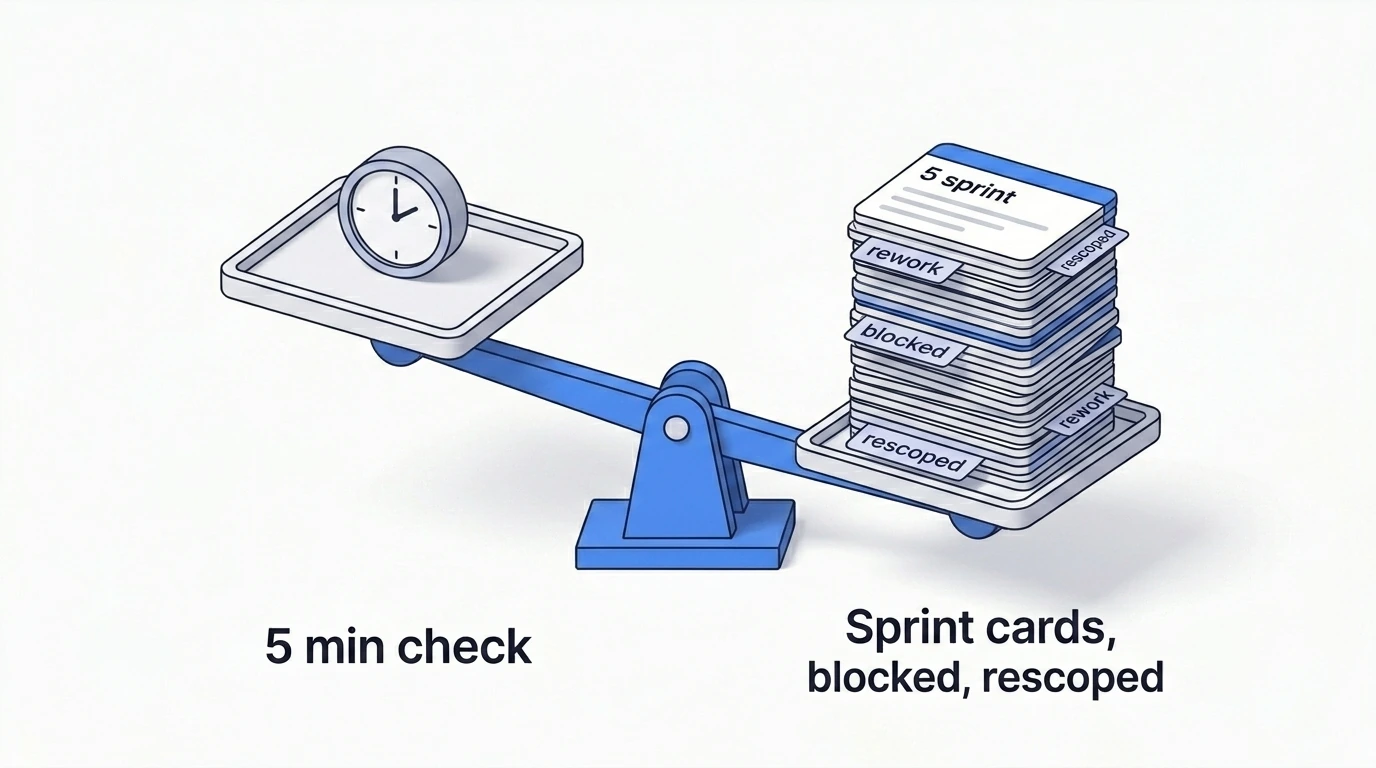
Cuándo hacer esta revisión
El momento importa más que la revisión en sí.
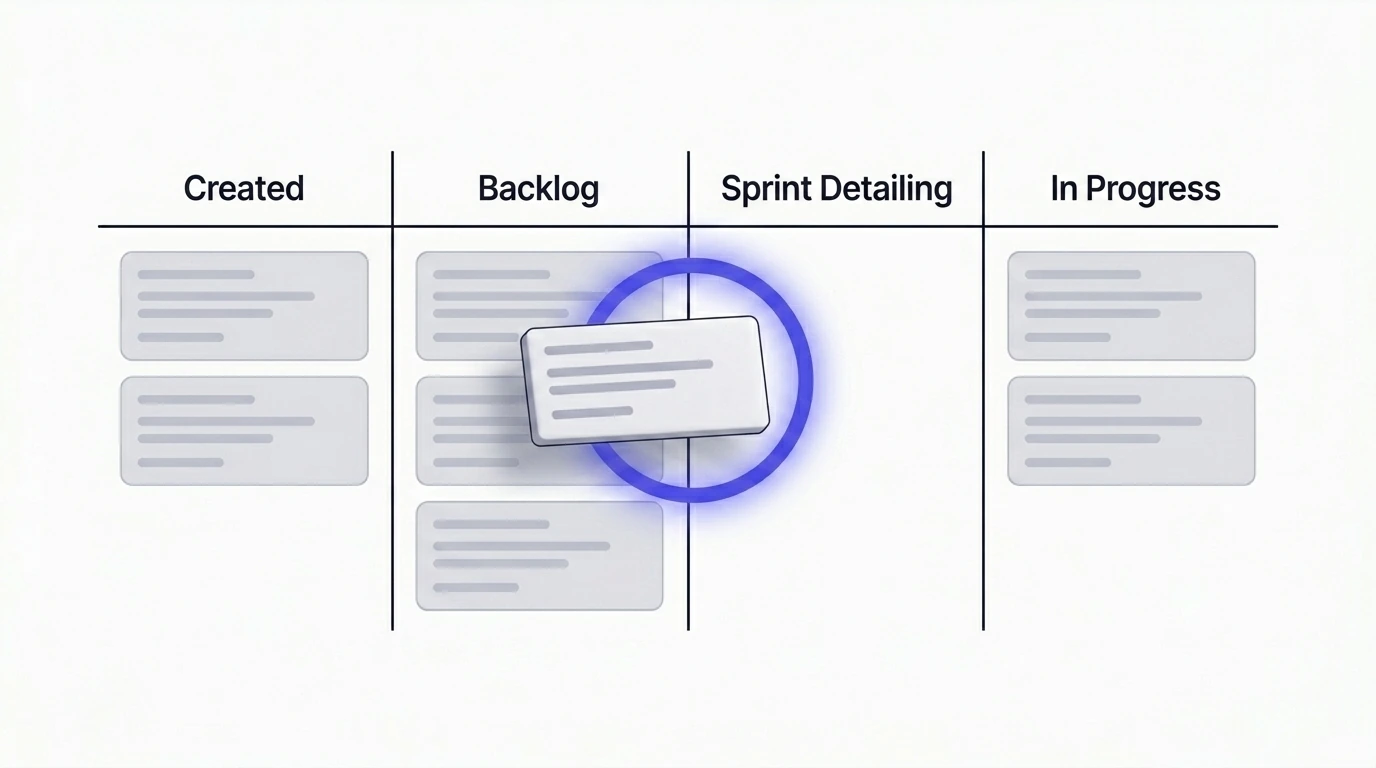
- No cuando se crea el ticket. Es demasiado pronto. El ticket puede quedarse en el backlog durante semanas o meses. Lo que revises ahora estará desactualizado cuando alguien lo coja.
- No a mitad de sprint. Es demasiado tarde. El equipo ya ha comprometido capacidad. Descubrir un breaking change o un cambio regulatorio en este punto significa retrabajo, historias bloqueadas y un objetivo de sprint que ya no es alcanzable.
- Cuando el ticket se está detallando y programando para el próximo sprint. Es entonces cuando el equipo ya invierte tiempo real en el ticket: refinando el alcance, escribiendo subtareas, confirmando el enfoque. Añadir una revisión de mercado de cinco a diez minutos en este punto es de bajo coste y alto retorno. Para la estructura de cómo debería verse un ticket listo para desarrollo tras esta revisión, el artículo sobre planes de implementación es la continuación natural: Convirtiendo tickets vagos de Jira en planes de implementación claros.
Qué revisar antes de comprometer el ticket con el sprint:
- ¿Ha cambiado algo en la dependencia o plataforma relevante desde que se escribió el ticket?
- ¿Ha lanzado algún competidor esto, y qué aprendieron?
- ¿Hay señales regulatorias o de cumplimiento recientes relevantes para esta área de la funcionalidad?
- ¿Hay nuevas herramientas, patrones o enfoques que no existían cuando se estimó el ticket?
Estas cuatro preguntas llevan minutos. Omitirlas cuesta sprints.
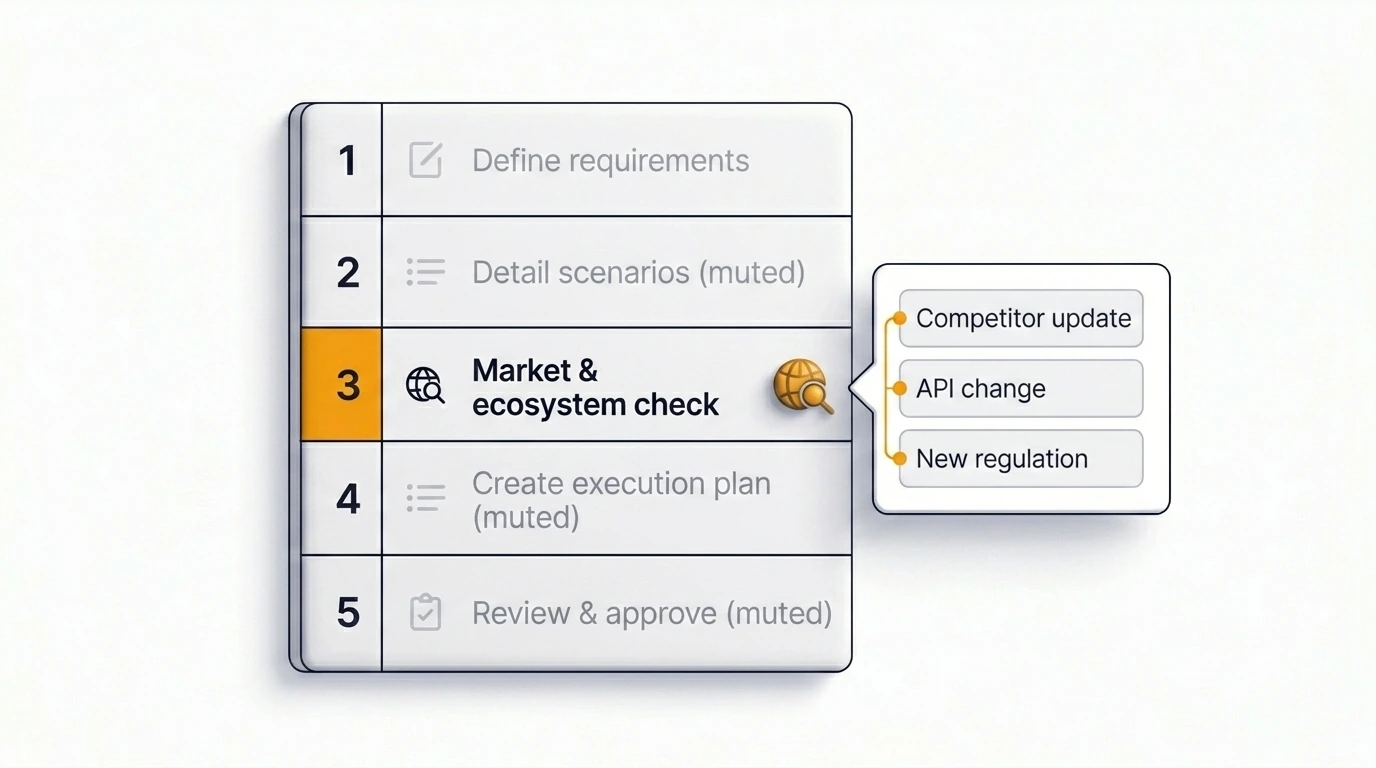
Cómo Just automatiza este paso
Lo difícil no es saber que deberías revisar. Lo difícil es hacer que la revisión sea parte del flujo en lugar de algo que depende de que una persona lo recuerde.
Just incluye un paso de búsqueda web dentro del flujo de planificación e insights — no como predeterminado para cada ticket, sino como algo que el equipo activa para tickets donde el contexto externo importa. Cuando está activado, Just obtiene información actual relevante para el issue antes de generar el plan, presentando cambios recientes en dependencias, patrones de competidores, señales regulatorias y cambios del ecosistema como parte del resultado estructurado.
El resultado es un plan que refleja lo que es verdad hoy, no lo que era verdad cuando se entrenó el modelo. Esta es la integración más directa de investigación de mercado en tiempo real en la planificación de Jira disponible actualmente en el ecosistema de Atlassian.
La revisión se convierte en un paso, no en un hábito. Los pasos sobreviven los cambios de equipo. Los hábitos no. Si quieres ver el producto directamente, está en la página de Just en el Marketplace.
Cinco minutos ahora, o un sprint después
El mercado no hace pausa mientras el backlog envejece. Las dependencias lanzan breaking changes. Los competidores lanzan la funcionalidad que tú estás a mitad de construir. Las regulaciones entran en vigor en fechas que no tienen nada que ver con tu calendario de sprints.
La brecha entre cuando se escribe un ticket y cuando se entrega es donde los supuestos se quedan obsoletos. Una revisión rápida del mercado antes del detallado del sprint no es proceso extra. Es la diligencia mínima para cualquier ticket que toque algo que cambia.